Python 爬虫入门(四)—— 验证码下篇(破解简单的验证码) - 不剃头的一休哥

年前写了验证码上篇,本来很早前就想写下篇来着,只是过年比较忙,还有就是验证码破解比较繁杂,方法不同,正确率也会有差异,我一直在找比较好的方案,但是好的方案都比较专业,设涉及到了图形图像处理这些,我也是一知半解,所以就耽误了下来,在此对一直等待的同学说声抱歉。有兴趣的同学可以自行看看这方面的资料。因为我们都是入门,这次就以简单点的验证码为例,讲述下流程。废话不多说,正式开始。
1.)获取验证码
在上节,我们已经讲述了获取验证码的方法,这里不作赘述。下面是我获取到的另一个网站的验证码(最后我会放一个验证码的压缩包,想要练习的同学可以下载下来,寻找准确率更高的方案)。
2.)分析验证码
a.)分析样本空间
从上面的验证码可以看出,图片上总共有5个字,分别是操作数1、操作符、操作数2、"等于"。所以我们提取的话,只有前三个字是有效字。同时操作数的取值范围(0~9),操作符的取值为(加、乘)。所以总共有12个样本空间,操作数有10个,操作符有两个。
b.)分析提取范围
windows用户可以用系统自带的画板工具打开验证码,可以看到如下信息。
首先可以看到,验证码的像素是80*30,也就说横向80像素,纵向30像素,如果给它画上坐标系的话,坐标原点(0,0)为左上方顶点,向右为x轴(0=<x<80),向下为y轴(0=<y<30)。(10,17)是当前鼠标(图片中的十字)所在位置的坐标,这个可以帮助我们确定裁剪的范围。我用的裁剪范围分别是:
操作数1和操作数2的大小做好保持一致,这样可以使两个操作数共用样本数据。region = (3,4,16,17) 其中(3,4)代表左上顶点的坐标,(16,17)代表右下顶点的坐标,这样就可以构成一个矩形。大小为(16-3,17-4)即宽和高均为13像素的矩形
3.)处理验证码(这里我用的是python的"PIL"图像处理库)
a.)转为灰度图
PIL 在这方面也提供了极完备的支持,我们可以:
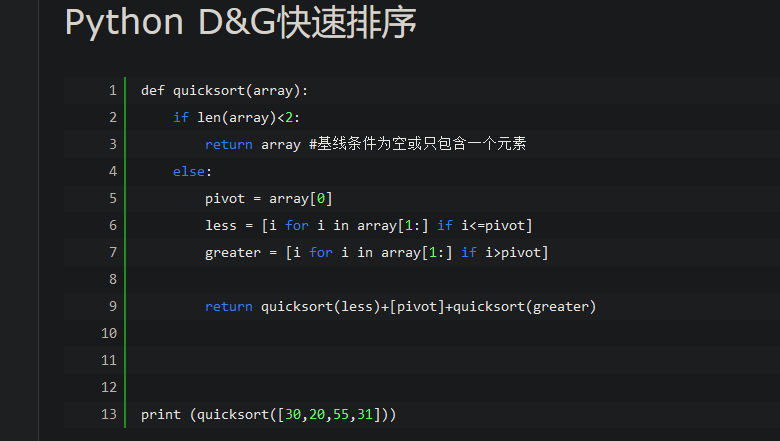
img.convert("L")
把 img 转换为 256 级灰度图像, convert() 是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式,mode 的取值可以是如下几种:
· 1 (1-bit pixels, black and white, stored with one pixel per byte)
· L (8-bit pixels, black and white)
· P (8-bit pixels, mapped to any other mode using a colour palette)
· RGB (3x8-bit pixels, true colour)
· RGBA (4x8-bit pixels, true colour with transparency mask)
· CMYK (4x8-bit pixels, colour separation)
· YCbCr (3x8-bit pixels, colour video format)
· I (32-bit signed integer pixels)
· F (32-bit floating point pixels)
代码如下:
from PIL import Imageimage = Image.open("H:\\authcode\\origin\\code3.jpg")
imgry = image.convert("L")
imgry.show()
运行结果:
然后二值化:
from PIL import Imageimage = Image.open("H:\\authcode\\origin\\code3.jpg")
imgry = image.convert("L")
# imgry.show()
threshold = 100
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
out = imgry.point(table,\'1\')
out.show()
运行结果:
这个时候就是比较纯粹的黑白图了。
代码说明:
a).threshold = 100这个是一个阈值,具体是多少,看情况,如果比较专业的可以根据图片的灰度直方图来确定,一般而言,可以自己试试不同的值,看哪个效果最好。
b).其他的函数都是PIL自带的,有疑问的可以自己找资料查看
b.)图片裁剪
代码如下:
from PIL import Imageimage = Image.open("H:\\authcode\\origin\\code3.jpg")
imgry = image.convert("L")
# imgry.show()
threshold = 100
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
out = imgry.point(table,\'1\')
# out.show()
region = (3,4,16,17)
result = out.crop(region)
result.show()
运行结果:
更改region的值就可以裁剪到不同的图片,然后对其进行分类。我是把每个数字都不同的文件夹里,结果如下:
4.)提取特征值
提取特征值的算法就是因人而异了,这里我用的是,对每个分割后的验证码,横向画两条线,纵向画两条线,记录与验证码的交点个数(很尴尬的是我这个方案,识别率不高,这里意思到了就行了,大家懂的)。
就是这么个意思。这四条线的表达式为:(横线)x=3和x=6,(竖线)y=2,y=11
代码如下:
def yCount1(image):count = 0;
x = 3
for y in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
def yCount2(image):
count = 0;
x = 6
for y in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
def xCount1(image):
count = 0
y = 2
for x in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
def xCount2(image):
count = 0
y = 11
for x in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
把(0~9)这10个数字取特征值之后就得到如下图的结果:
2:5:3:3-02:2:2:3-0
5:2:2:4-0
2:2:2:0-0
2:4:2:0-0
6:2:3:3-0
0:3:3:2-0
2:5:3:3-0
2:1:3:5-1
2:1:3:5-1
1:6:3:4-1
1:8:3:2-1
1:8:3:3-1
1:6:3:4-1
1:5:3:3-1
1:3:3:5-1
2:1:3:5-1
1:6:3:3-1
1:7:3:2-1
1:5:3:3-1
1:7:3:4-1
1:8:3:2-1
2:1:2:5-1
2:1:1:2-1
1:8:3:2-1
2:1:2:5-1
1:7:0:1-1
2:1:2:5-1
6:1:2:1-1
0:6:3:1-1
0:6:2:1-1
1:7:2:1-1
5:1:2:3-1
1:3:3:5-1
2:7:2:2-1
6:1:2:1-1
2:1:2:3-1
5:1:1:0-1
1:6:3:3-1
1:7:3:2-1
1:7:3:4-1
5:1:2:3-1
2:1:1:1-1
1:6:0:1-1
4:1:2:3-1
1:1:2:4-1
5:1:2:1-1
0:5:2:2-1
2:1:2:4-1
1:5:3:5-1
5:1:3:3-1
1:8:3:2-1
1:5:3:3-1
2:1:2:5-1
2:1:1:2-1
2:1:2:5-1
2:1:2:5-1
2:1:2:5-1
2:1:2:5-1
1:8:3:2-1
2:1:2:5-1
1:5:3:3-1
2:1:3:5-1
3:2:2:2-2
4:1:1:1-2
3:3:2:6-2
3:3:4:4-2
2:3:2:3-2
3:3:2:6-2
2:3:3:3-2
2:3:3:3-2
3:5:3:6-2
最后一个数字代表这个特征值的结果,比如3:5:3:6-2,代表如果一个图片满足3:5:3:6,那么我们就认为这个图片上的值为2
这样是有误差的
首先,存在一个特征值同时输入多个数字,比如,1:2:3:4可能输入2,也可能输入3,这个时候就会出现误差。(解决方案:取出现频率最高的结果,但是也会有误差)
其次,可能存在一个特征值不在我们的样本空间。(解决方案:扩大样本空间)
5.)验证
完成以上几部,就可以进行破解测试了。
代码如下(crackcode是我自己写的函数):
附录:
crackcode.py
#encoding=utf8import checknumber
import splitImage
import checkoperation
def getCodeResult(image):
image1 = splitImage.getNumImage(image,1)
image2 = splitImage.getNumImage(image,2)
image3 = splitImage.getNumImage(image,3)
num1 = checknumber.getnum(image1)
num2 = checknumber.getnum(image2)
operation =checkoperation.getoperation(image3)
# print `num1`+":"+`operation`+":"+`num2`
if(int(operation) != 2):
result = int(num1) + int(num2)
else:
result = int(num1) * int(num2)
return result
checknumber.py
#encoding=utf8from PIL import Image
import test
import collections
f = open("../src/school")
lines = f.readlines()
ips={}
for i in range(0,len(lines)):
ips[i] = lines[i]
def getnum(image):
# newimage = test.handimage(image)
newimage = image
result = `test.yCount1(newimage)`+":"+`test.yCount2(newimage)`+":"+`test.xCount1(newimage)`+":"+`test.xCount2(newimage)`
result_ips = []
for x in range(len(ips)):
if(ips[x].find(result)>-1):
result_ips.append(ips[x].strip("\n").split(\'-\')[1])
d = collections.Counter(result_ips)
if(len(d.most_common(1))==0):
return -1
else:
return d.most_common(1)[0][0]
splitImage.py
#encoding=utf8from PIL import Image
def getNumImage(image,type):
imgry = image.convert("L")
threshold = 100
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
out = imgry.point(table,\'1\')
if(type == 1):#操作数1
region = (3,4,16,17)
result = out.crop(region)
return result
elif(type == 2):#操作数2
region = (33,4,46,17)
result = out.crop(region)
return result
else:#操作符
region = (18,4,33,17)
result = out.crop(region)
return result
return result
checkoperation.py
#encoding=utf8from PIL import Image
import test
import collections
f = open("../src/operation")
lines = f.readlines()
ips={}
for i in range(0,len(lines)):
ips[i] = lines[i]
def getoperation(image):
# newimage = test.handimage(image)
newimage = image
result = `test.yCount1(newimage)`+":"+`test.yCount2(newimage)`+":"+`test.xCount1(newimage)`+":"+`test.xCount2(newimage)`
result_ips = []
for x in range(len(ips)):
if(ips[x].find(result)>-1):
result_ips.append(ips[x].strip("\n").split(\'-\')[1])
d = collections.Counter(result_ips)
if(len(d.most_common(1))==0):
return -1
else:
return d.most_common(1)[0][0]
test.py
#encoding=utf8from pytesseract import *
from PIL import Image
def handimage(image):
height = image.size[1]
width = image.size[0]
# print height,width
for h in range(height):
for w in range(width):
pixel = image.getpixel((w,h))
if(pixel<127):
image.putpixel((w,h),0)
else:
image.putpixel((w,h),255)
for h in range(height):
for w in range(width):
pixel = image.getpixel((w,h))
# print pixel
return image
def yCount1(image):
count = 0;
x = 3
for y in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
def yCount2(image):
count = 0;
x = 6
for y in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
def xCount1(image):
count = 0
y = 2
for x in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
def xCount2(image):
count = 0
y = 11
for x in range(0,13):
pixel = image.getpixel((x,y))
if(pixel==0):
count = count+1
return count
operation和school分别为操作数和操作符的样本空间,可以自己获取。
验证码样本放在百度云了,500条:
链接:http://pan.baidu.com/s/1hrv5w7y 密码:igo6
至此,破解验证码的流程就结束了。
说明:
a).代码仅供学习交流
b).如有错误,多多指教
c).转载请注明出处
以上是 Python 爬虫入门(四)—— 验证码下篇(破解简单的验证码) - 不剃头的一休哥 的全部内容, 来源链接: utcz.com/z/386567.html