Java的异常

转载请注明出处:https://www.cnblogs.com/zhizaixingzou/p/10024016.html
目录
1. 异常
1.1. 异常的最佳实践
1.1.1. 非检查异常
Java官方的异常类IllegalArgumentException定义如下。
1 package java.lang;2
3 public class IllegalArgumentException extends RuntimeException {
4 private static final long serialVersionUID = -5365630128856068164L;
5
6
7 public IllegalArgumentException() {
8 super();
9 }
10
11 public IllegalArgumentException(String message) {
12 super(message);
13 }
14
15 (位曰:官方给出的参数名是s,强迫症的我觉得那不好,所以替换为使用message)
16
17 public IllegalArgumentException(Throwable cause) {
18 super(cause);
19 }
20
21 public IllegalArgumentException(String message, Throwable cause) {
22 super(message, cause);
23 }
24 }
首先,异常类的取名是有讲究的:其一是以“Exception”结尾,好向使用者昭示本类是异常类;其二是前缀要能表明使用它的方法发生异常的关键点所在,或者说发生了什么类型的异常,比如这里的“IllegalArgument”就表明,如果一个方法发生了此类型的异常,就说明调用此方法的人传进来了一个非法的或者不合适的参数。
其次,异常的祖宗类Throwable实现了Serialiable接口,所以异常定义中,一般需要指定一个私有常量serialVersionUID。
再次,需要指定4个构造方法:一个不带参数、一个带异常消息说明的参数、一个带原因异常(使用原因异常,常常表明本异常类是对原因异常的封装重抛,为何要封装重抛?不同层次有不同层次应该或允许关注的消息和类型,也算是信息的隐藏吧)的参数、一个带消息说明的参数和引发异常的参数。但无论哪种构造方法,都通过super原样传递参数给父类的同型(参数类型和顺序相同)构造方法。
另外,如果异常类设计定位为非检查型异常,就继承自RuntimeException好了,比如这里的类IllegalArgumentException就是,如果为检查型异常,就继承自更泛化的Exception。
最后,异常也可以有自己的字段和其他方法,需要根据场景灵活定制。
根据IllegalArgumentException的设计初衷,它应被用在方法参数的检查上。这里还是以Java官方的ArrayList为例。
1 public class ArrayList<E> extends AbstractList<E>2 implements List<E>, RandomAccess, Cloneable, java.io.Serializable
3 {
4 ……
5 public ArrayList(int initialCapacity) {
6 if (initialCapacity > 0) {
7 this.elementData = new Object[initialCapacity];
8 } else if (initialCapacity == 0) {
9 this.elementData = EMPTY_ELEMENTDATA;
10 } else {
11 throw new IllegalArgumentException("Illegal Capacity: "+
12 initialCapacity);
13 }
14 }
15 ……
16 }
ArrayList对数据集的管理是通过数组完成的,如果为ArrayList指定的初始容量为负,显然不合适,所以指定为负数就抛出异常,并指定了异常的详细消息说明。
在最靠近最终用户的代码中,我们往往需要尝试异常捕获并处理。
1 package com.cjw.knowledge.demo;2
3 import java.util.ArrayList;
4
5 public class Demo {
6 public static void main(String[] args) {
7 try {
8 ArrayList arrayList = new ArrayList<String>( Integer.parseInt(args[0]));
9 } catch (IllegalArgumentException e) {
10 System.out.println(e.getMessage());
11 }
12 }
13 }
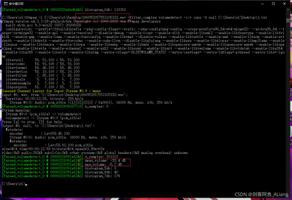
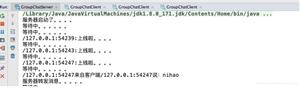
如果执行时指定了负数参数-5,则运行的结果是:
但是,IllegalArgumentException继承自RuntimeException,被设计为非检查型异常,也就是说,它被设计出来并不一定强制要求程序捕获并处理它的。
1 package com.cjw.knowledge.demo;2
3 import java.util.ArrayList;
4
5 public class Demo {
6 public static void main(String[] args) {
7 ArrayList arrayList = new ArrayList<String>(Integer.parseInt(args[0]));
8 }
9 }
上面的代码也可以编译通过,只是如果真传递进来一个负数参数,那么就会抛出异常。而这个异常在main方法这一最靠近最终用户的地方都没有处理,就会传递给虚拟机,虚拟机会据此结束掉该Java进程(实际上是结束当前线程,只是因为该Java进程只有这么一个线程,该线程结束,Java进程自然结束)。那么Java为什么允许这样呢?因为非检查型异常被认为是可以通过编码和人为控制来避免的。比如,这里的参数可以通过启动进程时,由进程启动者按照程序使用说明保证非负,如果不是通过程序参数,编码时也可以通过非负判断来保证传递进来的参数非负。总之,Java会给你自由,认为你可以通过编码或额外控制处理好这样的事情,所以就不用多出捕获的麻烦来。
1.1.2. 检查异常
然而,还有一类异常,是人为和编程不能完全控制的,比如我需要读取一个远程文件,这个文件是否存在则不受我的控制。也就是说,编码者或运维者不能事先保证,必定会有文件不存在的可能。所以编程者理应尝试捕获并处理,考虑到这种情况,Java干脆就不给你自由了,因为给你自由就是纵容你可以考虑不周! (如果你认为我说的太重,还是希望用非检查型异常的不捕获,那么可以退化为返回布尔型)
对于检查型异常,还是以Java官方的代码为例,这里考虑IOException类的定义。
1 package java.io;2
3 public class IOException extends Exception {
4 static final long serialVersionUID = 7818375828146090155L;
5
6 public IOException() {
7 super();
8 }
9
10 public IOException(String message) {
11 super(message);
12 }
13
14 public IOException(Throwable cause) {
15 super(cause);
16 }
17
18 public IOException(String message, Throwable cause) {
19 super(message, cause);
20 }
21 }
这个类的定义与之前解释的IllegalArgumentException差不多,只是它继承自Exception,说明是检查型异常。还有一点就是serialVersionUID不是私有的了,其实是否私有,影响不大,大概是不同程序员一时的闪念不同罢了吧。
再来看看非终端的使用者是怎样用该异常类的。
1 public class FileInputStream extends InputStream2 {
3
4 ……
5 public int read() throws IOException {
6 return read0();
7 }
8
9 private native int read0() throws IOException;
10 ……
11 }
这里的read方法throws了IOException,是因为IOException是检查型异常。Java语言规范规定,如果一个方法有throw检查型异常,则调用它的方法则必须捕获并处理它,或者即使不处理,也必须在方法声明中throws它。如果二者不居其一则编译不过的。
下面是最靠近最终用户的程序对该异常的处理。
1 package com.cjw.knowledge.demo;2
3 import java.io.FileInputStream;
4 import java.io.FileNotFoundException;
5 import java.io.IOException;
6
7 public class Demo {
8 public static void main(String[] args) {
9 FileInputStream fileInputStream = null;
10 try {
11 fileInputStream = new FileInputStream("C:\\readme.txt");
12 System.out.println(fileInputStream.read());
13 } catch (FileNotFoundException e) {
14 System.out.println("Opening the file failed. Message: " + e.getMessage());
15 } catch (IOException e) {
16 System.out.println("Reading the file failed. Message: " + e.getMessage());
17 } finally {
18 if (fileInputStream != null) {
19 try {
20 fileInputStream.close();
21 } catch (IOException e) {
22 e.printStackTrace();
23 }
24 }
25 }
26 }
27 }
可以看到,这里对会抛出IOException异常(先不要管FileNotFoundException异常,你要深究,则可以看到它也是检查型异常)的方法做了异常捕获和处理,不这样做会编译不过。
1.1.3. 异常的最佳实践
到此为止,我们对两种异常类型的基本使用都作了说明,也对异常设计为何种类型为当作了解释。但我们还需要清晰认识到另外几点,那就是抛出异常、传递异常、封装重抛异常、捕获并处理异常的时机。
首先,我们捕获并处理异常,意味着对该种类型的异常已经到了最终需要了结的时候了,也就是说,我们的代码可能已经直接面对最终用户了(如main方法),有什么异常都需要直接告知最终用户以便其作出应对。我们要告诉最终用户的信息,其实很容易得到,就是通过e.getMessage,这恰是异常相对于错误码异常结构为好的地方。
明白了异常的最终使用处和引入出发点,我们就可以清楚异常的使用了。在底层对象中,常常需要干些环境准备类(比如打开文件)或基础辅助类(比如字符串转数值)的工作,这也是容易出现异常的地方,我们通过异常类封装异常及其原因并抛出异常,而不是让方法返回布尔型或错误码。中间层的对象在处理时,如果不需要做信息隐藏等,则可以直接重新抛出,即直接传递,如果抛出时认为上层不需要知道更详细的信息,则可以用新的更粗略的信息覆盖原信息,或者将原来的异常封装为原发异常,甚至完全转换为另一个类型的异常。到最上层对象也即是面向最终用户的对象中,则需要处理这些异常了。注意,何为底层对象、中间层对象、最上层对象,也是相对而言的,需要实践中体会内化(最上层往往意味着从系统用户的角度看,而中间层和底层则是从系统开发者角度看)。
最后,如果异常点发生处也即最终用户代码处,那么此时没有必要使用异常,异常的处理可以退化为错误码或布尔型方法。
在实际项目中,我们常常会为不同的层次设计一个基本的异常类,如BusinessException、ServiceException、DAOException等。在底层向上传递的过程中,会进行本层的包装,直到与用户最直接的UI层次。
总之,1)对于异常,我们首先考虑使用异常类这一结构化的形式,而非使用返回布尔型或错误码的方法,2)设计异常时,我们要考虑异常发生是否可以由我们百分百控制,如果不能则设计为检查型异常,否则为非检查型异常,3)异常的发生,一般发生在底层对象,此时封装最精确化的信息后抛出异常,4)如果不是面向最终客户的中间层对象遇到异常,则直接向上抛出,或者考虑是否有必要对信息做覆盖或对异常进行重新变换再抛出,当然也可以保留cause,5)最终用户代码必须处理检查型异常,提供给用户有用的决策信息,6)代码编写时都要主动控制非检查型异常的条件,这需要个人有良好的编码习惯和经验。7)实际项目中,会根据软件架构的层次,在每一层次都定义一个基本的异常类。事先制定一个整体的异常处理策略规范。
最后说说几个原则:
不要直接忽略异常(常见的处理时e.printStackTrace())。
不要在try/catch/finally中包含过多语句,这是为了避免消耗过多资源。
能处理异常就尽量早处理,而不是一味向上抛出。
异常机制是为了把异常代码和正常流程代码分开,避免传统编码中过多非法值的判断。所以,try/catch/finally也不宜过多,影响可读性。
异常机制常用作用例的旁支处理。
如果方法发生了异常,应该使得对象保持方法调用前的状态。
异常对象应该包含发生异常时的数据。
把方法可能抛出的异常写入文档。
抛出的异常应该在业务理解上适用于本层对象抽象(转译)。
能使用Java自带的异常就使用,其次才是自己定义。
能够定义非检查型异常(又叫运行时异常)就尽量用它,其次才考虑检查型异常(又叫编译时隐藏,在有不由自己完全控制的场景下),因为检查型异常必须要捕获并处理代码,会有不必要的麻烦。适用于该观点,可以将检查型异常进行重构,变化为非检查型异常。
不要用异常来处理程序的控制流程,异常只用于异常情况。
UI层的出错信息会被用户看到,用户可不希望看到一个异常栈,更不希望程序挂掉,而是希望得到一个友好的提示信息,并指导下一步操作。所以在UI层,可以记录错误日志,可以输出友好信息。用户传入的参数非法的概率很高,所以控制层接收参数时一定要校验,而非原封不动地传到底层模块。
检查型异常的设计主要被用来代替错误码。这类异常,主要用来恢复程序执行,所以应该提供关于异常尽可能多的数据,如错误行号、列号等,以便于帮助调用者恢复程序。
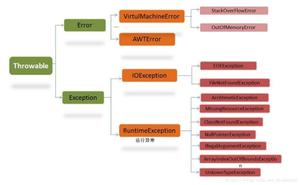
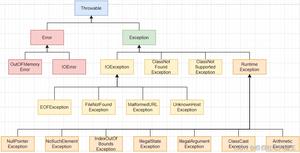
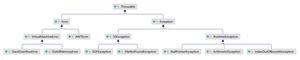
1.2. 异常的继承体系
异常的继承体系如下。
Error类表示JVM发生的错误,它不在Java程序控制范围内,编程时不能捕获到,编译时也检查不到,只能被忽略,但是一旦发生程序就结束。例如栈溢出、内存溢出。
检查型异常:继承自Exception但不继承自RuntimeException,这类异常是程序员无法控制的,例如打开一个文件,或接受用户的一个输入等,对这类异常,程序必须进行捕获处理或作为方法声明throws重新抛出,不能简单地忽略。
非检查型异常:继承自RuntimeException,这类异常可以被程序简单地忽略,这类异常往往通过修改代码来处理。Error也是非检查型异常。
1.2.1. 检查型异常
1.2.1.1. ClassNotFoundException
例如加载类时找不到相应的类。
1.2.1.2. InterruptedException
例如一个线程被另一个线程中断。
1.2.1.3. IOException
IO操作相关的异常。
1.2.2. 非检查型异常
1.2.2.1. ArithmeticException
例如整数除以零。
1.2.2.2. ArrayIndexOutOfBoundsException
例如访问数组时索引为负或等于大于数组个数。
1.2.2.3. ClassCastException
例如类型转换时不兼容。
1.2.2.4. IllegalArgumentException
例如向方法传递了一个非法或不合适的参数。
1.2.2.5. NullPointerException
例如访问某个对象的成员,但该对象为null。
1.2.2.6. NumberFormatException
例如非数值的字符串转数值。
1.2.2.7. UnsupportedOperationException
例如组合模式中,叶子结点就无添加操作。
1.3. Throwable类
1.3.1. printStackTrace
1 public class Demo { 2 public static void main(String[] args) {
3 FileInputStream fileInputStream = null;
4 try {
5 fileInputStream = new FileInputStream("C:\\readme.txt");
6 } catch (FileNotFoundException e) {
7 e.printStackTrace();
8 }
9 }
10 }
输出结果如下:
通过debug看打印的东西:
也就是说,该方法将toString方法的内容以及栈跟踪信息输出到标准错误流。
对于带初始化非空cause的,通常应该包括cause的栈跟踪信息:
1.3.2. Throwable
最佳实践中异常类的构造方法如下。
最终执行Throwable类的如下构造方法。
构造时,可以将异常的栈跟踪信息保存,也可以将异常的原因异常(也叫根源异常,抛出它的类构建在低层抽象之中,而高层操作由于低层操作的失败而失败)保存到cause字段中,保存cause是异常链机制的关键。如果单独指定cause,那么detailMessage为cause.toString(),并非cause.getMessage。
1.3.3. fillInStackTrace
无参的fillInStackTrace方法会清空stackTrace的栈跟踪信息,并将当前线程的栈跟踪信息重新记录到stackTrace,栈顶的栈帧记录到第0个元素,以此类推。
1.3.4. getMessage
返回异常的详细消息说明,即detailMessage字段。
1.3.5. getCause
返回原因异常,即cause字段。
1.3.6. initCause
该方法可以在无cause的构造方法内或之后调用一次或多次,但如果已经调用过了有cause的构造方法,则一次都不能调用。
1.3.7. getStackTrace
返回栈跟踪信息,用于自己编程处理该信息。
1.3.8. setStackTrace
用于高级系统重新栈跟踪信息。
1.4. 异常抛出、捕获和处理的语法
1.4.1. 异常抛出
抛出异常使用“throw 异常对象”语法。
一个方法如果抛出了一个检查型异常,并且没有被处理,那么必须在方法声明中用throws指定它的类型。
子类的覆写方法throws的异常必须在父类该方法throws的异常以内。也就是说,父类没有throws的异常,子类方法中不能throws,子类方法throws的异常必须是父类的异常或子异常。
1.4.2. 异常捕获和处理
捕获和处理异常的语法格式可以有:
1)try/catch
2)try/finally
3)try/catch/finally
catch中包含异常类型和异常名,如果异常类型是或的关系则可以用“|”连接,异常名则可以同享。
catch可以是一个或多个,如果是多个,那么实际异常类型会顺次作兼容匹配,匹配到的第一个里面的代码会执行,然后退出catch,所以通常是将具体的异常放前面,泛化的异常放后面。
try、catch、finally中的局部变量互相独立,不可共享。
1.4.3. 异常处理的执行顺序
有些语言执行异常处理后回到异常抛出点(执行throw语句的地方)继续执行,叫恢复式异常处理模式,而Java则采用终结式异常处理模,即不再回到异常抛出点后,而是直接执行catch或finally后面的代码。
如果try中抛出异常,且有匹配的catch块,则先执行catch块,再执行finally块。如果没有catch块匹配,则先执行finally,然后去外面的调用者中寻找合适的catch块。
try发生异常,且匹配的catch块中处理异常时也抛出异常,那么后面的finally也会执行,然后去外围调用者中寻找合适的catch块。
保护代码无论是否有异常发生,都会执行finally里面的代码(除非try中最后执行的是System.exit()),这常用来做清理善后性质的工作,如关闭文件、关闭数据库连接等资源释放动作。
异常如果不被处理,那么当前线程就会结束,但其他无异常的线程仍会执行。也就是说,异常是线程独立的。
执行顺序往往不按常规思维来,所以要看执行顺序,往往需要从字节码上来。
1 private int setHour(Clock clock, int hour) { 2 try {
3 clock.setHour(hour);
4 return hour;
5 } catch (Exception e) {
6 e.printStackTrace();
7 return 0;
8 } finally {
9 System.out.println("finally");
10 }
11 }
>javap -verbose -p Demo.class
可以看到finally也是当做异常处理器对待的,也就是type为any的项。
1.5. 参考资料
https://www.cnblogs.com/beatIteWeNerverGiveUp/p/5915255.html
https://blog.csdn.net/jiakw_1981/article/details/3079026
以上是 Java的异常 的全部内容, 来源链接: utcz.com/z/390585.html