Java JDK1.8源码学习之路 2 String

写在最前
String 作为我们最常使用的一个Java类,注意,它是一个引用类型,不是基本类型,并且是一个不可变对象,一旦定义 不再改变
经常会定义一段代码:
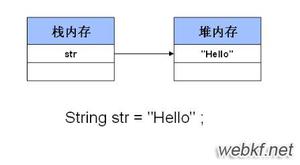
String temp = "Hello";
这里具体的含义是:定义了一个类型为String的引用类型变量 temp 指向 “Hello” 这个存在内存当中的对象。
这里列举一些面试中常见的问题,简单但也很容易绕进去
String a = "hello";String b = "hello";
System.out.println(a.hashCode());//99162322
System.out.println(b.hashCode());//99162322
System.out.println(a==b);//true
这里用 == 比较两个相同的字符串时候,会返回true,原因是 JAVA会把两个内容相同的字符串看作是同一个对象,具有相同的哈希值;
new 一定会产生新对象,分配新的内存地址
String a = "hello";String b = new String("hello");
System.out.println(a.hashCode());//99162322
System.out.println(b.hashCode());//99162322
System.out.println(a==b);//false
得出: == 双目运算符比较的是内存地址,new 产生了一个新的对象,有不同的内存地址
equals 方法与 == 运算符的比较 以及 + 运算符
String a = "hello";
String b = "word";
String c = "helloword";
String d = "hello"+"word";
System.out.println(c == a+b);//false
System.out.println(c == "hello"+"word");//true
System.out.println(c == d);//true
字符串如果是变量相加,先开空间,在拼接
如果是常量相加,是先加,然后在常量池找,如果有就直接返回,否则,就创建。
a+b 先进行开辟内存,在进行拼接,所以他们的内存地址肯定不相同
"hello"+"word" 常量相加,拼接后发现在常量池存在,则直接返回的就是c的内存地址,所以返回true
结论:引用类型使用 == 比较时候,比较的是内存地址,而equals 方法比较的是对象的值,在String 对象里面,会对两个字符串的每个字符进行一一比较,而平时我们创建的对象默认实现的是
Object 类的equals 方法,Object 类的equals方法默认使用的是 ==比较,所以比较的是内存地址。所以我们在比较自己创建的对象时候,要重写equals方法。
开始分析常用源码
构造器部分
public final class Stringimplements java.io.Serializable, Comparable<String>, CharSequence {
//定义了一个存放字符串字符的数组
private final char value[];
//字符串本身的哈希值
private int hash; // Default to 0
//理解为 是一个序列化的ID
private static final long serialVersionUID = -6849794470754667710L;
//io包下面 实例化出一个长度为1的串行化字段的类
private static final ObjectStreamField[] serialPersistentFields =
new ObjectStreamField[0];
//构造一个空的字符串 这个空说的是""
public String() {
this.value = "".value;
}
//传入一个字符串进行构造,
public String(String original) {
this.value = original.value;
this.hash = original.hash;
}
//将传入一个字符数组,通过数组复制的方式,将字符数组的值复制到value字符数组
public String(char value[]) {
this.value = Arrays.copyOf(value, value.length);
}
}
传入一个StringBuffer进行构造一个字符串对象,通过复制字符序列进行构造,并且在构造的过程中加入同步锁
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
常用方法分析
length() 字符串长度方法
public int length() { return value.length;
}
isEmpty() 判断是否为空
public boolean isEmpty() { return value.length == 0;
}
CharAt(int index) 取出指定位置的字符,若下标小于零或者超出长度,则会抛出异常
public char charAt(int index) { if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return value[index];
}
codePointAt 取出指定下标位置字符的Unicode值 Unicode详见文章后部
public int codePointAt(int index) { if ((index < 0) || (index >= value.length)) {
throw new StringIndexOutOfBoundsException(index);
}
return Character.codePointAtImpl(value, index, value.length);
}
getChars 复制字符串的字符数组到一个新的字符数组dst, 复制到dst数组dstBegin位置
void getChars(char dst[], int dstBegin) { System.arraycopy(value, 0, dst, dstBegin, value.length);
}
getBytes 将这个字符串通过指定的编码名称编码后,返回字节数组
public byte[] getBytes(String charsetName)throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
return StringCoding.encode(charsetName, value, 0, value.length);
}
equals 方法,最常用的方法之一 判断两个字符串是否相等
public boolean equals(Object anObject) {
// == 判断内存地址是否相等,相等则返回true if (this == anObject) {
return true;
}
//传入的对象是否是String类型的子类
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
//长度相等在开始判断相等,不相等的长度直接返回false
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
//循环判断每一个字符,只要一个不相等则false
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
compareTo(String another) 字典顺序比较两个字符串,相等则返回0
a.compareTo(b) a>b 返回负整数 反之则是正整数
public int compareTo(String anotherString) { int len1 = value.length;
int len2 = anotherString.value.length;
int lim = Math.min(len1, len2);
char v1[] = value;
char v2[] = anotherString.value;
int k = 0;
while (k < lim) {
char c1 = v1[k];
char c2 = v2[k];
if (c1 != c2) {
return c1 - c2;
}
k++;
}
return len1 - len2;
}
regionMatches(int toffset, String other, int ooffset,int len)
other字符串是否是源字符串的子串,比较位置从源字符串的toffset位置开始,other字符串的ooffset位置开始,比较的长度是len
public boolean regionMatches(int toffset, String other, int ooffset,int len) {
char ta[] = value;
int to = toffset;
char pa[] = other.value;
int po = ooffset;
// Note: toffset, ooffset, or len might be near -1>>>1.
if ((ooffset < 0) || (toffset < 0)
|| (toffset > (long)value.length - len)
|| (ooffset > (long)other.value.length - len)) {
return false;
}
while (len-- > 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
startsWith(String prefix, int toffset) 源字符串的toffset位置是否包含prefix字符串
public boolean startsWith(String prefix, int toffset) { char ta[] = value;
int to = toffset;
char pa[] = prefix.value;
int po = 0;
int pc = prefix.value.length;
// Note: toffset might be near -1>>>1.
if ((toffset < 0) || (toffset > value.length - pc)) {
return false;
}
while (--pc >= 0) {
if (ta[to++] != pa[po++]) {
return false;
}
}
return true;
}
indexOf(int ch,int index) 方法 从字符串的formIndex开始索引,找出首次出现ch(Unicode 值)的位置,
public int indexOf(int ch, int fromIndex) { final int max = value.length;
if (fromIndex < 0) {
fromIndex = 0;
} else if (fromIndex >= max) {
// Note: fromIndex might be near -1>>>1.
return -1;
}
if (ch < Character.MIN_SUPPLEMENTARY_CODE_POINT) {
// handle most cases here (ch is a BMP code point or a
// negative value (invalid code point))
final char[] value = this.value;
for (int i = fromIndex; i < max; i++) {
if (value[i] == ch) {
return i;
}
}
return -1;
} else {
return indexOfSupplementary(ch, fromIndex);
}
}
indexOf:被搜索的字符序列target, 源字符序列source ,从源字符序列的sourceOffset开始,源字符序列的长度sourceCount
formIndex表示从源字符序列的那个位置开始搜索
static int indexOf(char[] source, int sourceOffset, int sourceCount,char[] target, int targetOffset, int targetCount,
int fromIndex) {
//搜索开始的位置大于等于源字符串的长度if (fromIndex >= sourceCount) {
//如果被搜索字符的长度==0 就是空字符串 就返回源字符串的长度,否则就直接返回-1搜索不到return (targetCount == 0 ? sourceCount : -1);
}
//对开始位置若小于零则归零if (fromIndex < 0) {
fromIndex = 0;
}
//被搜索字符序列长度为0,直接返回搜索开始的位置if (targetCount == 0) {
return fromIndex;
}
//首个比较的字符,从target偏移位置开始char first = target[targetOffset];
// 搜索的最后一个位置int max = sourceOffset + (sourceCount - targetCount);
//从偏移位置+开始搜索的位置开始搜索 搜索次数 maxfor (int i = sourceOffset + fromIndex; i <= max; i++) {
/* Look for first character. */
if (source[i] != first) {
while (++i <= max && source[i] != first);
}
/* Found first character, now look at the rest of v2 */
if (i <= max) {
int j = i + 1;
int end = j + targetCount - 1;
for (int k = targetOffset + 1; j < end && source[j]
== target[k]; j++, k++);
if (j == end) {
/* Found whole string. */
return i - sourceOffset;
}
}
}
return -1;
}
substring 返回一个子字符串,从beginIndex下标开始,到结束
这里如果下标取0则返回的是字符串本身,否则就新new一个
public String substring(int beginIndex) { if (beginIndex < 0) {
throw new StringIndexOutOfBoundsException(beginIndex);
}
int subLen = value.length - beginIndex;
if (subLen < 0) {
throw new StringIndexOutOfBoundsException(subLen);
}
return (beginIndex == 0) ? this : new String(value, beginIndex, subLen);
}
concat 拼接两个字符串
public String concat(String str) { int otherLen = str.length();
if (otherLen == 0) {
return this;
}
int len = value.length;
//复制出一个数组,将源字符串填充,
char buf[] = Arrays.copyOf(value, len + otherLen);
//将新的str填充
str.getChars(buf, len);
//产生一个新的String对象
return new String(buf, true);
}
replace 将源字符串中的指定字符替换为新的字符
public String replace(char oldChar, char newChar) {
//内存地址相等则直接返回 if (oldChar != newChar) {
int len = value.length;
int i = -1;
char[] val = value; /* avoid getfield opcode */
//找出具体旧的字符所在的第一个位置
while (++i < len) {
if (val[i] == oldChar) {
break;
}
}
//找到旧的字符则继续 因为i<len
if (i < len) {
char buf[] = new char[len];
//复制数组到 buf里面
for (int j = 0; j < i; j++) {
buf[j] = val[j];
}
//开始替换
while (i < len) {
char c = val[i];
buf[i] = (c == oldChar) ? newChar : c;
i++;
}
return new String(buf, true);
}
}
return this;
}
UniCode 万国码简介
Unicode 万国码,又叫做统一码,是计算机的一项业界标准,他为每种语言中的字符设定了统一的
并且是唯一的二进制码,满足文本的转换,处理。
UTF-8
计算机里面最常见的一种编码格式,它的基本单位是字节,UTF-8最大长度是4个字节。我们使用的汉字,每一个汉字占用三个字节来表示
UTF-8的特点是对不同范围的字符使用不同长度的编码。对于0x00-0x7F之间的字符,UTF-8编码与ASCII编码完全相同。
意思就是说平时使用到的英文字母以及常用半角符号。来自于键盘上的符号都是由ASCII 在Unicode里面使用一个字节去表示。
举个例子
这里打印出小写h所对应的万国码 用整数表示出就是104
String a = "hello";System.out.println(a.codePointAt(0));//104
我们查阅ASCII表
果然一个字节表示的字符与ASCII码表是对应的
以上是 Java JDK1.8源码学习之路 2 String 的全部内容, 来源链接: utcz.com/z/391865.html