笔记之_java整理hibernate

页面调试数据:<%@taglib uri="/struts-tags" prefix="s" %>
<s:debug></s:debug>
Js清除缓存
使用hibernate延迟加载时,并且数据库有关联关系,转换成json对象时不能直接转换,要用new JSONObject(),然后put()方法存值
国外框架项目地址:http://websystique.com/springmvc/spring-mvc-4-angularjs-example/
Angularjs文本输入框用ng-moduel,其他的用{{ }}
放行用.*?
Angularjs插件地址http://www.cnblogs.com/pilixiami/p/5634405.html
UI班的教程:http://pan.baidu.com/share/link?shareid=4146906997&uk=866705889
非严格读写是并发的概念
Spring不支持多线程
Flush()强制要求缓存与数据库一致
Eache表连接,lazy子查询
ORM:
编写程序时,以面向对象的方式处理数据
保存数据时是以关系型数据库的方式存储的
Hibernate的数据持久化:
New实例化对象时默认是瞬时的
Jdbc连接数据库时,持久化数据
将数据存入硬盘
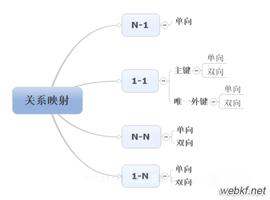
单向关联关系:
一个类单方向包含另一个类为属性,模拟数据库外键
mysql数据库附加:
String driver=com.mysql.jdbc.Driver
String url=jdbc:mysql://localhost:3306/demo
hibernate注入:
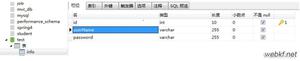
实体类
(1)这个表示一个实体类,Table表示对应数据库中的表名。
@Entity
@Table(name="t_emp")
(2)这个表示主键自动增长
mysql数据库
@Id
@GeneratedValue
oracle数据库
@Id
@SequenceGenerator(name = "FLINKSEQ", sequenceName = "flink_seq", initialValue = 1, allocationSize = 1)
@GeneratedValue(strategy = GenerationType.SEQUENCE, generator = "FLINKSEQ")
(3)这个表示关联对象以及关联的字段名字
@ManyToOne
@JoinColumn(name="dept_id")
@OneToMany(mappedBy="flinkType") //主表实体类映射关系
(4)和数据库中字段不一样的,要通过这个属性写清楚。
@Column(name="emai")
(5)表示时间字段
@Temporal(TemporalType.TIMESTAMP)
和@Temporal(TemporalType.DATE)
Dao.impl包中:
@Repository实体类数据访问层实现,放在类上
Service.impl包中:
@Service实体类业务逻辑层实现,放在类上
@Resource(name="flinkTypeDaoImpl")属性注入值放在setter方法上
Controller包中:
@Controller 是servlet标志,放在类上
@Scope(value="prototype") 每次实例化,放在类上
@Resource(name="flinkTypeServiceImpl")赋值,属性的setter方法上
测试类:放测试类上
@ContextConfiguration(locations="classpath:applicationContext.xml")
@RunWith(value=SpringJUnit4ClassRunner.class)
struts传参:
getter方法
ActionContext.getContext().getContextMap().put("arrLinks", arrLinks);
struts页面取值:
#r.id
id
@manyTomany必须有第三个表为中间表,命名为中间表的表名为:表名_表名2,命名不规范要@ManyToMany(mappedBy="表名")
在hibernate中分页参数与mysql一致,排除几笔取几笔
Hibernate不用stringMVC而是用ORM框架
Mybaties连接数据库用的数据库连接池是dbcp,而hibernate用c3p0
Hibernate连接数据库还要面包切的jar包
Hibernate实体类的生命周期:
瞬时状态:刚用new语句创建,还没有被持久化,且不处于session的缓存中
持久状态:已被持久化,且加入到session缓存中,执行了update()或save()方法时
游离状态:已经被持久化,但是不再处于session缓存中
jdbc与hibernate区别 ?
JDBC与hibernate在性能上相比,JDBC灵活性有优势。
而Hibernate在易学性,易用性上有些优势。
当用到很多复杂的多表联查和复杂的数据库操作时,JDBC有优势。
相同点:
两者都是Java的数据库操作。
两者对于数据库进行直接操作的对象都不是线程安全的,都需要及时关闭。
两者都可以对数据库的更新操作进行显式的事务处理。
不同点:
使用的SQL语言不同:
JDBC使用的是基于关系型数据库的标准SQL语言,
Hibernate使用的是HQL(Hibernate query language)语言
操作的对象不同:
JDBC操作的是数据,将数据通过SQL语句直接传送到数据库中执行,
Hibernate操作的是持久化对象,由底层持久化对象的数据更新到数据库中。
数据状态不同:
JDBC操作的数据是“瞬时”的,变量的值无法与数据库中的值保持一致,
而Hibernate操作的数据是可持久的,即持久化对象的数据属性的值是可以跟数据库中的值保持一致的。
has a 和 is a的区别?
has a 包含关系 (对象之间有关联关系)
is a 继承 (泛化关系)
JDBC与框架的区别:
Jdbc:
1)、要求sql比较精通
2)、对jdbc操作循环取值要细心,重复工作量很大
3)、对jdbc操作insert,update拼接字符串,要求细心
Hibernate: 不懂sql也没有太大的关系,只要按hibernate框架语法来操作就行了
2、要使用hiberante步骤
1)、配置核心的配置文件
Mybatis-->连接数据库,用户名,密码.....,调试sql
Hibernate-->也是一样的(名称 hibernate.cfg.xml)
2)、java实体类与数据库表建立映射关系
可能还会有 一对多, 多对一 多对多 一对一
Mybaits以接口为核心
CityMapper.java -->CityMapper.xml(自己写insert,update,delete,select)
Hiberante:以实体类为核心,insert,update,delete,select不会自己做
3)、编写工具类
Mybatis中取 SqlSessionFactory --> session --> 操作 -->(提交事务 可选)
Hibernate中取 SessionFactory -->session -->开启事务 -->操作-->提交事务
3、实体类与数据库表映射在hibernate中有2种写法
公司实际开发中,肯定是使用注解
学习中使用xml
4、hibernate日期格式
@Temporal(TemporalType.TIMESTAMP) yyyy-MM-dd hh:mm:ss
@Temporal(TemporalType.DATE) yyyy-MM-dd
@Temporal(TemporalType.TIME) hh:mm:ss
public Date getDtime() {
return dtime;
}
5、外键
Hibernate:
1:1 @OneToOne
1:n @OneToMany
N:1 @ManyToOne
N:M @ManyToMany
6、N:1 配置属性
@ManyToOne(fetch=FetchType.LAZY )
Fetch 检索加载的方式 EAGER 立即查询
LAZY 延迟加载(保证 session未关闭)
@JoinColumn(name="typeId") 外键列
7、配置核心hibernate.cfg.xml
<hibernate-configuration>
<session-factory>
1)、声明 你用的是哪种数据库 (断言 方言 hibernate.dialect)
2)、驱动包 hibernate.connection.driver_class
3)、用户名 hibernate.connection.username
4)、密码 hibernate.connection.password
5)、url hibernate.connection.url
6)、显示sql hibernate.show_sql=true/false
7)、是否自动维护表结构
hibernate.hbm2ddl.auto update
1)、none 不需要维护
2)、create-only 如果实体类有对象,数据库没有,就会创建
3)、drop 每次关闭项目就会删除所有的表
4)、create 每次启动都要重新创建表
5)、create-drop每次启动重新创建表,关闭时候删除所有表
6)、update 如果实体类与表结构不一致,就自动更新
7)、取得session的方式
hibernate.current_session_context_class thread
8)、在没有spring框架的情况下,必须把你定义好的带有注解的实体类,交给核心配置文件
<mapping class=”完整类路径” />
以后还有数据库连接池配置
</session-factory>
</hibernate-configuration>
8.sessionFactory.openSession()和sessionFactory.getCurrentSession()区别(面试题)
openSession() 打开以后,必须手动的关闭close();
getCurrentSession()打开以后,不需要关闭,交给当前应用自动管理,但是必须在hibernate.cfg.xml中配置
<property name="hibernate.current_session_context_class">thread</property>
9、使用hibernate增,删,改操作 语法
//1、创建Session
Session session=HibernateUtil.getCurrentSession();
//2、开启事务
Transaction trans=session.beginTransaction();
try {
操作
//提交
trans.commit();
} catch (Exception e) {
trans.rollback();
//回滚
e.printStackTrace();
}
不在事务执行范围内的操作没有效果
hibernate的get()和load()方法的区别:
1. 对于get方法,hibernate会确认一下该id对应的数据是否存在,首先在session缓存中查找,然后在二级缓存中查找,还没有就查询数据库,数据库中没有就返回null。
2. load方法加载实体对象的时候,根据映射文件上类级别的lazy属性的配置(默认为true),分情况讨论:
(1)若为true,则首先在Session缓存中查找,看看该id对应的对象是否存在,不存在则使用延迟加载,返回实体的代理类对象(该代理类为实体类的子类,由CGLIB动态生成)。等到具体使用该对象(除获取OID以外)的时候,再查询二级缓存和数据库,若仍没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
(2)若为false,就跟get方法查找顺序一样,只是最终若没发现符合条件的记录,则会抛出一个ObjectNotFoundException。
这里get和load有两个重要区别:
如果未能发现符合条件的记录,get方法返回null,而load方法会抛出一个ObjectNotFoundException。
load方法可返回没有加载实体数据的代理类实例,而get方法永远返回有实体数据的对象。
配置对外关系时:
@ManyToOne(fetch=FetchType.LAZY)子查询
@ManyToOne(fetch=FetchType.EAGER)表连接
双向关联关系:
private List<Flink> arrFlinks=new ArrayList<Flink>(0);
@OneToMany(mappedBy="linkType")
public List<Flink> getArrFlinks() {
return arrFlinks;
}
private FlinkType linkType; // 分类(唯一的)
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "typeId")
public FlinkType getLinkType() {
return linkType;
}
面试题权限操作 (下午看)
多用户多权限系统
用户名: Users (userId(PK) , userName)
角色表: Role( roleId(PK),roleName);
功能(菜单)表Func(funcId(PK), funcName, funcUrl, parentId(FK-->funcId), isShow);
角色用户表: role_user(id, userId(FK), foleId(FK))
角色功能表: role_func(id, roleId(FK), funcId(FK))
多用户单权限系统
用户名: Users (userId(PK) , userName, roleId(FK))
角色表: Role( roleId(PK),roleName);
功能(菜单)表 Func(funcId(PK), funcName, funcUrl, parentId(FK-->funcId), isShow);
角色功能表: role_func(id, roleId(FK), funcId(FK))
hibernate的查询方式:
hql查询:
Session session=sessionFactory.getCurrentSession();
Query query=session.createQuery(hql);
自定义sql查询:
Session session=sessionFactory.getCurrentSession();
SQLQuery sqlQuery=session.createSQLQuery(sql);
标准查询:
Session session=sessionFactory.getCurrentSession();
Criteria criteria=detachedCriteria.getExecutableCriteria(session);
分页查询:
.setFirstResult(firstResult); //起始数据
.setMaxResults(maxResults); //取得数据条数
hibernate在批量操作的时候,如何优化性能?
批量新增,批量修改,批量删除
一次性新增、删除、删除100个元素?
千万不要一次性新增到最后现去 提交,效率很低
每20个更新一次 session.flush() session.clear()
for(int i=0;i<100000;i++){
Monkey monkey=new Monkey(....);
session.save(monkey);
if(i%20==0){ //单批次操作的最大数量
session.flush();
session.clear();
}
}
为何这里写20不是其它的数字,可以去hibernate.batch_size=20
什么时候要用update,什么时候要用merge?
update():如果你确定在当前session的会话里不存在一个与要进行update操作有相同标识符(主键)的持久化对象,那么调用update()。
修改页面->根据id查询(session缓存中:id=2)-->页面(隐藏域放主键的=2)-->
editSave( new 实体类( id=2)) 这时候就会报异常了 (可以使用merge来解决,还可以使用,根据id查询时候,session.evict(obj) )
merge():如果你在任何时候修改了数据都想把数据保存到数据库中,那么就调用merge()。
查询条件:类型 下拉列表
String hql=“from Flink f where f.linkType.id=?” 对象导航查询
Sql: select * from Flnk f inner join FlinkType t on f.typeId=t.id
Where t.id=?
String hql=” from Flink f left out join fetch
f.linkType t
Where t.id=?”;
帮你生成 inner join
update和saveOrUpdate的区别?
update()修改根据主键数据库中的数据
saveOrUpdate()如果该对象未持久化(没有新增过)执行save方法,如果已经持久化了,那就执行update修改操作。
1、hibernate的三种状态之间如何转换
瞬时状态、持久状态、游离状态
当调用 save(),update() 对象变为持久化状态
当实例化对象,就是瞬时状态
当调用delete()游离状态,脱离了session都叫游离状态
3、session.clear(),session.evict(Object)
clear() 移出所有在session(一级缓存,只能在内存存在)管理的缓存
evict() 从session缓存中移出某个指定的对象
4、Hibernate工作原理及为什么要用?
原理:
1.读取并解析配置文件
2.读取并解析映射信息,创建SessionFactory
3.打开Sesssion
4.创建事务Transation
5.持久化操作
6.提交事务
7.关闭Session
8.关闭SesstionFactory (二级缓存,需要使用第三方框架)
为什么要用:
.对JDBC访问数据库的代码做了封装,大大简化了数据访问层繁琐的重复性代码。
.Hibernate是一个基于JDBC的主流持久化框架,是一个优秀的ORM实现。他很大程度的简化DAO层的编码工作
.hibernate使用Java反射机制。
.hibernate的性能非常好,因为它是个轻量级框架。映射的灵活性很出色。它支持各种关系数据库,从一对一到多对多的各种复杂关系。对缓存支持的
4.Hibernate是如何延迟加载?
. Hibernate2延迟加载实现:a)实体对象 b)集合(Collection)
. Hibernate3\4\5 提供了属性的延迟加载功能
当Hibernate在查询数据的时候,数据并没有存在与内存中,当程序真正对数据的操作时,对象才存在与内存中,就实现了延迟加载,他节省了服务器的内存开销,从而
提高了服务器的性能。
5.Hibernate中怎样实现类之间的关系?(如:一对多、多对多的关系)
类与类之间的关系主要体现在表与表之间的关系进行操作,它们都市对对象进行操作,我们程序中把所有的表与类都映射在一起,它们通过配置文件中的
many-to-one、one-to-many、many-to-many、
6.说下Hibernate的缓存机制
. 内部缓存存在Hibernate中又叫一级缓存(session),属于应用事物级缓存
. 二级缓存:(SessionFactory)
a) 应用及缓存
b) 分布式缓存
条件:数据不会被第三方修改、数据大小在可接受范围、数据更新频率低、同一数据被系统频繁使用、非关键数据
c) 第三方缓存的实现 (EhCache)
5. Hibernate的查询方式
Session.get() 立即加载
Session.load() 延迟加载
Sql、
Hql,
Criteria,
object comptosition (对象导航)
6. 如何优化Hibernate?
.使用双向一对多关联,不使用单向一对多
.灵活使用单向一对多关联
.不用一对一,用多对一取代
.配置对象缓存,不使用集合缓存
.表字段要少,表关联不要怕多,有二级缓存撑腰
7. get和load区别;
1)get如果没有找到会返回null, load如果没有找到会抛出异常。
2)get会先查一级缓存, 再查二级缓存,然后查数据库;
load会先查一级缓存,如果没有找到,就创建代理对象, 等需要的时候去查询二级缓存和数据库。
8. N+1问题。
Hibernate中常会用到
解决方法一个是延迟加载, 即lazy=true;
Select * from Flink -->FlinkType(延迟的)
当调用对象.getFlinkType() 才去查询
再发送一个select * from FlinkType where id=?
一个是预先抓取 FetchType.EAGER, 即; left join
11 persist()和save()的区别 (了解)
persist不保证立即执行,可能要等到flush;persist不更新缓存;
12 cascade,用来指示在主对象和它包含的集合对象的级联操作行为,即对住对象的更新怎么影响到子对象;
save-update: 级联保存(load以后如果子对象发生了更新,也会级联更新). 但它不会级联删除
delete: 级联删除, 但不具备级联保存和更新
all-delete-orphan: 在解除父子关系时,自动删除不属于父对象的子对象, 也支持级联删除和级联保存更新.
all: 级联删除, 级联更新,但解除父子关系时不会自动删除子对象.
delete-orphan:删除所有和当前对象解除关联关系的对象
13 session.commit 和flush区别,
commit会先调用flush 然后再执行clear(),然后提交事物;
flush() 强制地要求内存对象 与 数据库中的数据保持一致(同步)
flush 执行session,但不一定提交事物(因为事物可能被委托给外围的aop代理来做);
14 session清理的顺序: insert -> update -> delete -> 对集合进行delete -〉对集合的insert;
15 检索策略: 立即检索,lazy=false;延迟加载:lazy=true;预先抓取: fetch=“join”;
17、数据库事务
1)、四个特性
原子性、一致性,隔离性, 持久性
2)、事务隔离级别
Serializable: 串行化。隔离级别最高 4
Repeatable Read:可重复读 3(mysql)
Read Committed:已提交数据读 2 (oracle)
Read Uncommitted:未提交数据读。隔离级别最差 1
隔离级别越高的,数据精准性高,速度慢。
隔离级别越低的,查询速度快,但是数据精准性低.
1. 脏读: 对于两个事物 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的.
2. 不可重复读: 对于两个事物 T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
3. 幻读: 对于两个事物 T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行.
Read uncommitted 读未提交
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整,非常高兴。可是不幸的是,领导发现发给singo的工资金额不对,是2000元,于是迅速回滚了事务,修改金额后,将事务提交,最后singo实际的工资只有2000元,singo空欢喜一场。
出现上述情况,即我们所说的脏读,两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Read uncommitted时,就可能出现脏读,如何避免脏读,请看下一个隔离级别。
Read committed 读提交
singo拿着工资卡去消费,系统读取到卡里确实有2000元,而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到另一账户,并在singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为何......
出现上述情况,即我们所说的不可重复读,两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”,事务A事先读取了数据,事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Read committed时,避免了脏读,但是可能会造成不可重复读。
大多数数据库的默认级别就是Read committed,比如Sql Server , Oracle。如何解决不可重复读这一问题,请看下一个隔离级别。
Repeatable read 重复读
当隔离级别设置为Repeatable read时,可以避免不可重复读。当singo拿着工资卡去消费时,一旦系统开始读取工资卡信息(即事务开始),singo的老婆就不可能对该记录进行修改,也就是singo的老婆不能在此时转账。
虽然Repeatable read避免了不可重复读,但还有可能出现幻读。
singo的老婆工作在银行部门,她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额(select sum(amount) from transaction where month = 本月)为80元,而singo此时正好在外面胡吃海塞后在收银台买单,消费1000元,即新增了一条1000元的消费记录(insert transaction ... ),并提交了事务,随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上,却发现消费总额为1080元,singo的老婆很诧异,以为出现了幻觉,幻读就这样产生了。
3)锁机制
Mysql,sqlserver悲观锁: 当某个用户在操作的时候,其它用户不允许进行更新数据
锁整个表,锁行
Select * from 表 for update;(oracle乐观锁)
Select * from 表 where id=5 for update;
直接上一个用户 提交或者回滚记录才行
乐观锁:
大家都可进行操作,但是会以某一个列(timestamp 系统自动维护)
编号 值 version
1 test 2017-1-1 20:10:2.101
Update 表 set 值=‘a’ where 编号=1 and veresion=’ 2017-1-1 20:10:2.101’
Commit;
16、什么是Hibernate的并发机制?怎么去处理并发问题?
Hibernate并发机制:
a、Hibernate的Session对象是非线程安全的,对于单个请求,单个会话,单个的工作单元(即单个事务,单个线程),它通常只使用一次, 然后就丢弃。
如果一个Session 实例允许共享的话,那些支持并发运行的,例如Http request,session beans将会导致出现资源争用。
如果在Http Session中有hibernate的Session的话,就可能会出现同步访问Http Session。只要用户足够快的点击浏览器的“刷新”, 就会导致两个并发运行的线程使用同一个Session。
b、多个事务并发访问同一块资源,可能会引发第一类丢失更新,脏读,幻读,不可重复读,第二类丢失更新一系列的问题。
解决方案:设置事务隔离级别。
Serializable:串行化。隔离级别最高
Repeatable Read:可重复读
Read Committed:已提交数据读
Read Uncommitted:未提交数据读。隔离级别最差
设置锁:乐观锁和悲观锁。
乐观锁:使用版本号或时间戳来检测更新丢失,在的映射中设置 optimistic-lock=”all”可以在没有版本或者时间戳属性映射的情况下实现 版本检查,此时Hibernate将比较一行记录的每个字段的状态
行级悲观锁:Hibernate总是使用数据库的锁定机制,从不在内存中锁定对象!只要为JDBC连接指定一下隔 离级别,然后让数据库去搞定一切就够了
以上是 笔记之_java整理hibernate 的全部内容, 来源链接: utcz.com/z/390018.html