java8 Stream常用方法和特性浅析

前言:对大数据量的集合的循环处理,stream拥有极大的优势,完全可以用stream去代替for循环。
先说下Stream的优势:它是java对集合操作的优化,相较于迭代器,使用Stream的速度非常快,并且它支持并行方式处理集合中的数据,默认情况能充分利用cpu的资源。同时支持函数式编程,代码非常简洁。
Stream是一种用来计算数据的流,它本身并没有存储数据。你可以认为它是对数据源的一个映射或者视图。
它的工作流程是:获取数据源->进行一次或多次逻辑转换操作->进行归约操作形成新的流(最后可以将流转换成集合)。
1.生成流
Stream的创建需要一个数据源(通常是一个容器或者数组):
例1:Stream<String> stream = Stream.of("I", "got", "you", "too");
例2:String [] strArray = new String[] {"a", "b", "c"};
stream = Arrays.stream(strArray);
例3:List<String> list = Arrays.asList(strArray);
stream = list.stream();
2.流的操作
流的操作类型分2种:中间操作与聚合操作。
2.1中间操作(intermediate ):
中间操作就是对容器的处理过程,包括:排序(sorted...),筛选(filter,limit,distinct...),映射(map,flatMap...)等
2.1.1 排序操作(sorted):(参考:https://www.cnblogs.com/a-du/p/8289537.html)
sorted提供了2个接口:
1、sorted() 默认使用自然序排序, 其中的元素必须实现Comparable 接口 。
2、sorted(Comparator<? super T> comparator) :我们可以使用lambada 来创建一个Comparator 实例。可以按照升序或着降序来排序元素。
注意sorted是一个有状态的中间操作,即,只有全部执行完所有的数据才能知道结果。
比如:将一些字符串在地址中按出现的顺序排列:
String address = "中山北路南京大学仙林校区";List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
aList.stream().sorted(
Comparator.comparing(a->address.indexOf(a))
).forEach(System.out :: println);
也可以像下面这样不使用比较器:
aList.stream().sorted((a,b)->address.IndexOf(a)-address.IndexOf(b)
).forEach(System.out :: println);//由大到小排序
输出结果:
注:1.这里仙林大学城这个字段没有出现,所以序号是-1,被排在最前面。
2.Comparator.comparing();这个是比较器提供的一个方法,它返回的也是一个比较器,源码如下:
public static <T, U extends Comparable<? super U>> Comparator<T> comparing(Function<? super T, ? extends U> keyExtractor)
{
Objects.requireNonNull(keyExtractor);
return (Comparator<T> & Serializable)
(c1, c2) -> keyExtractor.apply(c1).compareTo(keyExtractor.apply(c2));
}
2.1.2 筛选操作(filter):
上一步中,我们把一些字符串,按照在地址中出现的顺序排序。
接下来我们可能想要进行筛选,把不在地址中,但是indexof为“-1”,排在最前面的数据筛选掉:
filter可以对集合进行筛选,它的参数可以是一个lambda表达式,流中的数据将会通过该lambda表达式返回新的流。
这里Stream有一个特性很重要,它像一个管道,可以将多个操作连接起来,并只执行一次for循环,这样大大提高了效率,即使第二次的流操作需要第一次流操作的结果,时间复杂度也只有一个for循环:
于是我可以在前面加个filter(),这样把“-1”过滤掉:
String address = "中山北路南京大学仙林校区";List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
aList.stream().filter(a->address.indexOf(a)!=-1)
.sorted(
Comparator.comparing(a->address.indexOf(a))
).forEach(System.out :: println);
输出结果:
注:foreach是一个终端操作,参数也是一个函数,它会迭代中间操作完成后的每一个数据,这里它将每个不为空的元素打印出来。
其它的过滤操作还包括:
limit(long maxSize):获得指定数量的流。
distinct():通过hashCode和equals去除重复元素。
2.1.3 映射操作(map):
映射操作,就像一个管道,可以将流中的元素通过一个函数进行映射,返回一个新的元素。
这样遍历映射,最终返回一个新的容器,注意:这里返回的新容器数据类型可以不与原容器类型相同:
举个例子:我们将address中每个元素的位置找出,并返回一个int类型的存储位置信息的数组:
@Testpublic void test() {
String address = "中山北路南京大学仙林校区";
List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
List<Integer> aIntegers =aList.stream()
.map(str->mapFunc(address, str)).collect(Collectors.toList());
System.out.println(aIntegers);//.forEach(System.out :: println);
}
private int mapFunc(String address,String str) {
return address.indexOf(str);
}
结果如下:
2.2规约操作(reduction ):
之前的中间操作只是对流中数据的处理,最终我们还是要将它们整合输出为一个结果,比如,返回一个最大值,返回一个新的数组,或者将所有元素进行分组等,这就是规约(末端)操作的作用。
我们常用的末端操作函数有Reduce()和collect();
2.2.1Reduce
reduce就是减少的意思,它会将集合中的所有值根据规则计算,最后只返回一个结果。
它有三个变种,输入参数分别是一个参数、二个参数以及三个参数;
1.一个参数的Reduce
它的参数就是一个函数接口:Optional<T> reduce(BinaryOperator<T> accumulator)
比如,我们找出数组中长度最大的一个数:
public void test() { String address = "中山北路南京大学仙林校区";
List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
Optional<String> a =aList.stream()
.reduce((s1, s2) -> s1.length()>=s2.length() ? s1 : s2);
System.out.println(a.get());//仙林大学城
}
这里的Optional<T>就是一个容器,它可以避免空指针,具体可以百度,这里也可以返回一个String的。
2.两个参数的Reduce
T reduce(T identity, BinaryOperator<T> accumulator)
2个参数其实除了一个函数接口以外,还包括一个固定的初始化的值,它会作为容器的第一个元素进入计算过程:
例:将每个字符串拼接,并在之前加上“value:”:
public void test() { String address = "中山北路南京大学仙林校区";
List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
String t="value:";
String a =aList.stream()
.reduce(t, new BinaryOperator<String>() {
@Override
public String apply(String s, String s2) {
return s.concat(s2);
}
});
System.out.println(a);
}
结果如下:
3.三个参数的情况主要是在并行(parallelStream)情况下使用:可以参考(https://blog.csdn.net/icarusliu/article/details/79504602),有需要可以了解下。
2.2.2Collect
collect是一个非常常用的末端操作,它本身的参数很复杂,有3个:
<R> R collect(Supplier<R> supplier, BiConsumer<R,? super T> accumulator, BiConsumer<R,R> combiner);
还好,考虑到我们日常使用,java8提供了一个收集器(Collectors),它是专门为collect方法量身打造的接口:
我们常常使用collect将流转换成List,Map或Set:
1.转换成list:
Stream<String> stream = Stream.of("I", "love", "you", "too");
List<String> list = stream.collect(Collectors.toList());2.转换成Map:
我们可以使用Collector.toMap()接口:Collectors.toMap(keyMapper, valueMapper),这里就需要我们指定key和value分别是什么。
例:我们将数组中的字符串作为key,字符串长度作为value,生成一个map:
String address = "中山北路南京大学仙林校区";List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
String t="value:";
Map<String, Integer> maps =
aList.stream().collect(Collectors.toMap(Function.identity(), String::length));
System.out.println(maps);
打印结果:
{中山北路=4, 大学=2, 仙林大学城=5, 仙林校区=4, 南京=2}
通常,我们在进行分组操作的时候也会将容器转换为Map,这里也说明一下:Collectors.groupingBy(classifier)
groupingBy与sql的group by类似,就是一个分组函数,
例:我们将数组中的字符串按长度分组:
String address = "中山北路南京大学仙林校区";List<String> aList = new ArrayList<>();
aList.add("南京");
aList.add("大学");
aList.add("仙林校区");
aList.add("仙林大学城");
aList.add("中山北路");
String t="value:";
Map<Integer, List<String>> maps =
aList.stream().collect(Collectors.groupingBy(String::length));
System.out.println(maps);
打印结果:
{2=[南京, 大学], 4=[仙林校区, 中山北路], 5=[仙林大学城]}
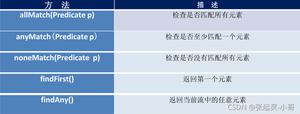
其他的末端操作api:
findFirst:返回第一个元素,常与orElse一起用: Stream.findFirst().orElse(null):返回第一个,如果没有则返回null
allMatch:检查是否匹配所有元素:Stream.allMatch(str->str.equals("a"))
anyMatch:检查是否至少匹配一个元素.
3.Stream的特性
1.中间操作惰性执行:一个流后面可以跟随0到多个中间操作,主要目的是打开流,并没有真正的去计算,而是做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作都是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历,并没有消耗资源。
还有多个中间操作的话,这里的时间复杂度并不是n个for循环,转换操作都是 lazy 的,多个转换操作只会在 Terminal 操作的时候融合起来,一次循环完成。可以这样简单的理解,Stream 里有个操作函数的集合,每次转换操作就是把转换函数放入这个集合中,在Terminal操作的时候循环 Stream 对应的集合,然后对每个元素执行所有的函数。
2.流的末端操作只能有一次: 当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。之后如果想要操作就必须新打开流。
关于流被关闭不能再操作的异常:
这里曾经遇到过一个错误:stream has already been operated upon or closed
意思是流已经被关闭了,这是因为当我们使用末端操作之后,流就被关闭了,无法再次被调用,如果我们想重复调用,只能重新打开一个新的流。
以上是 java8 Stream常用方法和特性浅析 的全部内容, 来源链接: utcz.com/z/390478.html