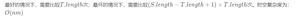在C ++中查找所有好的字符串
假设我们有两个字符串s1和s2。这些字符串的大小为n,我们还有另一个字符串称为evil。我们必须找到好字符串的数量。
如果字符串的大小为n,则按字母顺序大于或等于s1,按字母顺序小于或等于s2,并且作为子字符串不包含邪恶,则该字符串称为良。答案可能非常大,因此请以10 ^ 9 + 7为模返回答案。
因此,如果输入类似于n = 2,则s1 =“ bb”,s2 =“ db”,evil =“ a”,则输出将为51,因为有25个以b开头的良好字符串。“ bb”,“ bc”,“ bd”,...“ bz”,那么有25个以“ cb”,“ cc”,“ cd”,...,“ cz”开头的好字符串带有d的字符串是“ db”。
为了解决这个问题,我们将遵循以下步骤-
N:= 500,M:= 50
定义大小为(N + 1)x(M + 1)x 2。
定义大小为(M + 1)x 26的数组tr。
m:= 1 ^ 9 + 7
定义一个函数add(),这将花费a,b,
return((a mod m)+(b mod m))mod m
定义一个函数solve(),它将花费n,s,e,
反转数组e
用0填充tr和dp
对于初始化i:= 0,当i <e的大小时,更新(将i增加1),执行-
ns:= f +(j +'a'的ASCII)
对于初始化k:= i + 1,(将k减1),-
tr [i,j]:= k
从循环中出来
如果从索引(i +1-k)到结尾的ns子字符串与从索引0到e的k-1的e子字符串相同,则-
f:= e从索引0到i-1的子字符串
对于初始化j:= 0,当j <26时,更新(将j增加1),执行-
m:= e的大小
对于初始化i:= 0,当i <= n时,更新(将i增加1),请执行-
dp [i,j,0]:= 0
dp [i,j,1]:= 0
对于初始化j:= 0,当j <m时,更新(将j增加1),执行-
dp [n,0,1]:= 1
对于初始化i:= n-1,当i> = 0时,更新(将i减1),-
对于初始化k:= 0,当k <26时,更新(k增加1),-
如果k> s [i]-'a'的ASCII,则-
否则,当k <s [i]-'a'的ASCII时,则-
除此以外
dp [i,tr [j,k],nl]:= add(dp [i,tr [j,k],nl],dp [i + 1,j,l])
nl:= 0
nl:= 1
nl:= l
适用于范围(0,1)中的l
对于初始化j:= 0,当j <e的大小时,更新(将j增加1),执行-
ret:= 0
对于初始化i:= 0,当i <e的大小时,更新(将i增加1),执行-
ret:= add(ret,dp [0,i,1])
返回ret
从主要方法中执行以下操作-
好的:= 1
对于初始化i:= 0,当i <s1的大小且ok不为零时,更新(将i增加1),执行-
ok:= 1,当s1 [i]与'a'的ASCII相同
如果不能,则为非零,则-
如果s1 [i]不等于'a',则-
s1 [i]:='z'的ASCII
(将s1 [i]减1)
从循环中出来
对于初始化i:= s1的大小,当i> = 0时,更新(将i减1),执行-
左:=(如果ok为非零,则为0,否则为solve(n,s1,邪恶))
对:= solve(n,s2,evil)
返回(右-左+ m)mod m
让我们看下面的实现以更好地理解-
示例
#include <bits/stdc++.h>using namespace std;
typedef long long int lli;
const int N = 500;
const int M = 50;
int dp[N + 1][M + 1][2];
int tr[M + 1][26];
const lli m = 1e9 + 7;
class Solution {
public:
int add(lli a, lli b){
return ((a % m) + (b % m)) % m;
}
lli solve(int n, string s, string e){
reverse(e.begin(), e.end());
memset(tr, 0, sizeof(tr));
memset(dp, 0, sizeof(dp));
for (int i = 0; i < e.size(); i++) {
string f = e.substr(0, i);
for (int j = 0; j < 26; j++) {
string ns = f + (char)(j + 'a');
for (int k = i + 1;; k--) {
if (ns.substr(i + 1 - k) == e.substr(0, k)) {
tr[i][j] = k;
break;
}
}
}
}
int m = e.size();
for (int i = 0; i <= n; i++) {
for (int j = 0; j < m; j++) {
dp[i][j][0] = dp[i][j][1] = 0;
}
}
dp[n][0][1] = 1;
for (int i = n - 1; i >= 0; i--) {
for (int j = 0; j < e.size(); j++) {
for (int k = 0; k < 26; k++) {
for (int l : { 0, 1 }) {
int nl;
if (k > s[i] - 'a') {
nl = 0;
}
else if (k < s[i] - 'a') {
nl = 1;
}
else
nl = l;
dp[i][tr[j][k]][nl] = add(dp[i][tr[j][k]]
[nl], dp[i + 1][j][l]);
}
}
}
}
lli ret = 0;
for (int i = 0; i < e.size(); i++) {
ret = add(ret, dp[0][i][1]);
}
return ret;
}
int findGoodStrings(int n, string s1, string s2, string evil) {
bool ok = 1;
for (int i = 0; i < s1.size() && ok; i++) {
ok = s1[i] == 'a';
}
if (!ok) {
for (int i = s1.size() - 1; i >= 0; i--) {
if (s1[i] != 'a') {
s1[i]--;
break;
}
s1[i] = 'z';
}
}
int left = ok ? 0 : solve(n, s1, evil);
int right = solve(n, s2, evil);
return (right - left + m) % m;
}
};
main(){
Solution ob;
cout << (ob.findGoodStrings(2, "bb", "db", "a"));
}
输入项
2, "bb", "db", "a"
输出结果
51
以上是 在C ++中查找所有好的字符串 的全部内容, 来源链接: utcz.com/z/361360.html