Java爬虫:用java爬取小说 - 千锋JAVA开发陈老师

Java爬虫:用java爬取小说
Java也能做爬虫。
现在提到爬虫人第一个想到的就是python,其实使用Java编写爬虫也是很好的选择,
下面给大家展示一个使用Java基础语言编写的爬取小说的案例:
实现功能:
爬取目标网站全本小说
代码编写环境
JDK:1.8.0_191
Eclipse:2019-03 (4.11.0)
素材:
网站:http://www.shicimingju.com
小说:三国演义
案例实现用到的技术:
正则表达式
Java网络通信:URL
IO流
Map—HashMap
字符串操作
异常处理
代码思路
根据小说存放位置创建file对象
根据网页结构编写正则,创建pattern对象
编写循环,创建向所有小说章节页面发起网络请求的url对象
网络流BufferReader
创建输入流
循环读取请求得到的内容,使用正则匹配其中的内容
将读取到的内容写入本地文件,知道循环结束
注意代码中的异常处理
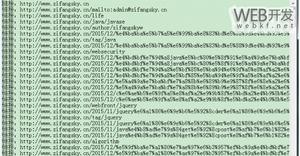
运行效果
第117章开始下载。。。。。。。。。。。。。。。。。
邓士载偷度阴平 诸葛瞻战死绵竹_《三国演义》_诗词名句网
第117章结束下载。。。。。。。。。。。。。。。。。
第118章开始下载。。。。。。。。。。。。。。。。。
哭祖庙一王死孝 入西川二士争功_《三国演义》_诗词名句网
第118章结束下载。。。。。。。。。。。。。。。。。
第119章开始下载。。。。。。。。。。。。。。。。。
假投降巧计成虚话 再受禅依样画葫芦_《三国演义》_诗词名句网
第119章结束下载。。。。。。。。。。。。。。。。。
第120章开始下载。。。。。。。。。。。。。。。。。
荐杜预老将献新谋 降孙皓三分归一统_《三国演义》_诗词名句网
第120章结束下载。。。。。。。。。。。。。。。。。
案例代码:
package com.qianfeng.text;
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileOutputStream;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class GetText {
/**
* 1、根据小说存放位置创建file对象
2、根据网页结构编写正则,创建pattern对象
3、编写循环,创建向所有小说章节页面发起网络请求的url对象
4、网络流BufferReader
5、创建输入流
6、循环读取请求得到的内容,使用正则匹配其中的内容
7、将读取到的内容写入本地文件,知道循环结束
8、注意代码中的异常处理
* @param args
*/
public static void main(String[] args) {
// 1、根据小说存放位置创建file对象
File file = new File("D:\\File\\three_guo.txt");
// 2、根据网页结构编写正则,创建pattern对象
String regex_content = "<p.*?>(.*?)</p>";
String regex_title = "<title>(.*?)</title>";
Pattern p_content = Pattern.compile(regex_content);
Pattern p_title = Pattern.compile(regex_title);
Matcher m_content;
Matcher m_title;
// 3、编写循环,创建向所有小说章节页面发起网络请求的url对象
for (int i = 1; i <= 120; i++) {
System.out.println("第" + i + "章开始下载。。。");
try {
// 创建每一个页面的url对象
URL url = new URL("http://www.shicimingju.com/book/sanguoyanyi/" + i + ".html");
// 创建网络读取流
BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream(),"utf8"));
// 4、读取网络内容网络流BufferReader
String str = null;
// 5、创建输入流
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file,true)));
while ((str = reader.readLine()) != null) {
m_title = p_title.matcher(str.toString());
m_content = p_content.matcher(str.toString());
// 获取小说标题并写入本地文件
Boolean isEx = m_title.find();
if (isEx) {
String title = m_title.group();
// 清洗得到的数据
title = title.replace("<title>", "").replace("</title>", "");
System.out.println(title);
writer.write("第" + i + "章:" + title + "\n");
}
while (m_content.find()) {
String content = m_content.group();
// 清洗得到的数据
content = content.replace("<p>", "").replace("</p>", "").replace(" ", "").replace("?", "");
// 把小说内容写入文件
writer.write(content + "\n");
}
}
System.out.println("第" + i + "章下载完成.........");
writer.write("\n\n");
writer.close();
reader.close();
} catch (Exception e) {
System.out.println("下载失败");
e.printStackTrace();
}
}
}
}
发表于
2019-06-20 16:23
千锋JAVA开发陈老师
阅读(2125)
评论(1)
编辑
收藏
举报
以上是 Java爬虫:用java爬取小说 - 千锋JAVA开发陈老师 的全部内容, 来源链接: utcz.com/z/392189.html