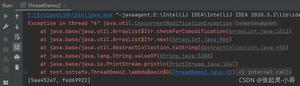
深入理解java集合框架之---------HashTable集合

HashTable是什么
- HashTable是基于哈希表的Map接口的同步实现
- HashTable中元素的key是唯一的,value值可重复
- HashTable中元素的key和value不允许为null,如果遇到null,则返回NullPointerException
- HashTable中的元素是无序的
public class Hashtable<K,V>extends Dictionary<K,V>
implements Map<K,V>, Cloneable, java.io.Serializable{}
HashTable跟HashMap一样,同样是链表散列的数据结构,从源码中我们可以看出,Hashtable 继承于Dictionary类,实现了Map, Cloneable,Serializable接口
- Dictionary类是任何可将键映射到相应值的类的抽象父类,每个键和值都是对象
- Dictionary源码注释指出 Dictionary 这个类过时了,新的实现类应该实现Map接口
Hashtable成员变量
- table:一个Entry[]数组类型,而Entry(在 HashMap 中有讲解过)就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的
- count:Hashtable的大小,它是Hashtable保存的键值对的数量
- threshold:Hashtable的阈值,用于判断是否需要调整Hashtable的容量,threshold的值 = (容量 * 负载因子)
- loadFactor:负载因子
- modCount:用来实现fail-fast机制的
Hashtable构造方法
Hashtable 一共提供了 4 个构造方法
- public Hashtable(int initialCapacity, float loadFactor): 用指定初始容量和指定加载因子构造一个新的空哈希表
- public Hashtable(int initialCapacity):用指定初始容量和默认的加载因子 (0.75) 构造一个新的空哈希表
- public Hashtable():默认构造函数,容量为 11,加载因子为 0.75
- public Hashtable(Map< ? extends K, ? extends V> t):构造一个与给定的Map具有相同映射关系的新哈希表
public synchronized V put(K key, V value) { //确保value不为null
if (value == null) {
throw new NullPointerException();
}
//确保key不在hashtable中
//首先,通过hash方法计算key的哈希值,并计算得出index值,确定其在table[]中的位置
//其次,迭代index索引位置的链表,如果该位置处的链表存在相同的key,则替换value,返回旧的value
Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
V old = e.value;
e.value = value;
return old;
}
}
modCount++;
if (count >= threshold) {
//如果超过阀值,就进行rehash操作
rehash();
tab = table;
hash = hash(key);
index = (hash & 0x7FFFFFFF) % tab.length;
}
//将值插入,返回的为null
Entry<K,V> e = tab[index];
// 创建新的Entry节点,并将新的Entry插入Hashtable的index位置,并设置e为新的Entry的下一个元素
tab[index] = new Entry<>(hash, key, value, e);
count++;
return null;
}
存储的流程如下:
- 判断value是否为空,为空则抛出异常
- 计算key的hash值,并根据hash值获得key在table数组中的位置index
如果table[index]元素为空,将元素插入到table[index]位置
如果table[index]元素不为空,则进行遍历链表,如果遇到相同的key,则新的value替代旧的value,并返回旧 value,否则将元素插入到链头,返回null
Hashtable的获取
public synchronized V get(Object key) { Entry tab[] = table;
int hash = hash(key);
int index = (hash & 0x7FFFFFFF) % tab.length;
for (Entry<K,V> e = tab[index] ; e != null ; e = e.next) {
if ((e.hash == hash) && e.key.equals(key)) {
return e.value;
}
}
return null;
}
获取的流程如下:
1、通过 hash()方法求得key的哈希值
2、根据hash值得到index索引
3、迭代链表,返回匹配的key的对应的value,找不到则返回null
Hashtable遍历方式
Hashtable有4种遍历方式:
//1、使用keys()Enumeration<String> en1 = table.keys();
while(en1.hasMoreElements()) {
en1.nextElement();
}
//2、使用elements()
Enumeration<String> en2 = table.elements();
while(en2.hasMoreElements()) {
en2.nextElement();
}
//3、使用keySet()
Iterator<String> it1 = table.keySet().iterator();
while(it1.hasNext()) {
it1.next();
}
//4、使用entrySet()
Iterator<Entry<String, String>> it2 = table.entrySet().iterator();
while(it2.hasNext()) {
it2.next();
}
Hashtable与HashMap的区别
| Hashtable | HashMap |
|---|---|
| 方法是同步的 | 方法是非同步的 |
| 基于Dictionary类 | 基于AbstractMap,而AbstractMap基于Map接口的实现 |
| key和value都不允许为null,遇到null,直接返回 NullPointerException | key和value都允许为null,遇到key为null的时候,调用putForNullKey方法进行处理,而对value没有处理 |
| hash数组默认大小是11,扩充方式是old*2+1 | hash数组的默认大小是16,而且一定是2的指数 |
多线程存在的问题
1、如果涉及到多线程同步时,建议采用HashTable
2、没有涉及到多线程同步时,建议采用HashMap
3、Collections 类中存在一个静态方法:synchronizedMap(),该方法创建了一个线程安全的 Map 对象,并把它作为一个封装的对象来返回
synchronizedMap()其实就是对Map的方法加层同步锁,从源码中可以看出
//Collections.synchronizedMap(Map<K, V>)public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<K,V>(m);
}
private static class SynchronizedMap<K,V> implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
//同步锁
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
if (m==null)
throw new NullPointerException();
this.m = m;
//把this本身作为锁监视器, 这样任何线程访问他的方法都要获取该监视器.
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized(mutex) {return m.size();}
}
//重写map的emty方法
public boolean isEmpty() {
synchronized(mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized(mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized(mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized(mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized(mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized(mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized(mutex) {m.putAll(map);}
}
public void clear() {
synchronized(mutex) {m.clear();}
}
private transient Set<K> keySet = null;
private transient Set<Map.Entry<K,V>> entrySet = null;
private transient Collection<V> values = null;
//重写keySet方法
public Set<K> keySet() {
synchronized(mutex) {
if (keySet==null)
//mutex传给SynchronizedSet, 这样对于set内部操作也需要获取锁.
keySet = new SynchronizedSet<K>(m.keySet(), mutex);
return keySet;
}
}
public Set<Map.Entry<K,V>> entrySet() {
synchronized(mutex) {
if (entrySet==null)
entrySet = new SynchronizedSet<Map.Entry<K,V>>(m.entrySet(), mutex);
return entrySet;
}
}
public Collection<V> values() {
synchronized(mutex) {
if (values==null)
values = new SynchronizedCollection<V>(m.values(), mutex);
return values;
}
}
public boolean equals(Object o) {
synchronized(mutex) {return m.equals(o);}
}
public int hashCode() {
synchronized(mutex) {return m.hashCode();}
}
public String toString() {
synchronized(mutex) {return m.toString();}
}
private void writeObject(ObjectOutputStream s) throws IOException {
synchronized(mutex) {s.defaultWriteObject();}
}
}
以上是 深入理解java集合框架之---------HashTable集合 的全部内容, 来源链接: utcz.com/z/392289.html