JAVA-基础

一、Java 基础
1.JDK 和 JRE 有什么区别?
答:JRE 是 Java Runtime Environment 的缩写,顾名思义是 java 运行时环境,包含了 java 虚 拟机,java 基础类库。是使用 java 语言编写的程序运行所需要的软件环境,是提供给想运行 java 程序的用户使用的,还有所有的 Java 类库的 class 文件,都在 lib 目录下,并且都打包成 了 jar。 Jdk 是 Java Development Kit 的缩写,顾名思义是 java 开发工具包,是程序员使用 java 语言编写 java 程序所需的开发工具包,是提供给程序员使用的。JDK 包含了 JRE,同时还包 含了编译 java 源码的编译器 javac,还包含了很多 java 程序调试和分析的工具:jconsole, jvisualvm 等工具软件,还包含了 java 程序编写所需的文档和 demo 例子程序。 如果你需要运行 java 程序,只需安装 JRE 就可以了。如果你需要编写 java 程序,需要 安装 JDK。
2.== 和 equals 的区别是什么?
答: (1):对于基本类型和引用类型 == 的作用效果是不同的,如下所示: 基本类型:比较的是值是否相同; 引用类型:比较的是引用是否相同; (2)equals 解读 equals 本质上就是 ==,只不过 String 和 Integer 等重写了 equals 方法,把它变成了 值比较。 == 对于基本类型来说是值比较,对于引用类型来说是比较的是引用;而 equals 默认 情况下是引用比较,只是很多类重写了 equals 方法,比如 String、Integer 等把它变成了值 比较,所以一般情况下 equals 比较的是值是否相等。
3.两个对象的 hashCode()相同,则 equals()也一定为 true,对吗?
答:equals()相等的两个对象,hashcode()一般是相等的,最好在重写 equals()方法时, 重写 hashcode()方法; equals()不相等的两个对象,却并不能证明他们的 hashcode()不相等。 换句话说,equals()方法不相等的两个对象,hashcode()有可能相等。 反过来:hashcode() 不等,一定能推出 equals()也不等;hashcode()相等,equals()可能相等,也可能不等。在 object 类中,hashcode()方法是本地方法,返回的是对象的引用(地址值),而 object 类中的 equals() 方法比较的也是两个对象的引用(地址值),如果 equals()相等,说明两个对象地址值也相等, 当然 hashcode()也就相等了。
4.final 在 java 中有什么作用?
答:final 的作用随着所修饰的类型而不同 (1)、final 修饰类中的属性或者变量 无论属性是基本类型还是引用类型,final 所起的作用都是变量里面存放的“值”不 能变。这个值,对于基本类型来说,变量里面放的就是实实在在的值,如 1,“abc”等。 而引用类型变量里面放的是个地址,所以用 final 修饰引用类型变量指的是它里面的 地址不能变,并不是说这个地址所指向的对象或数组的内容不可以变,这个一定要注意。但 是希望引用对象里的常量在 new 的时候也不发生改变,可以使用 static 关键字。 例如:类中有一个属性是 final Person p=new Person("name"); 那么你不能对 p 进行
重新赋值,但是可以改变 p 里面属性的值,p.setName('newName'); final 修饰属性,声明变量时可以不赋值,而且一旦赋值就不能被修改了。对 final 属 性可以在三个地方赋值:声明时、初始化块中、构造方法中。总之一定要赋值。 (2)、final 修饰类中的方法 作用:可以被继承,但继承后不能被重写。定义为 final 的方法执行效率高于非 final 方法。 (3)、final 修饰类 作用:类不可以被继承。不希望其他人对类进行改动。如果某个类被设置为 final 形 式,则类中的所有方法被设置为 final 形式,但是 final 类中的成员变量可以被定义为 final 或者非 final。 (4)、非 final 的成员变量在堆里,final 类型的成员变量存放在方法区的常量池中。java 常量池技术 java 中讲的常量池,通常指的是运行时常量池,它是方法区的一部分,一个 jvm 实例只 有一个运行常量池,各线程间共享该运行常量池。 java 内存模型中将内存分为堆和栈,其中堆为线程间共享的内存数据区域,栈为线程间 私有的内存区域。堆又包括方法区以及非方法区部分,栈包括本地方法栈、虚拟机栈等
5.java 中的 Math.round(-1.5) 等于多少?
答:round() 方法可把一个数字舍入为最接近的整数。 返回值:与 x 最接近的整数。 说明:对于 0.5,该方法将进行上舍入。 例如,3.5 将舍入为 4,而 -3.5 将舍入为 -3。
6.String 属于基础的数据类型吗?
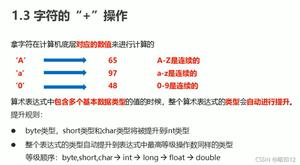
答:String 不是基本数据类型,Java 中基本有 8 个 1.字符:byte(字符) ,char(字节) 2.浮点:float(单精度),double(双精度) 3.基本整性:short,int ,long 4.布尔:boolean 关于基本数据类型与引用类型在 java 中存储位置: (1)基本数据类型在被创建时,在栈上给其划分一块内存,将数值直接存储在栈上。 所有的简单数据类型不存在“引用”的概念,基本数据类型都是直接存储在内存中的内存栈 上的,数据本身的值就是存储在栈空间里面,而 Java 语言里面八种数据类型是这种存储模 型; (2)引用数据类型在被创建时,首先要在栈上给其引用(句柄)分配一块内存,而对 象的具体信息都存储在堆内存上,然后由栈上面的引用指向堆中对象的地址。引用类型继承 于 Object 类(也是引用类型)都是按照 Java 里面存储对象的内存模型来进行数据存储的, 使用 Java 内存堆和内存栈来进行这种类型的数据存储,简单地讲,“引用”是存储在有序的 内存栈上的,而对象本身的值存储在内存堆上的; 修饰变量 基本数据类型-一旦赋值不可改变 引用类型--引用的对象不可改变
7.java 中操作字符串都有哪些类?它们之间有什么区别? 答:String、StringBuffer、StringBuilder String : final 修饰,String 类的方法都是返回 new String。即对 String 对象的任何改变都不
影响到原对象,对字符串的修改操作都会生成新的对象。 StringBuffer : 对字符串的操作的方法都加了 synchronized,保证线程安全。 StringBuilder : 不保证线程安全,在方法体内需要进行字符串的修改操作,可以 new StringBuilder 对象,调用 StringBuilder 对象的 append、replace、delete 等方法修改字符串。
8.String str="i"与 String str=new String(“i”)一样吗? 答:java 存在一个常量池,可以用来存储字符串常量。 1 创建的字符串变量在内存中的区别 两者看似都是创建了一个字符串对象,但在内存中确是各有各的想法。 String str1= “abc”; 在编译期,JVM 会去常量池来查找是否存在“abc”,如果不存在, 就在常量池中开辟一个空间来存储“abc”;如果存在,就不用新开辟空间。然后在栈内存中 开辟一个名字为 str1 的空间,来存储“abc”在常量池中的地址值。 String str2 = new String("abc") ;在编译阶段 JVM 先去常量池中查找是否存在“abc”,如果 过不存在,则在常量池中开辟一个空间存储“abc”。在运行时期,通过 String 类的构造器在 堆内存中 new 了一个空间,然后将 String 池中的“abc”复制一份存放到该堆空间中,在栈 中开辟名字为 str2 的空间,存放堆中 new 出来的这个 String 对象的地址值。 也就是说,前者在初始化的时候可能创建了一个对象,也可能一个对象也没有创建;后 者因为 new 关键字,至少在内存中创建了一个对象,也有可能是两个对象。 2 String 类的特性 String 类 是 final 修饰的,不可以被继承。 String 类的底层是基于 char 数组的。 3 两个方面 1)性能效率 String 类被设计成不可变(immutable)类,所以它的所有对象都是不可变对象。例如:
String str = “hello"; str = str + "world“;(并不是 str 的值不可以修改,只是会引向一个新的对象。) 所以当上文 str 指向了一个 String 对象(内容为“hello”),然后对 str 进行“+”操作, str 原来指向的对象并没有变,而是 str 又指向了另外一个对象(“hello world”),原来的对象 还在内存中。 由此也可以看出,频繁的对 String 对象进行修改,会造成很大的内存开销。此时应该用 StringBuffer 或 StringBuilder 来代替 String。 而 new String()更加不适合,因为每一次创建对象都会调用构造器在堆中产生新的对 象,性能低下且内存更加浪费。 2)安全性 对象都是只读的,所以多线程并发访问也不会有任何问题。 由于不可变,用来存储数据也是极为安全的。 引入问题:什么是不可变对象(immutable object),不可变对象有什么好处,在什么情况 下应该用,或者更具体一些,Java 的 String 类为什么要设成 immutable 类型? 答:不可变对象,顾名思义就是创建后不可以改变的对象,典型的例子就是 Java 中的 String 类。 String s = "ABC"; s.toLowerCase(); 如上 s.toLowerCase()并没有改变“ABC“的值,而是创建了一个新的 String 类“abc”, 然后将新的实例的指向变量 s。
相对于可变对象,不可变对象有很多优势: 1).不可变对象可以提高 String Pool 的效率和安全性。如果你知道一个对象是不可 变的,那么需要拷贝这个对象的内容时,就不用复制它的本身而只是复制它的地址,复制地 址(通常一个指针的大小)需要很小的内存效率也很高。对于同时引用这个“ABC”的其他 变量也不会造成影响。 2).不可变对象对于多线程是安全的,因为在多线程同时进行的情况下,一个可变 对象的值很可能被其他进程改变,这样会造成不可预期的结果,而使用不可变对象就可以避 免这种情况。 当然也有其他方面原因,但是 Java 把 String 设成 immutable 最大的原因应该是效率和安 全。
10.String 类的常用方法都有那些? 答:length()字符串的长度; charAt()截取一个字符; getchars()截取多个字符并由其他字符串接收,其中第一个参数 0 是要截取的字 符串的初始下标(int sourceStart),第二个参数 5 是要截取的字符串的结束后的下一个下标 (int sourceEnd)也就是实际截取到的下标是 int sourceEnd-1,第三个参数是接收的字符串 (char target[]),最后一个参数是接收的字符串开始接收的位置; byte b[] = a.getBytes();将字符串变成一个 byte 数组; char[]b = a.toCharArray();toCharArray()将字符串变成一个字符数组; equals()和 equalsIgnoreCase()比较两个字符串是否相等,前者区分大小写,后者不 区分; startsWith()和 endsWith()判断字符串是不是以特定的字符开头或结束; toUpperCase()和 toLowerCase()将字符串转换为大写或小写; concat() 连接两个字符串; trim()去掉起始和结束的空格; substring()截取字符串; indexOf()和 lastIndexOf()前者是查找字符或字符串第一次出现的地方,后者是查找 字符或字符串最后一次出现的地方; compareTo()和 compareToIgnoreCase()按字典顺序比较两个字符串的大小,前者区 分大小写,后者不区分; replace() 替换。
11.抽象类必须要有抽象方法吗? 答:不是必须有的,但是有抽象方法的类一定是抽象类。 延伸:(1)、抽象类被继承后,需要实现所有的抽象方法; (2)、抽象类不可以实例化对象; (3)、抽象方法不能有方法主体。
12.普通类和抽象类有哪些区别? 答:1、抽象类可以没有抽象方法,也可以有普通方法;
2、抽象方法不能声明为静态,抽象方法只需声明无需实现,没有主体,普通方法 有主体; 关于抽象方法不能声明为静态的解释:因为静态方法属于字节码,不需要进行实例 化就可以运行,如果抽象方法声明为静态后,那抽象方法没有方法体 3、抽象类的子类必须实现父类的抽象方法,除非该子类也是抽象类; 4、抽象类可以有构造方法,子类中所有的构造方法默认都会访问父类中空参构造 方法;父类的构造方法不能被继承,只能显式或者隐式的被调用。 5、含有抽象方法的类必须是抽象类; 6、抽象类不能被实例化;
13.抽象类能使用 final 修饰吗? 答:不能,抽象类是被用于继承的,final 修饰代表不可修改、不可继承的。
14.接口和抽象类有什么区别? 答:1、接口中的方法默认为“public abstract”,接口中的成员变量默认为“public static final”,抽象类中的静态成员变量的访问权限可以是任意的。 2.、抽象类可以有构造方法,接口中不能有构造方法。 3、 抽象类中可以有普通成员变量,接口中没有普通成员变量。 4、接口的方法都没有方法体即都是抽象的,但是抽象类可以具有非抽象普通方法; 5、一个子类可以多重继承接口,但是一个子类只能继承一个抽象类,接口不可以实现 接口,但可以继承接口,并且可以继承多个接口,用逗号隔开。
15.java 中 IO 流分为几种?
16.BIO、NIO、AIO 有什么区别?
17.Files 的常用方法都有哪些?
补充内容:
关于 Integer:
Integer i01 = 59; int i02 = 59; Integer i03 = Integer.valueOf(59); Integer i04 = new Integer(59);
(1):比较 i01 和 i02,Integer i01=59 这里涉及到自动装箱过程,59 是整型常量,经包 装使其产生一个引用并存在栈中指向这个整型常量所占的内存,这时 i01 就是 Integer 的引 用。 而 int i02=59 由于 int 是基本类型,所以不存在引用问题,直接由编译器将其存放在栈 中,换一句话说,i02 本身就是 59。那么 System.out.println(i01== i02)结果呢?这里涉及到了
拆箱的过程,因为等号一边存在基本类型所以编译器后会把另一边的 Integer 对象拆箱成 int 型,这时等号两边比较的就是数值大小,所以是 true。
(2):如果是 Integer i01=59;Integer i02=59;然后 System.out.println(i01== i02)的结果 是?可能你会说比较数值大小所以相等啊,也有可能说等号两边对象引用,所以比较的是引 用,又因为开辟了不同的内存空间,所以引用不同所以返回 false。可是正确答案是:true. 再来看这个问题::如果是 Integer i01=300;Integer i02=300;然后 System.out.println(i01== i02) 的结果是? 你可能说上面你不是说了true嘛,怎么还问这样的问题,可是这次的答案是false。
在 Integer 类中存在内部类,做的主要工作就是把一字节的整型数据(-128-127)装包成 Integer 类并把其对应的引用存入到 cache 数组中,这样在方法区中开辟空间存放这些静态 Integer 变量,同时静态 cache 数组也存放在这里,供线程享用,这也称静态缓存。
(3):Integer i01=59 返回的是指向缓存数据的引用。那么 Integer.valueOf(59)函数的功 能就是把 int 型转换成 Integer,简单说就是装包,那他是新创建一个对象吗?还是像之前利 用缓存的呢?利用缓存,这样做既提高程序速度,又节约内存。
(4):Integer.valueOf(59)返回的是已缓存的对象的引用,而 Integer i04 = new Integer(59) 是在堆中新开辟的空间,所以二者的引用的值必然不同。
关于单例模式:
1、构造方法私有化;
2、实例化的变量引用私有化;
3、获取实例的方法共有。 分为两种:懒汉模式和饿汉模式 懒汉模式:指的全局的单例实例只有在第一次调用使用的时候才会进行构建。 饿汉模式:指全局的单例实例在类加载的时候完成构建。 懒汉模式的 DEMO:其中的 private 是防止构造方法实例化,但是该种方式并不能阻止 反射进行。
(1) 静态工厂 :
//懒汉式单例类.在第一次调用的时候实例化自己public class Singleton {
private Singleton() {}
private static Singleton single=null;
//静态工厂方法
public static Singleton getInstance() {
if (single == null) {
single = new Singleton();
}
return single;
}
}
(2) 方法体加锁,由于上种方式在多线程的情况下存在不安全的行为,所以使用锁
public static synchronized Singleton getInstance() { if (single == null) {
single = new Singleton();
}
return single;
}
(3)、上述方式存在效率问题,这种是双重检查锁定:
public static Singleton getInstance() { if (singleton == null) {
synchronized (Singleton.class) {
if (singleton == null) {
singleton = new Singleton();
}
}
}
return singleton;
}
双重检查锁定中,在 new Singleton();步骤中,可能会存在重排序问题,所以当多线程情 况下,就会出现错误的结果,所以在
private static Singleton single=null; 需要添加 volatile 关 键字,有效的防止重排序的情况出现。
instance = new Singleton(); // 第 10 行
// 可以分解为以下三个步骤
// 可以分解为以下三个步骤1 memory=allocate();// 分配内存 相当于 c 的 malloc
2 ctorInstanc(memory) //初始化对象
3 s=memory //设置 s 指向刚分配的地址
// 上述三个步骤可能会被重排序为 1-3-2,
1 memory=allocate();// 分配内存 相当于 c 的 malloc3 s=memory //设置 s 指向刚分配的地址
2 ctorInstanc(memory) //初始化对象
在这种情况下,在运行完第三步,即还没有完成对象的初始化。如果有另外一个线程在 进行判断(if (singleton == null) )这一步的时候,会判断否,直接进行 return,但是此 时 singleton 还未进行初始化对象。 4):静态内部类--外部类初次加载,会初始化静态变量、静态代码块、静态方法,但不 会加载内部类和静态内部类。
4):静态内部类--外部类初次加载,会初始化静态变量、静态代码块、静态方法,但不 会加载内部类和静态内部类。
public class Singleton { private static class LazyHolder {
private static final Singleton INSTANCE = new Singleton(); }
private Singleton (){}
public static final Singleton getInstance() {
return LazyHolder.INSTANCE;
}
}
//饿汉式单例模式,这种方式性能上不存在优势:
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
private Singleton1() {}
private static final Singleton1 single = new Singleton1();
//静态工厂方法
public static Singleton1 getInstance() {
return single;
}
}
使用枚举类型实现单例模式,该种方式更加简洁,无偿提供序列化机制,绝对可以防止多次 实例化,即使面对复杂的序列化或者反射供给的时候:
public enum EnumSingleton {
INSTANCE;
public EnumSingleton getInstance(){
return INSTANCE;
}}
以上是 JAVA-基础 的全部内容, 来源链接: utcz.com/z/391017.html