Java Collection

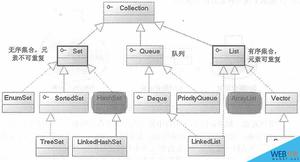
1. Collection 接口
// Collection 接口在其源码中的定义:* 1. Collection 是集合层次结构中的根接口
* 2. 一个 Collection 代表 一组对象(objects),这些对象称为其元素(elements)
* 3. 一些 Collection 允许有重复的元素,而另一些 Collection 不允许有重复的元素
* 4. 一些 Collection 的元素是有序的,而另一些 Collection 是无序的
* 5. JDK 没有提供任何直接(direct)实现 Collection 的类
* 6. JDK 只提供了继承 Collection 的“子接口”(List 和 Set)的实现类
* -Set 中的元素没有顺序且不可以重复
* -List 中的元素有顺序且可以重复
* -Map 接口定义了存储 “键(key)- 值(value)映射对” 的方法,键(key)不能重复,重写 hashCode() 和 equals() 方法!
*
* * 接口 Collection
* / \
* * 接口 Set List Map
* | / \ |
* * 类 HashSet ArrayList LinkedList HashMap
// 谈到 Collection 接口,我们不得不区别一下 Collections 类
// Collections 是一个类,不能实例化,是一个工具类,它包含各种有关集合操作的静态(static)多态方法,比如 sort、search、shuffle 以及线程安全等操作
public class Collections {
// 私有化构造器,所以不能被实例化
private Collections() {
}
...
}
2. ArrayList
1. ArrayList 是 List 接口的实现类,并继承于 AbstractList(AbstractList 继承于 AbstractCollection,并且实现了大部分 List 接口)2. ArrayList 的底层实现是动态数组(属于数据结构中的可扩容的线性表),线程不安全,效率高
// 创建
List list = new ArrayList();
// 常用方法
list.size();// 返回元素的数量
list.isEmpty();
list.add(element);
list.add(index, element);// 在指定位置添加元素
list.remove(index);// 删除指定索引的元素,并返回该元素内容
list.remove(element);// 删除指定元素,删除成功返回 true
list.get(index);// 获取指定位置的元素
list.toArray();// 返回一个包含列表中的所有元素的数组
list.contains(element);// 判断是否包含指定元素
list.indexOf(element);// 返回指定元素所在的第一个位置,没找到返回 -1
list.lastIndexOf(element);// 返回指定元素所在的最后一个位置
list.clear();// 删除所有元素
// 为了更深入了解 ArrayList,我们来分析一下 ArrayList 的部分源码
public class ArrayList<E> extends AbstractList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final int DEFAULT_CAPACITY = 10;// 默认容量为 10
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;// 最大容量
private static final Object[] EMPTY_ELEMENTDATA = {};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
transient Object[] elementData;// 可见底层是 Object 对象数组
private int size;// 包含元素的数量
// 无参构造器,对象数组默认为空
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// 有参构造器,用于初始化数组容量
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
}
}
// 返回所包含元素的数量
public int size() {
return size;
}
// 判断对象数组是否为空
public boolean isEmpty() {
return size == 0;
}
// 返回一个包含列表中的所有元素的数组
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
// 删除元素
public E remove(int index) {
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null;
return oldValue;
}
// 添加元素
public boolean add(E e) {
ensureCapacityInternal(size + 1);// 判断是否需要扩容
elementData[size++] = e;
return true;
}
// 判断是否需要扩容
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 扩容方法
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0)
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
...
}
ArrayList
3. LinkedList
1. LinkedList 是 List 接口的实现类,并继承于 AbstractSequentialList(AbstractSequentialList 继承于 AbstractList,提供了对数据元素的链式访问而不是随机访问)2. LinkedList 的底层实现是链表(属于数据结构中的双向链表),线程不安全,效率高
// 创建
List link = new LinkedList();
// 常用方法
link.size();
link.getFirst();// 返回第一个节点的元素
link.getLast();// 返回最后一个节点的元素
link.get(index);// 返回指定位置的元素
link.contain(element);// 判断链表中是否有指定元素
link.addFirst(element);// 从链表头部插入元素,无返回值
link.add(element); // 从链表尾部插入元素,插入成功返回 true
link.add(index, element);// 在指定位置插入元素,无返回值
link.remove(element); // 删除指定元素,删除成功返回 true
link.remove(index);// 删除指定位置的元素,删除成功返回被删除元素
link.addAll(Collection);// 添加指定集合
link.clear();// 清空链表,释放节点空间
// 为了更深入了解 LinkedList,我们来分析一下 LinkedList 的部分源码
public class LinkedList<E>extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
{
// 用私有静态内部类定义链表的节点对象
private static class Node<E> {
E item; // 存放元素内容
Node<E> next;// 指向下一个节点
Node<E> prev;// 指向前一个节点
//有参构造器
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
transient int size = 0;// 元素的数量
transient Node<E> first;// 指向链表的第一个节点
transient Node<E> last;// 指向链表的最后一个节点
public LinkedList() {
}
// 有参构造器,用于构造包含指定集合的链表
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);// 添加指定集合
}
// 返回元素的数量
public int size() {
return size;
}
// 在链表的头部插入元素
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
// 在链表的尾部插入元素
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
// 删除元素
public boolean remove(Object o) {
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
if (x.item == null) {
unlink(x);
return true;
}
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
unlink(x);
return true;
}
}
}
return false;
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
// 清空链表
public void clear() {
for (Node<E> x = first; x != null; ) {
Node<E> next = x.next;
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
first = last = null;
size = 0;
modCount++;
}
}
LinkedList
4. HashMap
1. HashMap 是 Map 接口的实现类,并继承于 AbstractMap(AbstractMap 是 Map 接口的抽象实现类,并且实现了大部分 Map 接口)2. HashMap 的底层实现:哈希表+链表(属于数据结构中的邻接表)
// 创建
Map map = new HashMap();
// 常用方法
map.put(k,v);// 添加键值对,如果 key 已存在,则覆盖 value,并返回被覆盖的 value;不存在,则返回 null
map.putAll(map02);// 添加指定的 map 集合
map.remove(k);// 删除指定 key 的节点,并返回 value
map.get(k);// 获取指定 key 的 value
map.containsKey(k);// 判断是否含有指定 key 的节点
map.containsValue(v);// 判断是否含有指定 value 的节点
map.size();// 返回键值对的数量
map.values();//获取所有 value,返回值类型 Collection<valueType>
map.keySet(); //获取所有 key,返回值类型 Set<keyType>
map.entrySet();// 获取所有 key 和 value,返回值类型 Set<Entry<keyType, valueType>>
map.clear();// 清空 map 里的所有键值对
// 为了更深入了解 HashMap,我们来分析一下 HashMap 的部分源码
public class HashMap<K,V> extends AbstractMap<K,V>implements Map<K,V>, Cloneable, Serializable {
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;// 默认最小容量 MUST be a power of two. aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;// 默认最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;// 默认负载因子
// 用静态内部类定义链表的节点对象
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;// 存放 hashCode
final K key;// 存放 key
V value; // 存放 value
Node<K,V> next;// 指向下个节点
// 有参构造器
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
/* 使用自己定义的 hashCode()方法
这里给出 java.util.Objects 中定义的 hashCode()方法
public static int hashCode(Object o) {
return o != null ? o.hashCode() : 0;
}
*/
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
/* 使用自己定义的 equals()方法
这里给出 java.util.Objects 中定义的 equals()方法
public static boolean equals(Object a, Object b) {
return (a == b) || (a != null && a.equals(b));
}
*/
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) && Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
transient Node<K,V>[] table;// 声明哈希表
transient int size;// 元素的数量
final float loadFactor;// 负载因子
// 无参构造器
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
// 定义了自己的 hash()方法
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
/* 添加键值对
我们先在这给出 java.lang.Object 的 equals()方法
public boolean equals(Object obj) {
return (this == obj);
}
所以,我们在做 key 的比较时,要根据自己的需求重写 equals()方法
*/
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
// 如果哈希表为空,初始化哈希表
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 如果 hash(key) 对应哈希表位置为 null,直接存放该节点
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 如果 hash(key) 对应哈希表位置存放的节点 key 等于 我们要添加的键值对的 key,则直接覆盖 value
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 如果是树节点的操作
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 如果 hash(key) 对应哈希表位置存放的节点 key 不等于 我们要添加的键值对的 key,则往下寻找,如果有相等的,覆盖 value,没有则在最后一个节点后添加新节点存放
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
// 有参构造器,使用与指定的 Map 相同的映射,构造一个新的 HashMap,新的 HashMap 内包含了指定 map 的所有元素
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
int s = m.size();
if (s > 0) {
if (table == null) { // pre-size
float ft = ((float)s / loadFactor) + 1.0F;
int t = ((ft < (float)MAXIMUM_CAPACITY) ? (int)ft : MAXIMUM_CAPACITY);
if (t > threshold)
threshold = tableSizeFor(t);
}
else if (s > threshold)
resize();
for (Map.Entry<? extends K, ? extends V> e : m.entrySet()) {
K key = e.getKey();
V value = e.getValue();
putVal(hash(key), key, value, false, evict);
}
}
}
// 获取指定 key 的 value
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab;
Node<K,V> first, e;
int n;
K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
// 是否存在指定 key
public boolean containsKey(Object key) {
return getNode(hash(key), key) != null;
}
// 删除指定 key 的键值对,并返回 value
public V remove(Object key) {
Node<K,V> e;
return (e = removeNode(hash(key), key, null, false, true)) == null ? null : e.value;
}
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab;
Node<K,V> p;
int n, index;
if ((tab = table) != null && (n = tab.length) > 0 && (p = tab[index = (n - 1) & hash]) != null) {
Node<K,V> node = null, e;
K k;
V v;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
node = p;
else if ((e = p.next) != null) {
if (p instanceof TreeNode)
node = ((TreeNode<K,V>)p).getTreeNode(hash, key);
else {
do {
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
node = e;
break;
}
p = e;
} while ((e = e.next) != null);
}
}
if (node != null && (!matchValue || (v = node.value) == value || (value != null && value.equals(v)))) {
if (node instanceof TreeNode)
((TreeNode<K,V>)node).removeTreeNode(this, tab, movable);
else if (node == p)
tab[index] = node.next;
else
p.next = node.next;
++modCount;
--size;
afterNodeRemoval(node);
return node;
}
}
return null;
}
// 清空
public void clear() {
Node<K,V>[] tab;
modCount++;
if ((tab = table) != null && size > 0) {
size = 0;
for (int i = 0; i < tab.length; ++i)
tab[i] = null;
}
}
}
HashMap
5. HashSet
1. HashSet 是 Set 接口的实现类,并继承于 AbstractSet(AbstractSet 继承于 AbstractCollection,并且实现了大部分 Set 接口)2. HashSet 的底层实现:利用 “HashMap 键唯一” 的特性
// 创建
Set set = new HashSet();
// 常用方法
set.size();// 返回元素的数量
set.isEmpty();
set.add(e);// 添加元素,添加成功返回 true,否则返回 false
set.remove(e);// 删除指定元素,删除成功返回 true
set.contains(e);// 判断指定元素是否已存在
set.clear();// 清空 set 里的所有元素
// 为了更深入了解 HashSet,我们来分析一下 HashSet 的部分源码
public class HashSet<E>extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
private transient HashMap<E,Object> map;// 哇,直接就用了 HashMap
private static final Object PRESENT = new Object();// 创建一个 Object 对象常量,其实就是用来填充 HashMap 的 value
public HashSet() {
map = new HashMap<>();
}
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
// 当添加元素 e 已经存在时,即对应的 map 里的 key 存在,则 map 的 put()方法会返回被覆盖的 value,这个 value 就是 PRESENT,不等于 null,故返回 false
return map.put(e, PRESENT)==null;
}
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
}
HashSet
6. Iterator 迭代器
1.所有实现了 Collection 接口的容器类都有一个 iterator() 方法,用来返回一个实现了 Iterator 接口的对象2.迭代器使遍历操作更加方便
3.java.util.Iterator 接口定义了如下方法:
* boolean hasNext();// 判断是否有下一个节点
* Object next();// 返回游标(cursor)当前位置的元素,并且游标(cursor)指向下一个位置
* void remove();// 删除游标左边(lastRet)的元素,在执行完 next()方法 之后该操作只能执行一次,因为每次执行 remove()方法后 lastRet 都会置为 -1;只有当再次使用 next()方法后,才会给 lastRet 重新赋值
// 下面给出 ArrayList 的遍历操作,LinkedList、HashMap、HashSet 的遍历操作都类似,需要注意的是 Map 和 Set 是用 哈希表+链表 实现的,所以不能使用第一种遍历方式(索引遍历)
public class Traversal {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
//遍历方式一
for(int i=0;i<list.size();i++)
System.out.println(list.get(i));
//遍历方式二
for(String li : list)
System.out.println(li);
//遍历方式三
for(Iterator<String> iterator = list.iterator();iterator.hasNext();)
System.out.println(iterator.next());
//遍历方式四
Iterator<String> iterator = list.iterator();
while(iterator.hasNext())
System.out.println(iterator.next());
}
}
以上是 Java Collection 的全部内容, 来源链接: utcz.com/z/391786.html