Docker 部署Scrapy的详解
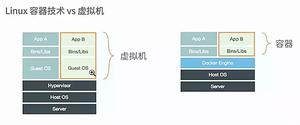
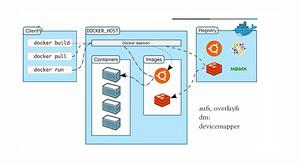
假设我们要在10台Ubuntu 部署爬虫如何搞之?用传统的方法会吐血的,除非你记录下来每个步骤,然后步骤之间的次序还完全一样,这样才行。但是这样还是累啊,个别软件下载又需要时间。所以Docker出现了。Docker把系统,各种需要的应用,还有设置编译成一个image,然后 run一下就可以了。跟虚拟机的区别是不需要而外的物理支持,共用的。
1. 部署步骤
1.1 上传本地scrapy爬虫代码除了settings外到git 服务器
1.2 编写Dockerfile文件,把settings和requirements.txt 也拷贝到image里,一起打包成一个image
Dockerfile内容:
FROM ubuntu
RUN apt-get update
RUN apt-get install -y git
RUN apt-get install -y nano
RUN apt-get install -y redis-server
RUN apt-get -y dist-upgrade
RUN apt-get install -y openssh-server
RUN apt-get install -y python3.5 python3-pip
RUN apt-get install -y zlib1g-dev libffi-dev libssl-dev
RUN apt-get install -y libxml2-dev libxslt1-dev
RUN mkdir /code
WORKDIR /code
ADD ./requirements.txt /code/
ADD ./settings.py /code/
RUN mkdir /code/myspider
RUN pip3 install -r requirements.txt
VOLUME [ "/data" ]
requirements.txt 内容:
BeautifulSoup4
scrapy
setuptools
scrapy_redis
redis
sqlalchemy
pymysql
pillow
整个目录结构:
docker build -t fox6419/scrapy:scrapyTag .
fox6419是用户名,scrapyTag是tag
成功后,执行docker images可以在本地看到image
1.3 打包的image 上传到docker hub中
docker push username/repository:tag
push的命令格式是这样的,我这边就是:
docker push fox6419/scrapy:scrapyTag
1.4 在DigitalOcean这种主机商创建带docker应用的Ubuntu 16.04版本
1.5 登陆docker,拉下1.3的image,然后run起来
docker run -it fox6419/scrapy:scrapyTag /bin/bash
1.6 命令进去后,git clone 1.1中的爬虫,然后复制images里的settings到爬虫目录,然后执行scrapy crawl xxx即可
以上是 Docker 部署Scrapy的详解 的全部内容, 来源链接: utcz.com/z/353991.html