从斐波那契数列看java方法的调用过程

先看斐波那契数列的定义:
斐波那契数列(Fibonacci sequence),又称递归的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=2,n∈N*)
翻译成java代码是:
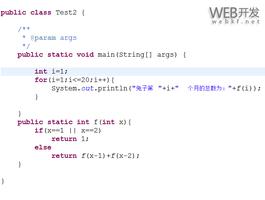
public int Fibonacci(int n) { if (n == 1 || n == 2) {
return 1;
}
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
代码很简单,简单的递归,就不解释了。
但是这个方法在实际执行的过程中有可能出现java.lang.StackOverflowError错误,这个错误是什么意思呢,jdk官方文档是这么解释的:应用程序递归太深而发生堆栈溢出时,抛出该错误。
JAVA程序运行时,会在内存中划分5片空间进行数据的存储。分别是:1:寄存器。2:本地方法区。3:方法区。4:栈。5:堆。我们上面说的“堆栈”就是指栈了,java栈中主要存储基本数据类型的值和对象的引用。那么在上面这个递归执行的过程中发生了什么呢?
我们先分析一下这个数列的公式:
F(n)=F(n-1)+F(n-2)
=(F(n-2)+F(n-3))+(F(n-3)+F(n-4))
=F(n-3)+F(n-4)+F(n-4)+F(n-5)+F(n-4)+F(n-5)+F(n-5)+F(n-6)
……
观察可以发现,这个方法在执行的过程中每多增加一层递归需要存储临时参数的栈空间就是上一层的两倍,而在最终递归结束前,每一层的方法参数n的值都不会被释放(出栈),所以栈的深度将会以O(2^n)的空间复杂度越压越深,最终达到最大深度导致栈溢出。
毫无疑问,对实现一个斐波那契数列来说,这个实现空间复杂度O(2^n)太大了,而实际上每一层方法传入的参数值n在成功传到下一层的时候就没用了,但是却一直不能出栈,导致了栈空间的浪费。
所以要优化这个算法,我们就只能让每层方法结束后及时出栈,也就是别用递归。不用递归用什么呢?很多时候,递归的功能可以通过循环来实现,循环内部的代码可以看作是一个方法的方法体,与递归不同的地方是循环代码没有返回值,但我们可以通过在循环内部更改外部变量的值来实现类似于返回值的效果。
有公式 F(n)=F(n-1)+F(n-2),且已知F(1)=1和F(2)=1,F(3)=1+1=2,F(4)=F(3)+F(2)=2+1=3,利用这个思路,我们可以得到如下的代码:
public int Fibonacci(int n) { int l = 1, j = 1, k = 1;
for (int i = 3; i <= n; i++) {
k = l + j;
l = j;
j = k;
}
return n == 0 ? 0 : k;
}
解释一下:l 和 j 一开始分别为F(1)和F(2)的值,循环从n>2时开始(小于等于2直接返回k的初始值),每循环一层,k的值变为前两项 l 和 j 的和,然后更新 l 和 j 的值供下次循环使用。
改良后的算法最大的特点就是栈深度只有一层,没有无用的变量值浪费空间,空间复杂度达到了最优。
以上是 从斐波那契数列看java方法的调用过程 的全部内容, 来源链接: utcz.com/z/392379.html