Python爬取17吉他网吉他谱

最近学习吉他,一张一张保存吉他谱太麻烦,写个小程序下载吉他谱。
安装 BeautifulSoup,BeautifulSoup是一个解析HTML的库。
pip install BeautifulSoup4
在这个程序中 BeautifulSoup 使用 html5lib 所以还要安装 html5lib
pip install html5lib
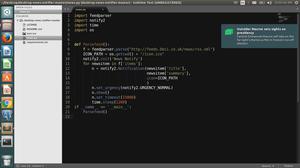
代码如下:
# -*- coding: utf-8 -*-#coding=UTF8
import os
import sys
import logging
import urllib
import urllib2
import chardet
import re
import cookielib
import urlparse
from bs4 import BeautifulSoup
sysEncoding = sys.getfilesystemencoding()
cookieJar = cookielib.CookieJar()
def get(url):
req = urllib2.Request(url)
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
response = opener.open(req)
return response.read()
def download_guitar_image(url, target):
print 'start download guitar image ...'
req = urllib2.Request(url)
req.add_header('Accept','image/webp,image/*,*/*;q=0.8')
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cookieJar))
response = opener.open(req)
content = response.read()
with open(target, 'wb') as code:
code.write(content)
#解析吉他谱图片页面链接地址
def parse_guitar_img_link():
page_list = []
url_base = 'http://www.17jita.com/'
page = 1
while True:
url = url_base + 'tab/img/index.php?page=' + str(page)
print url
html = get(url)
soup = BeautifulSoup(html, "html5lib")
list = soup.select('#ct dl > dt > a')
if not list:
break
for item in list:
page_list.append({ 'title' : item.text, 'link' : url_base + item['href'] })
page += 1
return page_list
def download_guitar_image_link_list(url):
image_link_list = []
page = 1
while True:
page_url = url
if page > 1:
page_url = url.replace('.html', '' + str(page) + '.html')
try:
html = get(page_url)
soup = BeautifulSoup(html, 'html5lib')
img_list = soup.select('#article_contents a > img')
for img in img_list:
image_link_list.append(img['src'])
except urllib2.URLError, e:
msg = u'下载 ' + page_url + u' 出错, 原因: ' + e.reason
print msg
logging.error(msg)
break
page += 1
return image_link_list
if __name__ == '__main__':
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='guitar.log',
filemode='a')
path = 'guitar'
if not os.path.exists(path):
os.mkdir(path)
page_list = parse_guitar_img_link()
for page in page_list:
print page['link'] + '(' + page['title'] + ')'
guitar_path = path + '/' + (page['title']).encode('GBK')
if not os.path.exists(guitar_path):
os.mkdir(guitar_path)
image_link_list = download_guitar_image_link_list(page['link'])
for image_link in image_link_list:
print '\t' + image_link
filename = image_link[image_link.rindex('/'):]
filepath = guitar_path + filename.encode('GBK')
download_guitar_image(image_link, filepath)
程序中还存在一些问题尚优化,比如下载中断,不能下载剩下的吉他谱。
以上是 Python爬取17吉他网吉他谱 的全部内容, 来源链接: utcz.com/z/388858.html