Spring中 bean定义的parent属性机制的实现分析
本文内容纲要:Spring中 bean定义的parent属性机制的实现分析
在XML中配置bean元素的时候,我们常常要用到parent属性,这个用起来很方便就可以让一个bean获得parent的所有属性
在spring中,这种机制是如何实现的?
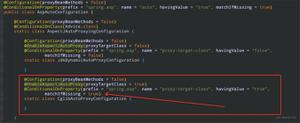
对于这种情况 transactionProxy01的parent属性是transactionProxy1
此时我们要获取transactionProxy01的实例 spring应该如何处理呢?
<bean id="transactionProxy01" parent="transactionProxy1"> <property name="target" ref="service01"/>
</bean>
<bean id="transactionProxy1" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager" ref="transactionManager"></property>
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED,ISOLATION_READ_COMMITTED,timeout_6000,-Exception</prop>
<prop key="error*">PROPAGATION_REQUIRED,ISOLATION_DEFAULT,timeout_20,readOnly,-Exception</prop> <!-- -Exception表示有Exception抛出时,事务回滚. -代表回滚 +就代表提交 -->
</props>
</property>
</bean>
这个问题还是得从两个过程分析,
- 一个是解析xml创建出BeanDefinition对象,
- 一个是从beanFactory中 依据BeanDefinition创建出实例
1.DefaultBeanDefinitionDocumentReader类中的parseBeanDefinitions方法
此时 xml文档的root元素一句解析出来 ,用于真正解析每个元素的delegate类实例也已经创建好
这两个作为参数传入这个方法
protected void parseBeanDefinitions(Element root, BeanDefinitionParserDelegate delegate) { if (delegate.isDefaultNamespace(root)) {
NodeList nl = root.getChildNodes();
for (int i = 0; i < nl.getLength(); i++) {
Node node = nl.item(i);
if (node instanceof Element) {
Element ele = (Element) node;
if (delegate.isDefaultNamespace(ele)) {
parseDefaultElement(ele, delegate); //对xml中的bean元素挨个做解析
}
else {
delegate.parseCustomElement(ele);
}
}
}
}
else {
delegate.parseCustomElement(root);
}
}
protected void processBeanDefinition(Element ele, BeanDefinitionParserDelegate delegate) {
//利用delegate的方法 解析出bean元素 beanDefinition对象存放在一个Holder里面
BeanDefinitionHolder bdHolder = delegate.parseBeanDefinitionElement(ele);
if (bdHolder != null) {
try {
//这个是注册 就是把BeanDefinition保存到BeanFactory的BeanDefinitionMap里面去
BeanDefinitionReaderUtils.registerBeanDefinition(bdHolder, getReaderContext().getRegistry());
}
}
}
接下去进入Delegate BeanDefinitionParserDelegate
public BeanDefinitionHolder parseBeanDefinitionElement(Element ele, BeanDefinition containingBean) { String id = ele.getAttribute(ID_ATTRIBUTE); //获取出bean的id
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
//...省略了一些代码
String beanName = id;
//...省略了一些代码
AbstractBeanDefinition beanDefinition = parseBeanDefinitionElement(ele, beanName, containingBean);//解析xml中的bean元素 创建beanDefinition对象
if (beanDefinition != null) {
//...省略了一些代码
String[] aliasesArray = StringUtils.toStringArray(aliases);
return new BeanDefinitionHolder(beanDefinition, beanName, aliasesArray);
}
return null;
}
public AbstractBeanDefinition parseBeanDefinitionElement(
Element ele, String beanName, BeanDefinition containingBean) {
this.parseState.push(new BeanEntry(beanName));//SAX解析特有的 都要定义一个stack做辅助
String className = null;
if (ele.hasAttribute(CLASS_ATTRIBUTE)) {
className = ele.getAttribute(CLASS_ATTRIBUTE).trim();
}
try {
String parent = null;
if (ele.hasAttribute(PARENT_ATTRIBUTE)) {
parent = ele.getAttribute(PARENT_ATTRIBUTE); //取出了parent属性的值
}
AbstractBeanDefinition bd = createBeanDefinition(className, parent);//创建一个BeanDefinition对象 注意把parent属性传进去了
//后面就是解析bean元素的其他属性 然后set到这个BeanDefinition对象里面去
parseBeanDefinitionAttributes(ele, beanName, containingBean, bd);
//...省略了一些代码
return bd;
}
//...省略了一些代码
finally {
this.parseState.pop();
}
return null;
}
进入BeanDefinitionReaderUtils工具类
public static AbstractBeanDefinition createBeanDefinition( String parentName, String className, ClassLoader classLoader) throws ClassNotFoundException {
GenericBeanDefinition bd = new GenericBeanDefinition();//创建一个beanDefinition对象
bd.setParentName(parentName);//把parent属性set进去
if (className != null) {
if (classLoader != null) {
bd.setBeanClass(ClassUtils.forName(className, classLoader));
}
else {
bd.setBeanClassName(className);
}
}
return bd; //然后返回beanDefinition对象
}
至此 BeanDefinition是创建完了 可以看到,我们定义parent属性,在创建过程中并没有什么特殊的处理,只是把parent作为一个属性,设置到BeanDefinition对象里面去了
那么真正的处理逻辑肯定就是在我们getBean的时候了
下面来分析getBean逻辑
问题的关键就在AbstractBeanFactory类里面doGetBean方法
protected <T> T doGetBean( final String name, final Class<T> requiredType, final Object[] args, boolean typeCheckOnly)
throws BeansException {
final RootBeanDefinition mbd = getMergedLocalBeanDefinition(beanName); //这里是根据beanName获取到BeanDefinition,parent的处理就是在这里发生的
protected RootBeanDefinition getMergedLocalBeanDefinition(String beanName) throws BeansException {
// Quick check on the concurrent map first, with minimal locking.
RootBeanDefinition mbd = this.mergedBeanDefinitions.get(beanName); //一开始获取合并的BeanDefinition 肯定是null 之前没有缓存的
if (mbd != null) {
return mbd;
}
//然后先取出原始的transactionProxy01的beanDefinition 注意 这里取出的beanDefinition中 beanName是transactionProxy01,parent是transactionProxy1,
//但是beanClass是null
//然后执行getMergedBeanDefinition(beanName, getBeanDefinition(beanName)) 准备把parent的beanClass属性拿出来放到子beanBefinition里面去
return getMergedBeanDefinition(beanName, getBeanDefinition(beanName));
}
protected RootBeanDefinition getMergedBeanDefinition(
String beanName, BeanDefinition bd, BeanDefinition containingBd)
throws BeanDefinitionStoreException {
synchronized (this.mergedBeanDefinitions) {
RootBeanDefinition mbd = null;
// Check with full lock now in order to enforce the same merged instance.
if (containingBd == null) {
mbd = this.mergedBeanDefinitions.get(beanName);
}
if (mbd == null) {
if (bd.getParentName() == null) {
//....省略一些代码
}
else {
// Child bean definition: needs to be merged with parent.
BeanDefinition pbd;
try {
String parentBeanName = transformedBeanName(bd.getParentName());//取到parent的name
if (!beanName.equals(parentBeanName)) {
//这个方法获取parent对于的beanDefinition,这个方法里面其实又是调用上一个方法的
//也就是还是进一步调用getMergedBeanDefinition(beanName, getBeanDefinition(beanName)); 是递归的! 用于解决parent还有parent 的情况
//所以这个地方要特别注意的 多层级的parent处理就是这里的递归解决的
pbd = getMergedBeanDefinition(parentBeanName);
}
else {
//....省略一些代码
}
}
//....省略一些代码
// Deep copy with overridden values.
//核心的来了 先用parent 的BeanDefinition为参数,创建了一个新的BeanDefinition 想想都知道就是new了一个新的RootBeanDefinition对象
//然后把parent的BeanDefinition的属性一个一个都set到新的RootBeanDefinition对象里面,相当于深拷贝了
mbd = new RootBeanDefinition(pbd);
mbd.overrideFrom(bd);//然后用孩子beanDefinition已有的属性 去覆盖掉parent里继承下来的属性值
}
//....省略一些代码
}
return mbd;
}
}
至此,spring处理的parent的方式已经搞清楚了
<bean id="transactionProxy01" parent="transactionProxy1"> <property name="target" ref="service01"/>
</bean>
<bean id="transactionProxy1" class="org.springframework.transaction.interceptor.TransactionProxyFactoryBean">
<property name="transactionManager" ref="transactionManager"></property>
<property name="transactionAttributes">
<props>
<prop key="*">PROPAGATION_REQUIRED,ISOLATION_READ_COMMITTED,timeout_6000,-Exception</prop>
<prop key="error*">PROPAGATION_REQUIRED,ISOLATION_DEFAULT,timeout_20,readOnly,-Exception</prop>
</props>
</property>
</bean>
1.spring在最初解析XML的时候,并没有做特殊处理,只是把transactionProxy01这个beanDefinition对象里的parentName属性给做了赋值,然后照常的****存储到了BeanFactory里
2.在我们执行getBean("transactionProxy01")的时候,spring先出去transactionProxy01对于的BeanDefinition对象,检测出了其中有一个parentName属性不为null
3.于是根据parentName,取出了parent对应的BeanDefinition对象,然后创建出一个新的RootBeanDefinition对象,把parent对于的BeanDefinition对象的属性值都拷贝进入,
作为parent对于的BeanDefinition的一个深拷贝(称为mbd)。
4.然后用孩子bean,也就是transactionProxy01对应的BeanDefinition对象里的有的属性值去覆盖这个mbd里的属性值,也就是例子中
** 如此一来,**
- ** 我们得到的mbd 就是这样一个BeanDefinition**
- ** 它的beanName是transactionProxy01**
- ** 它的target是service01**
- ** 它的beanClass,以及其他的属性,都和parent的BeanDefinition是相同的**
最后把这个新的BeanDefinition返回
接下去就是利用这个心的BeanDefinition来创建Bean实例对象的过程了。
其中孩子bean和parent合并出来的这个BeanDefinition也会做缓存的,存储在DefaultListableBeanFactory里的mergedBeanDefinitions这个线程安全Map里面
下次就不用合并了,直接可以取出来用
private final Map<String, RootBeanDefinition> mergedBeanDefinitions = new ConcurrentHashMap<String, RootBeanDefinition>(64);
这种下一层级覆盖上一层级的做法很普遍,比如struts就是先加载底层的struts-default.xml 然后再加载我们用户自己的struts.xml
这个时候我们用户自己的属性设置,就会把初始的struts-default.xml 里的设置覆盖掉
原创博客,转载请注明出处
本文内容总结:Spring中 bean定义的parent属性机制的实现分析
原文链接:https://www.cnblogs.com/wz1989/p/4273702.html
以上是 Spring中 bean定义的parent属性机制的实现分析 的全部内容, 来源链接: utcz.com/z/362342.html