【语言处理与Python】2.1获取文本语料库

古藤堡语料库(电子文本档案经过挑选的一小部分文本)
#语料库中所有的文件
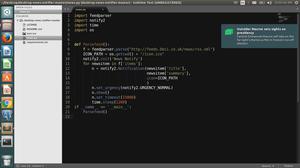
Import nltkNltk.corpus.gutenberg.fileids()
From nltk.corpus import Gutenberg
Gutenberg.fileids()
Emma=Gutenberg.words(‘austen-emma.txt’)
#挑选其中的某一部著作进行操作
Emma=nltk.corpus.gutenberg.words(‘austen-emma.txt’)Num_chars=len(Gutenberg.raw(fileid))
Num_words=len(Gutenberg.words(fileid))
Num_sents=len(Gutenberg.sents(fileid))
Num_vocab=len(set([w.lower() for w in Gutenberg.words(fileid)]))
网络和聊天文本
From nltk.corpus import webtextFrom nltk.corpus import nps_chat
布朗语料库
#对布朗语料库的一些操作:
From nltk.corpus import brownBrown.categories()#语料库的一些分类
Brown.words(categories=’news’)#访问某一文体的单词
Brown.words(fields=[‘cg22’])
Brown.sents(categories=[‘news’,’editorial’,’reviews’])
#使用条件频率分布做一些统计
Cfd=nltk.ConditionalFreqdist(
(genre,word)
For genre in brown.categories()
For word in brown.words(categories=genre)
)
Genres=[‘news’,’religion’,’hobbies’,’science_fiction’,’’romance’,’humor’]
Modals=[‘can’,’could’,’may’,’might’,’must’m’will’]
Cfd.tabulate(conditions=generes,samples=modals)
路透社语料库(新闻文档,分成了90个主题,按照训练和测试分为两组)
就职演说语料库
#使用条件分布做一些统计工作Cfd=nltk.ConditionalFreqdist(
(target,fileid[:4])
For fileid in inaugural.fileids()
For w in inaugural.words(fileid)
For target in [‘america’,’citizen’]
If w.lower().startswith(target)
)
Cfd.plot()
标注文本语料库(含有语言学标注,词性标注、命名实体、句法结构、语义角色等)
在其他语言的语料库
文本语料库的结构
载入自己的语料库
#在一些地方可以用匹配符号From nltk.corpus import PlaintextCorpusReader
Corpus_root=’/usr/share/dict’
Wordlists=PlaintextCorpusReader(corpus_root,’.*’)
Wordlists.fileids()
Wordlists.words(‘connectives’)
#在硬盘上的语料库
From nltk.corpus import BracketParseCorpusReader
Corpus_root=r”C:\corpura\penntreebank\parsed\mrg\wsj”
File_pattern=r”.*/wsj_.*\.mrg”
Ptb=BracketParseCorpusReader(corpus_root,file_pattern)
Ptb.fileids()
以上是 【语言处理与Python】2.1获取文本语料库 的全部内容, 来源链接: utcz.com/z/388958.html