Python线程与进程 I/O多路复用

SSHClient Paramiko模块
远程执行命令
#用户名密码方式:import paramiko
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
ssh.connect(hostname='192.168.18.204',port=22,username='root',password='123456')
stdin,stdout,stderr=ssh.exec_command('df -h && ip a')
result=stdout.read()
print(result.decode())
ssh.close()
#密钥方式:
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('id_rsa')
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
ssh.connect(hostname='192.168.18.204',port=22,username='root',pkey=private_key)
stdin,stdout,stderr=ssh.exec_command('df -h && ip a')
result=stdout.read()
print(result.decode())
复制文件到服务端
#用户名密码方式:import paramiko
transport = paramiko.Transport(('192.168.18.204',22)) #必须为元组,否则端口不为22时(不输入时默认为22),会一直连接不上.
transport.connect(username='root',password='123456')
sftp=paramiko.SFTPClient.from_transport(transport)
sftp.put('./1.txt','/root/2.txt') #上传文件
sftp.get('/root/2.txt','./3.txt') #下载文件
transport.close()
#密钥方式:
import paramiko
private_key = paramiko.RSAKey.from_private_key_file('id_rsa')
transport=paramiko.Transport(('192.168.18.204',22))
transport.connect(username='root',pkey=private_key)
sftp=paramiko.SFTPClient.from_transport(transport)
sftp.get('/root/2.txt','./4.txt')
sftp.put('3.txt','/root/4.txt')
transport.close()
进程与线程的区别
进程与线程的区别:进程: 一个程序执行的实例,就是各种资源(内存页,文件描述符,Open Socket )的集合。
线程:是操作系统的最小的调度单位,是一串指令的集合,创建进程时会自动创建一个线程。
线程共享内存空间,可以互相访问。进程的内存空间是独立的,不能互相访问。
子进程相当于克隆一遍父进程。
进程要操作CPU,必须要创建一个线程,线程本身无法操作CPU。
进程快还是线程快,没有可比性,一个是资源的集合,另一个是执行任务的。
线程之间的可以直接交流,两个进程想通信,必须通过一个中间代理。
线程是独立的,不会像进程那样,杀了父进程子进程也会死掉。
主线程和其他线程是并行的。
简单的多线程示例
普通的调用方式
import timeimport threading
def run(n):
print('task',n)
time.sleep(2)
t1=threading.Thread(target=run,args=('t1',))
t2=threading.Thread(target=run,args=('t2',))
t1.start()
t2.start()
继承类的调用方式,并且计算所有线程的总耗时
import timeimport threading
class MyThread(threading.Thread):
def __init__(self,n):
super().__init__()
self.n=n
def run(self): #无法接收参数
print('task',self.n)
time.sleep(2)
res=[]
start_time=time.time()
for i in range(50):
t=MyThread('t-%s' %i)
res.append(t)
t.start()
for i in res:
i.join() #join会堵塞,等待线程结束。
print('总耗时: {}'.format(time.time()-start_time))
递归锁
threading.RLock() 多重锁,在同一线程中可用被多次acquire。如果使用RLock,那么acquire和release必须成对出现def run1():
print("grab the first part data\n")
lock.acquire() #如果使用的是threading.Lock(),此处就会卡住,因为一次只能一个锁定,其余锁请求,需等待锁释放后才能获取。
global num
num += 1
lock.release()
return num
def run3():
lock.acquire()
res = run1()
lock.release()
print(res, )
if __name__ == '__main__':
num= 0
lock = threading.RLock()
for i in range(1):
t = threading.Thread(target=run3)
t.start()
while threading.active_count() != 1: #线程数不等于1就继续等待
print(threading.active_count())
else:
print('----all threads done---')
print(num)
信号量
信号量,指定允许几个线程同时运行,但不是等待几个线程都结束了,才允许下一批线程允许,而是结束一个放进来一个。用于连接池一类。import threading, time
def run(n):
semaphore.acquire()
time.sleep(1)
print('run the thread: %s\n' %n)
semaphore.release()
if __name__ == '__main__':
semaphore = threading.BoundedSemaphore(3) #同一时间只允许3个线程同时存在
for i in range(20):
t = threading.Thread(target=run,args=(i,))
t.start()
while threading.active_count() != 1:
pass
else:
print('----all threads done---')
注:python多线程 不适合cpu密集型,适合io密集型任务,因为python的线程不支持使用多核,但是io不占用cpu,所以适合io密集型。
Python多进程,适合cpu密集型,因为进程可以使用多核。
Event,线程之间的交互。
import threadingimport time
event=threading.Event()
def Traffic_lights():
event.set()
count=0
while True:
if count >=5 and count <10:
event.clear()
elif count >=10:
event.set()
count = 0
count += 1
time.sleep(1)
def car():
while True:
if event.is_set():
print('\033[36;1m变绿灯了\033[0m\n')
print('\033[36;1m宝马车开始运行\033[0m\n')
time.sleep(1)
else:
print('\033[31;1m变红灯了\033[0m\n')
print('\033[31;1m宝马车停止运行\033[0m\n')
event.wait()
t1=threading.Thread(target=Traffic_lights)
t1.start()
c1=threading.Thread(target=car)
c1.start()
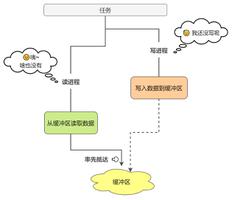
Queue队列
优点:解耦,提高效率
列表与队列的区别:列表取出一个数据,数据还存在在列表中,队列取出数据后则会删除队列中的数据。
线程Queue:import queue
q=queue.Queue(maxsize=3) #maxsize可以设置队列长度,先进先出。
q=queue.LifoQueue(maxsize=3) #后进先出。
q=queue.ProiorityQueue(maxsize=3) #可以设置存储优先级,put时使用元组q.put((-1,'zyl')),优先级是从小到大。
q.put() #存放数据
q.qsize() #查看队列大小
q.get() #取出数据,如果没有数据会一直卡住,
q.get_nowait() #取出数据,如果没有数据会报一个异常,或者使用q.get(block=False)
进程Queue:
为什么子进程可以访问到,过程是:有两个Queue,子进程向它的Queue,Put数据通过picket序列化,然后复制到父类Queue,同时删除自身的数据,反之亦然。
from multiprocessing import Queue
import multiprocessing
def run(q2):
q2.put('1')
if __name__ == '__main__':
q=Queue()
P=multiprocessing.Process(target=run,args=(q,))
P.start()
#其他选项与线程Queue相同。
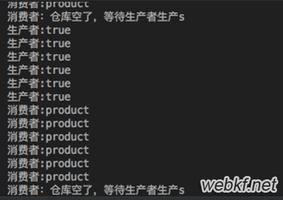
生产者消费者模型
import threadingimport time
import queue
q=queue.Queue(maxsize=10)
def producer(name):
i=1
while True:
q.put('汽车 {}'.format(i))
print('生产了汽车%s' %i)
i+=1
def consumer(name):
while True:
print('{} 开走了{}'.format(name,q.get()))
time.sleep(1)
p1=threading.Thread(target=producer,args=('zyl',))
c1=threading.Thread(target=consumer,args=('wq',))
c2=threading.Thread(target=consumer,args=('syf',))
p1.start()
c1.start()
c2.start()
pipe管道(类似与Queue)
from multiprocessing import Process,Pipedef run(conn):
conn.send([1,2])
print(conn.recv())
conn.close()
if __name__ == '__main__':
parent_conn,child_conn=Pipe() #生成两个连接,将子连接传给子进程。
P=Process(target=run,args=(child_conn,))
P.start()
print(parent_conn.recv())
parent_conn.send([4,5])
P.join()
Manager
进程之间的数据共享。管道和Queue只是传递。
import osfrom multiprocessing import Process,Manager
def run(d,l):
d['b'] = '2'
l.append(os.getpid())
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list(range(5)) #初始五个数字
p_list=[]
for i in range(10):
P=Process(target=run,args=(d,l))
P.start()
p_list.append(P)
for res in p_list:
res.join() #等待所有进程执行完毕
print(d)
print(l)
进程锁
from multiprocessing import Process,Lockdef run(l,i):
l.acquire()
try:
print('hellow word',i)
finally:
l.release()
if __name__ == '__main__':
lock=Lock()
for num in range(10):
Process(target=run,args=(lock,num)).start()
进程池
from multiprocessing import Process,Poolimport time
import os
def run(i):
time.sleep(2)
print('in process',os.getpid())
return i+100
def Bar(arg):
print('==>exec done:',arg)
if __name__ == '__main__': #windows上必须写这句话
pool=Pool(processes=5)
for num in range(15):
pool.apply_async(func=run,args=(num,),callback=Bar) #callback,回调函数,进程执行完毕后,由主进程执行这个函数。
print('全部开启')
pool.close() #必须要先close在关闭。
pool.join()
协程
#gevent,遇到io自动切换。#gevent默认不知道urllib和socket会进行io操作。解决方法:
from gevent import monkey #对所有进行i/o的操作打上一个标记
monkey.patch_all()
示例(一),下载网页:
from urllib import request
import gevent,time
from gevent import monkey
monkey.patch_all()
def f(url):
print('下载网页:',url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:23.0) Gecko/20100101 Firefox/23.0'} ##防止403错误
req=request.Request(url=url,headers=headers)
data=request.urlopen(req).read()
print('%d bytes received from %s.' %(len(data),url))
urls=[
'https://pythonwheels.com/',
'https://www.yahoo.com/',
'https://github.com'
]
start=time.time()
for url in urls:
f(url)
print('同步cost',time.time()-start)
async_start=time.time()
gevent.joinall([
gevent.spawn(f,'https://pythonwheels.com/'),
gevent.spawn(f,'https://www.yahoo.com/'),
gevent.spawn(f,'https://github.com')
])
print('异步cost:',time.time()-async_start)
示例(二),通过gevent实现一个Socket:
import sys
import socket
import time
import gevent
from gevent import socket, monkey
monkey.patch_all()
def server(port):
s = socket.socket()
s.bind(('0.0.0.0', port))
s.listen(500)
while True:
cli, addr = s.accept()
gevent.spawn(handle_request, cli)
def handle_request(conn):
try:
while True:
data = conn.recv(1024)
print("recv:", data)
conn.send(data)
if not data:
conn.shutdown(socket.SHUT_WR)
except Exception as ex:
print(ex)
finally:
conn.close()
if __name__ == '__main__':
server(8001)
事件驱动和异步IO
1.事件驱动模型就是根据一个事件来做反应,类似于生产者消费者模型。 gevent就是使用了事件驱动模型,遇到I/O时注册一个事件,然后系统执行I/O,在I/O操作完毕后回调一个事件告诉gevent,它之前注册的事件执行完毕了。
2.缓存I/O,数据会先被拷贝到操作系统的内核缓冲区(内存),然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间(内存)。内核态就是内核空间到用户空间。
缺点是:“数据在传输过程中要在应用程序地址空间和内核进行多次数据拷贝”,为什么这么做因为用户空间无法操作系统,只能调用操作系统的接口,来完成这次操作。
3.堵塞I/O的意思是,客户端继承使用recvfrom调用kernel,来查看是否有数据,有的话返回数据,没有的话就会一直等待它有数据。
4.非堵塞I/O的意思是,客户端继承使用recvfrom调用kernel,来查看是否有数据,有的话返回数据,没有的话就会返回一个错误(error),然后客户端再次调用kernel来查看是否有数据,有的话返回数据,没有的话就会返回一个错误(error),陷入循环。所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有。
5.在单个线程中,如果使用的是堵塞I/O是没法实现多路I/O。
6.在单个线程中,如果使用的是非堵塞I/O,是可以实现多路I/O的。单线程下如果有100个连接,使用的是非堵塞模式的话,说不准那个数据先到,所以就循环收取。某个连接没有数据是他会返回一个(error),不会等待,但是还是会在从内核态复制数据到用户态时间卡住。
7.I/O多路复用的特点是一个线程可以同时等待多个文件描述符(socket),其中任意一个进入就绪状态,select()函数就可以返回。返回时并不会告诉进程是哪一个连接有数据了,可以通过select,pool,epool来查看。
8.异步I/O,用户进程多个连接发起read之后,立刻就可以干别的事情。Kernel来帮你等待数据,然后将数据拷贝到用户内存。返回时并不会告诉进程是哪一个连接有数据了。
select poll epoll的区别,全部应用在I/O多路复用状态。
1.select单进程打开的默认可以打开的文件数量是1024,调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。
2.poll和select的区别不大,取消了最大打开文件数量。
3.epool只有linux支持,与select的区别是在异步I/O中如果有一个连接活跃了,kernel会告诉进程是哪一个连接活跃了,没有最大连接限制。`水平触发`就是数据在内核态已经准备完毕了,但是进程没有调用read去取。数据会一直保留在内核态。下次再有数据,会再次告诉进程数据准备完毕了。`边缘触发`就是数据在内核态已经准备完毕了,但是进程没有调用read去取。数据会一直保留在内核态。下次再有数据,不会再次告诉进程数据准备完毕了。
4.nginx其实是I/O多路复用。
Python3里的模块asyncio支持异步i/o.
select
Python的select()方法直接调用操作系统的IO接口,它监控sockets,open files, and pipes(所有带fileno()方法的文件句柄)何时变成readable 和writeable, 或者通信错误,select()使得同时监控多个连接变的简单,并且这比写一个长循环来等待和监控多客户端连接要高效,因为select直接通过操作系统提供的C的网络接口进行操作,而不是通过Python的解释器。
示例:使用select(I/O多路复用)实现socketServer。import select #底层做了封装,可以直接返回活动的连接
import socket
import sys
import queue
server=socket.socket()
server.setblocking(0) #设置为非堵塞
server.bind(('localhost',9999))
server.listen(10)
inputs=[server,]
outputs=[]
message_queues={}
while True:
readable,writeable,exeptional=select.select(inputs,outputs,inputs) #select()方法接收并监控3个通信列表, 第一个是要监控哪些连接,刚开始时监控自身,第2个是监控和接收所有要返回给客户端的data(outgoing data),第3个监控那些连接的错误信息,
#readable 返回活动的连接
for s in readable:
if s is server: #如果是server的话代表有新连接进来了
conn,client_addr=s.accept()
inputs.append(conn) #将新连接添加到监控列表
message_queues[conn]=queue.Queue()
else: #s不是server的话,那就只能是一个 与客户端建立的连接的fd了,客户端的数据过来了,在这接收。
data=s.recv(1024)
if data:
print("收到来自[%s]的数据:"%s.getpeername()[0],data)
message_queues[s].put(data) #将用户数据存储到Queue中
if s not in outputs:
outputs.append(s)
else:
print('客户端断开了: ',s)
if s in outputs:
outputs.remove(s)
inputs.remove(s)
#writeable 存储要返回给用户数据的连接
for s in writeable:
try:
msg=message_queues[s].get_nowait()
except queue.Empty:
outputs.remove(s)
else:
s.send(msg)
#exeptional 存储出现错误的连接
for s in exeptional:
print("handling exception for ",s.getpeername())
inputs.remove(s)
if s in outputs:
outputs.remove(s)
s.close()
del message_queues[s]
selectors模块
此模块根据系统的不同,会使用不同的方式,Linux优先使用epoll
import selectorsimport socket
sel=selectors.DefaultSelector()
def accept(sock,mask):
conn,addr=sock.accept()
print('accepted', conn, 'from', addr)
conn.setblocking(False)
sel.register(conn, selectors.EVENT_READ, read) ##新连接注册read回调函数
def read(conn, mask):
data = conn.recv(1000) # Should be ready
if data:
print('echoing', repr(data), 'to', conn)
conn.send(data.upper()) # Hope it won't block
else:
print('closing', conn)
sel.unregister(conn) #移除注册的连接
conn.close()
sock = socket.socket()
sock.bind(('localhost', 10000))
sock.listen(100)
sock.setblocking(False)
sel.register(sock, selectors.EVENT_READ, accept)
while True:
events = sel.select() #默认阻塞,有活动连接就返回活动的连接列表
for key, mask in events:
callback = key.data #callback相当于accept函数
callback(key.fileobj, mask) #key.fileobj是客户端socket
每日练习
简单主机批量管理工具
(1). 主机分组
(2). 主机信息配置文件用configparser解析
(3). 可批量执行命令、发送文件,结果实时返回,执行格式如下
batch_run -h h1,h2,h3 -g web_clusters,db_servers -cmd "df -h"
batch_scp -h h1,h2,h3 -g web_clusters,db_servers -action put -local test.py -remote /tmp/
(4). 主机用户名密码、端口可以不同
(5). 执行远程命令使用paramiko模块
(6). 批量命令需使用multiprocessing并发
配置文件
#这是主机管理系统的配置文件;#[],里面包含组名,组管理着多台主机
#[],下面是包含在组内的主机信息,主机信息格式: 主机名=['ip:port','user_name','passwd']
[TestColony]
test01=['192.168.18.195:666','root','12345678']
test02=['192.168.18.187:7878','zyl','123456qwe']
[Python3]
Python3=['192.168.109.88:22','root','qazwsxedc']
运行Py
import timeimport shlex
import configparser
import threading
import paramiko
import os
instructions_dict={
'batch_run':['-h','-g','-cmd','help'],
'batch_scp':['-h','-g','-action','-local','-remote','help'],
}
class HOST_MANAGE(object):
def __init__(self):
print('\033[36;1m欢迎使用批量管理主机系统\033[0m'.center(50, '*'))
print('\033[36;1m下面是该系统的使用方法;\n(1)根据序号显示群组下的主机信息\
\n(2)命令名称 help 获取命令帮助;\033[0m')
print('\033[36;1m群组信息\033[0m'.center(50, '='))
def batch_run_help(self):
'''
显示batch_run命令帮助信息
:return:
'''
print('\033[36;1mbatch_run 远程执行命令;\
\n-h:指定单独的主机序号,使用逗号分割;\
\n-g:指定群组命令会发送到该群组下所有机器,使用逗号分割;\
\n-cmd:指定命令,使用引号将命令包裹;\033[0m')
def batch_scp_help(self):
'''
显示batch_scp命令帮助信息
:return:
'''
print('\033[36;1mbatch_scp 文件的上传与下载;\
\n-h:指定单独的主机,使用逗号分割;\
\n-g:指定群组命令会发送到该群组下所有机器,使用逗号分割;\
\n-action:指定动作,put:复制本地文件到远程机器,get;将远程主机文件复制到本地;\
\n-local:本地路径\
\n-remote:远程路径\033[0m')
def batch_run(self,parameter,GroupInfo,*args,**kwargs):
'''
此方法用于解析参数,执行命令
:param parameter: 命令参数
:param GroupInfo: 主机信息
:param args:
:param kwargs:
:return:
'''
host_info=set()
args=[ i for i in parameter.keys()]
if 'help' in args:
self.batch_run_help()
return True
elif '-h' not in args:
print('缺少关键参数: -h')
return False
elif '-cmd' not in args:
print('缺少关键参数: -cmd')
return False
for i in parameter['-h'].split(','):
if not i.isdigit() or int(i)-1 not in range(len(parameter)):
print('-h 参数错误,没有序号为%s的主机' %i)
return False
else:
i=int(i)-1
host_list_info=eval(GroupInfo[i][1])
host_info.add('{}:{}:{}'.format(host_list_info[0],host_list_info[1],host_list_info[2]))
res=[]
return_info=[]
for i in host_info:
ip, port, user, passwd, = [ i for i in i.split(':') ]
t=threading.Thread(target=self.run_shell,args=(ip,port,user,passwd,parameter['-cmd'],return_info))
res.append(t)
t.start()
for j in res:
j.join()
for k,v in return_info:
print('{}'.format(k).center(50,'='))
print(v.decode())
return True
def batch_scp(self,parameter,GroupInfo,*args,**kwargs):
'''
此方法,用于解析参数,生成线程执行复制文件的操作
:param parameter:
:param GroupInfo:
:param args:
:param kwargs:
:return:
'''
host_info=set()
args=[ i for i in parameter.keys()]
if 'help' in args:
self.batch_scp_help()
return True
elif '-h' not in args:
print('缺少关键参数: -h')
return False
elif '-action' not in args:
print('缺少关键参数: -action')
return False
elif '-local' not in args:
print('缺少关键参数: -local')
return False
elif '-remote' not in args:
print('缺少关键参数: -remote')
return False
for i in parameter['-h'].split(','):
if not i.isdigit() or int(i)-1 not in range(len(parameter)):
print('-h 参数错误,没有序号为%s的主机' %i)
return False
else:
i=int(i)-1
host_list_info=eval(GroupInfo[i][1])
host_info.add('{}:{}:{}:{}:{}:{}'.format(host_list_info[0],host_list_info[1],host_list_info[2],parameter['-local'],parameter['-remote'],parameter['-action']))
print(host_info)
res=[]
for i in host_info:
ip,port,user,passwd,local,remote,action,=[ i for i in i.split(':') ]
if action == 'put':
if os.path.isfile(local):
local=os.path.abspath(local)
else:
print('本地没有此文件: ',local)
return False
elif action != 'get':
print('\033[31;1m -action 参数值错误,请重新输入!\033[0m')
return False
t=threading.Thread(target=self.scp_file,args=(ip,port,user,passwd,local,remote,action))
res.append(t)
t.start()
for j in res:
j.join()
return True
def scp_file(self,*args,**kwargs):
'''
此方法用于复制文件到远程主机,args接收了ip,port等信息。
:param args:
:param kwargs:
:return:
'''
ip, port, user, passwd, local, remote,action=[ i for i in args[:] ]
try:
transport = paramiko.Transport((ip,int(port)))
transport.connect(username=user,password=passwd)
sftp=paramiko.SFTPClient.from_transport(transport)
if action == 'put':
sftp.put(local,remote)
else:
sftp.get(remote,local)
print('{}:传输完毕'.format(ip).center(50, '='))
transport.close()
except Exception as e:
print('\033[31;1m复制文件失败,以下是错误信息\033[0m')
print('错误信息: {}'.format(e))
return False
else:
return True
def run_shell(self,*args, **kwargs):
ip,port,user,passwd,cmd,return_info=[ i for i in args[:] ]
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy)
try:
ssh.connect(hostname=ip, port=int(port), username=user, password=passwd)
stdin,stdout,stderr=ssh.exec_command(cmd)
if not stderr:
return_info.append((ip, stderr.read()))
else:
return_info.append((ip, stdout.read()))
ssh.close()
except Exception as e:
print('\033[31;1m执行命令失败,以下是错误信息\033[0m')
print('错误信息: {}'.format(e))
return False
else:
return True
def Analytical_command(self,instruction,*args,**kwargs):
'''
用于解析命令的方法,返回命令和参数
:param instruction:
:param args:
:param kwargs:
:return:
'''
command = instruction.split(' ')[0]
parameter = {key:value for key, value in zip(shlex.split(instruction)[1::2], \
shlex.split(instruction)[2::2] if len(shlex.split(instruction)[2::2]) != 0 else (None,))}
err_arg = []
if command in instructions_dict:
for arg in parameter.keys():
if arg not in instructions_dict[command]:
err_arg.append(arg)
if len(err_arg) == 0:
return command,parameter
else:
print('\033[31;1m没有此参数: {};请使用{} help获取帮助\033[0m'.format(err_arg,command))
return False
elif command == 'q':
return command
else:
print('\033[31;1m没有{}命令\033[0m'.format(command))
return False
def print_GroupInfo(self):
'''
此方法用于打印配置文件中的,群组信息,主机信息,返回组名和主机信息
:return:
'''
config = configparser.ConfigParser()
config.read('../conf/Batch_host.conf',encoding='utf-8')
GroupInfo=config.sections()
while True:
for k,v in enumerate(GroupInfo,start=1):
print('\033[35;1m({}).{}\033[0m'.format(k,v))
select_group=input('>>: ')
if select_group.isdigit() and int(select_group) >=1 and int(select_group) <= len(GroupInfo):
HostInfo=config.items(GroupInfo[int(select_group)-1])
print('\033[36;1m主机信息\033[0m'.center(50, '='))
for k,v in enumerate(HostInfo,start=2):
print('\033[34;1m({}).{}: {}\033[0m'.format(k,v[0],eval(v[1])[0]))
return GroupInfo[int(select_group)-1],HostInfo
elif select_group == 'q':
exit()
else:
print('\033[31;1m没有此群组!\033[0m')
continue
manage=HOST_MANAGE()
while True:
GroupInfo=manage.print_GroupInfo()
while True:
instruction = input('[%s]>>: ' %GroupInfo[0]).strip()
result=manage.Analytical_command(instruction)
if type(result) == tuple:
getattr(manage,result[0])(result[1],GroupInfo[1])
elif result == 'q':
break
else:
continue
以上是 Python线程与进程 I/O多路复用 的全部内容, 来源链接: utcz.com/z/388960.html