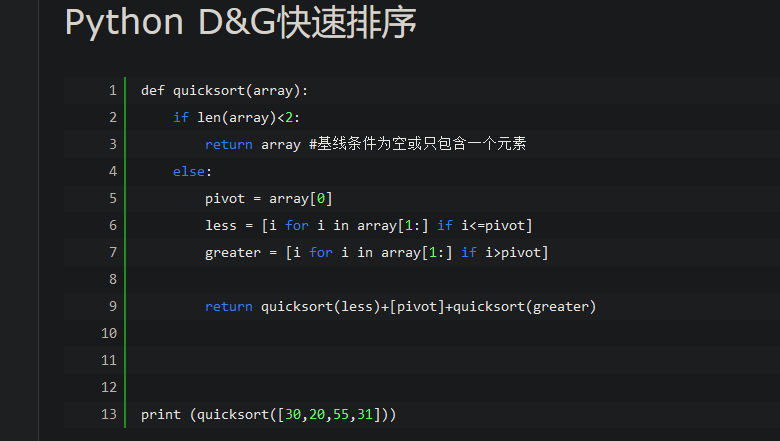
基于队列实现生产者消费者(Python)

# 进城之间数据隔离# 进程之间通信(IPC) Inter Process communication
# 基于文件 :同一台机器上的多个进程之间通信
# Queue 队列
# 基于socket的文件级别的通信来完成数据传递的
# 基于网络 :同一台机器或者多台机器上的多进程间通信
# 第三方工具(消息中间件)
# memcache
# redis
# rabbitmq
# kafka
# from multiprocessing import Queue,Process
# def pro(q):
# for i in range(10):
# print(q.get())
# def son(q):
# for i in range(10):
# q.put('hello%s'%i)
#
# if __name__ == '__main__':
# q = Queue()
# p = Process(target=son,args=(q,))
# p.start()
# p = Process(target=pro, args=(q,))
# p.start()
# 生产者消费者模型
# 爬虫的时候
# 分布式操作 : celery
# 本质 :就是让生产数据和消费数据的效率达到平衡并且最大化的效率
# import time
# import random
# from multiprocessing import Queue,Process
#
# def consumer(q): # 消费者:通常取到数据之后还要进行某些操作
# for i in range(10):
# print(q.get())
#
# def producer(q): # 生产者:通常在放数据之前需要先通过某些代码来获取数据
# for i in range(10):
# time.sleep(random.random())
# q.put(i)
#
# if __name__ == '__main__':
# q = Queue()
# c1 = Process(target=consumer,args=(q,))
# p1 = Process(target=producer,args=(q,))
# c1.start()
# p1.start()
import time
import random
from multiprocessing import Queue,Process
def consumer(q,name): # 消费者:通常取到数据之后还要进行某些操作
while True:
food = q.get()
if food:
print('%s吃了%s'%(name,food))
else:break
def producer(q,name,food): # 生产者:通常在放数据之前需要先通过某些代码来获取数据
for i in range(10):
foodi = '%s%s'%(food,i)
print('%s生产了%s'%(name,foodi))
time.sleep(random.random())
q.put(foodi)
if __name__ == '__main__':
q = Queue()
c1 = Process(target=consumer,args=(q,'alex'))
c2 = Process(target=consumer,args=(q,'alex'))
p1 = Process(target=producer,args=(q,'大壮','泔水'))
p2 = Process(target=producer,args=(q,'b哥','香蕉'))
c1.start()
c2.start()
p1.start()
p2.start()
p1.join()
p2.join()
q.put(None)
q.put(None)
以上是 基于队列实现生产者消费者(Python) 的全部内容, 来源链接: utcz.com/z/387693.html