django数据模型中null和blank的区别说明
虽然本人使用django也有几年的时间,但是还是对django中数据模型的null和blank有点分不清楚,我想很多人也和我一样的困惑,现在将全面彻底的讲解下两个的区别。
一、null的使用
1、默认是False的,如果设置为True的时候,django将会映射到数据表指定是否为空
2、如果这个字段设置为False的时候,如果没给这个字段传递任何值的时候,django也会使用一个空字符串('')存储进去
3、如果这个字段设置为True的时候,django会产生两种空值的情形(null和空字符串)
4、如果想要在表单验证的时候允许这个字符串为空的时候,django建议使用blank=True
5、如果你的字段BooleanField的时候,可以为空的建议使用NullBooleanField
1、数据模型代码
class BookModel(models.Model):
"""
书籍的数据模型
"""
uuid = models.UUIDField(unique=True, default=uuid.uuid4, verbose_name='uuid')
name = models.CharField(max_length=100, default='', null=True, verbose_name='书籍名称')
# null默认是False,但是本案例中还是写上去,更好区分
author = models.CharField(max_length=100, default='', null=False, verbose_name='作者')
# blank=True仅仅是在表单校验的时候可以为空,别的时候没什么区别
price = models.FloatField(default=0, blank=True, verbose_name='价格')
create_time = models.DateTimeField(auto_now_add=True, verbose_name='创建时间')
update_time = models.DateTimeField(auto_now=True, verbose_name='修改时间')
def __str__(self):
return '<BookModel>({}, {}, {}, {}, {}, {})'.format(self.uuid, self.name, self.author, self.price,self.create_time, self.update_time)
class Meta(object):
db_table = 'book'
2、sql语句
CREATE TABLE `book` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`price` double NOT NULL,
`create_time` datetime(6) NOT NULL,
`update_time` datetime(6) NOT NULL,
`uuid` char(32) NOT NULL,
`author` varchar(100) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uuid` (`uuid`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
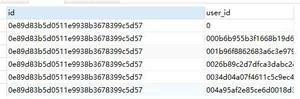
3、数据库表结构
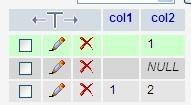
4、插入数据后显示对比
二、blank的使用
1、这个字段是在表单验证的时候可以为空,默认是False
2、这个和null是有区别的
blank=True仅仅是在表单验证的时候可以为空
null=True仅仅是数据库级别的null
补充知识:Python中生成器的原理与使用说明
0.range() 函数,其功能是创建一个整数列表,一般用在 for 循环中
语法格式:range(start, stop, step),参数使用参考如下:
start: 计数从 start 开始。默认是从 0 开始。例如range(4)等价于range(0, 4);结果:(0,1,2,3)
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)
#使用range函数建立列表
ls =[x*2 for x in range(10)]
print(ls)#[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
ls1 = [x for x in range(0,10,2)] #步长是2.
print(ls1) #[0, 2, 4, 6, 8]
ls2 = [x for x in range(3,10,2)] #开始从3开始,步长是2.
print(ls2) # [3, 5, 7, 9]
ls3 =[x for x in range(0, -10, -1)] #负数的使用
print(ls3) #[0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
print(range(0)) #range(0, 0)
print(range(1,0)) #range(1, 0)
1.生成器的创建与元素迭代遍历
1.1创建生成器方法1:只要把一个列表生成式的 [ ] 改成 ( )
生成器(generator)其实是一类特殊的迭代器。前面博客我们每次迭代获取数据(通过next()方法)时按照特定的规律进行生成。但是我们在实现一个迭代器时,关于当前迭代到的状态需要我们自己记录,进而才能根据当前状态生成下一个数据。为了达到记录当前状态,并配合next()函数进行迭代使用,python就搞了个生成器。所以说生成器(generator)其实是一类特殊的迭代器。
#1.创建生成器
ls = [x*2 for x in range(10)]
generator1 =(x*2 for x in range(10)) #这是一个生成器generator
print(ls)
print(generator1) #注意,打印生成器,不会像列表一样打印他的值,而是地址。
'''
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
<generator object <genexpr> at 0x00000239FE00A620>
'''
1.1遍历生成器内容
遍历生成器对象中的内容:
1.方法1.使用for循环遍历
for i in generator1:
print(i)
#方法2:命令行使用next()函数:调用next(G) ,就计算出 G 的下一个元素的值,直到计算到最后一个元素
没有更多的元素时,抛出 StopIteration 的异常。
>>> generator1 =(x*2 for x in range(5))
>>> next(generator1)
0
>>> next(generator1)
2
>>> next(generator1)
4
>>> next(generator1)
6
>>> next(generator1)
8
>>> next(generator1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
2.方法2.python脚本使用next()方法,实际开发中是通过for循环来实现遍历,这种next()方法太麻烦。
g1 =(x*2 for x in range(5))
while True:
try:
x = next(g1)
print(x)
except StopIteration as e :
print("values=%s"%e.value)
break #注意这里要加break,否则会死循环。
'''结果如下:
0
2
4
6
8
values=None
'''
3.方法3:使用对象自带的__next__()方法,效果等同于next(g1)函数
>>> g1 =(x*2 for x in range(5))
>>> g1.__next__()
0
>>> g1.__next__()
2
>>> g1.__next__()
4
>>> g1.__next__()
6
>>> g1.__next__()
8
>>> g1.__next__()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
>>>
1.2创建生成器方法2:使用yield函数创建生成器。
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的 for 循环无法实现的时候,还可以用函数来实现。简单来说:只要在def中有yield关键字的 就称为 生成器
#著名的斐波拉契数列(Fibonacci):除第一个和第二个数外,任意一个数都可由前两个数相加得到
#1.举例:1, 1, 2, 3, 5, 8, 13, 21, 34, ...使用函数实现打印数列的任意前n项。
def fib(times): #times表示打印斐波拉契数列的前times位。
n = 0
a,b = 0,1
while n<times:
print(b)
a,b = b,a+b
n+=1
return 'done'
fib(10) #前10位:1 1 2 3 5 8 13 21 34 55
#2.将print(b)换成yield b,则函数会变成generator生成器。
#yield b功能是:每次执行到有yield的时候,会返回yield后面b的值给函数并且函数会暂停,直到下次调用或迭代终止;
def fib(times): #times表示打印斐波拉契数列的前times位。
n = 0
a,b = 0,1
while n<times:
yield b
a,b = b,a+b
n+=1
return 'done'
print(fib(10)) #<generator object fib at 0x000001659333A3B8>
3.对生成器进行迭代遍历元素
方法1:使用for循环
for x in fib(6):
print(x)
''''结果如下,发现如何生成器是函数的话,使用for遍历,无法获取函数的返回值。
1
1
2
3
5
8
'''
方法2:使用next()函数来遍历迭代,可以获取生成器函数的返回值。同理也可以使用自带的__next__()函数,效果一样
f = fib(6)
while True:
try: #因为不停调用next会报异常,所以要捕捉处理异常。
x = next(f) #注意这里不能直接写next(fib(6)),否则每次都是重复调用1
print(x)
except StopIteration as e:
print("生成器返回值:%s"%e.value)
break
'''结果如下:
1
1
2
3
5
8
生成器返回值:done
'''
生成器使用总结:
1.生成器的好处是可以一边循环一边进行计算,不用一下子就生成一个很大的集合,占用内存空间。生成器的使用节省内存空间。
2.生成器保存的是算法,而列表保存的计算后的内容,所以同样内容的话生成器占用内存小,而列表占用内存大。每次调用 next(G) ,就计算出 G 的下一个元素的值,直到计算到最后一个元素,没有更多的元素时,抛出 StopIteration 的异常。
3.使用for 循环来遍历生成器内容,因为生成器也是可迭代对象。通过 for 循环来迭代它,不需要关心 StopIteration 异常。但是用for循环调用generator时,得不到generator的return语句的返回值。如果想要拿到返回值,必须用next()方法,且捕获StopIteration错误,返回值包含在StopIteration的value中。
4.在 Python 中,使用了 yield 的函数都可被称为生成器(generator)。生成器是一个返回迭代器的函数,只能用于迭代操作。更简单点理解生成器就是一个迭代器。
5.一个带有 yield 的函数就是一个 generator,它和普通函数不同,生成一个 generator 看起来像函数调用,但不会执行任何函数代码,直到对其调用 next()(在 for 循环中会自动调用 next())才开始执行。虽然执行流程仍按函数的流程执行,但每执行到一个 yield 语句就会中断,保存当前所有的运行信息,并返回一个迭代值,下次执行next() 方法时从 yield 的下一个语句继续执行。看起来就好像一个函数在正常执行的过程中被 yield 中断了数次,每次中断都会通过 yield 返回当前的迭代值。生成器不仅“记住”了它数据状态;生成器还“记住”了它在流控制构造中的位置。
以上这篇django数据模型中null和blank的区别说明就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持。
以上是 django数据模型中null和blank的区别说明 的全部内容, 来源链接: utcz.com/z/358973.html