Linux中tcpdump命令实例详解
前言
tcpdump是一款类Unix/Linux环境下的抓包工具,允许用户截获和显示发送或收到的网络数据包。 tcpdump可以将网络中传送的数据包的“头”完全截获下来提供分析。它支持针对网络层、协议、主机、网络或端口的过滤,并提供and、or、not等逻辑语句来帮助你去掉无用的信息。tcpdump 是一个在BSD许可证下发布的自由软件。
下面这篇文章将给大家详细介绍关于Linux中tcpdump命令的相关内容,分享出来供大家参考学习,下面话不多说,来一起看看详细的介绍吧。
一、命令格式
tcpdump [ -AbdDefhlLnNOpqRStuUvxX ] [ -B buffer_size ] [ -c count ]
[ -C file_size ] [ -F file ] [ -G rotate_seconds ]
[ -i interface ] [ -m module ] [ -M secret ]
[ -r file ] [ -s snaplen ] [ -T type ] [ -w file ]
[ -W filecount ]
[ -E spi@ipaddr algo:secret,... ]
[ -y datalinktype ] [ -z postrotate-command ] [ -Z user ]
[ expression ]
二、选项说明
-A:以ASCII码方式显示每一个数据包(不会显示数据包中链路层头部信息)。在抓取包含网页数据的数据包时, 可方便查看数据
-b:Print the AS number in BGP packets in ASDOT notation rather than ASPLAIN notation
-B [buffer_size],--buffer-size=buffer_size:设置操作系统捕捉缓冲大小,单位KB
-c [数据包数目]:收到指定的数据包数目后,就停止进行捕获操作
-C [file-size]:与-w [file]选项配合使用。该选项使得tcpdump在把原始数据包直接保存到文件中之前, 检查此文件大小是否超过file-size。如果超过了,将关闭此文件,另创一个文件继续保存原始数据包。新创建的文件名与-w选项指定的文件名一致, 但文件名后多了一个数字,该数字会从1开始随着新创建文件的增多而增加。 file-size的单位是百万字节(nt: 这里指1,000,000个字节,并非1,048,576个字节, 后者是以1024字节为1k, 1024k字节为1M计算所得, 即1M=1024*1024 =1,048,576)
-d:把编译过的数据包编码转换成可阅读的格式,并倾倒到标准输出
-dd:把编译过的数据包编码转换成C语言的格式,并倾倒到标准输出
-ddd:把编译过的数据包编码转换成十进制数字的格式,并倾倒到标准输出
-D,--list-interfaces:打印系统中所有tcpdump可以在其上进行抓包的网络接口。每一个接口会打印出数字编号, 相应的接口名字, 以及一个可能的网络接口描述。其中网络接口名字和数字编号可以用在tcpdump的-i [flag]选项(nt:把名字或数字代替flag), 来指定要在其上抓包的网络接口。此选项在不支持接口列表命令的系统上很有用(nt: 比如, Windows 系统, 或缺乏 ifconfig -a 的UNIX系统); 接口的数字编号在windows 2000 或其后的系统中很有用, 因为这些系统上的接口名字比较复杂, 而不易使用。如果tcpdump编译时所依赖的libpcap库太老,-D 选项不会被支持, 因为其中缺乏 pcap_findalldevs()函数
-e:每行打印输出中将包括数据包的数据链路层头部信息
-f:显示外部的IPv4地址时(nt:foreign IPv4 addresses, 可理解为非本机ip地址), 采用数字方式而不是名字。此选项是用来对付Sun公司的NIS服务器的缺陷(nt: NIS, 网络信息服务, tcpdump 显示外部地址的名字时会用到它提供的名称服务): 此NIS服务器在查询非本地地址名字时,常常会陷入无尽的查询循环)
由于对外部(foreign)IPv4地址的测试需要用到本地网络接口(nt: tcpdump 抓包时用到的接口)及其IPv4 地址和网络掩码. 如果此地址或网络掩码不可用, 或者此接口根本就没有设置相应网络地址和网络掩码(nt: linux 下的 'any' 网络接口就不需要设置地址和掩码, 不过此'any'接口可以收到系统中所有接口的数据包), 该选项不能正常工作。
-F [file]: 使用file文件作为过滤条件表达式的输入, 此时命令行上的输入将被忽略
-G [rotate_seconds]:类似于-C [file_size]命令选项,-C按文件大小来新建文件存储数据包,-G则根据指定的时间周期,将监听到的数据包写入新的文件,新建的文件名由-w选项指定,并且文件名后接有时间串,时间串的格式由strftime(3)指定。如果没有指定时间串的格式,新的文件将覆盖旧的文件。
如果与-C option同时使用的话,文件名称格式将是file<count>。
-h,--help:打印tcpdump的帮助信息和libpcap的版本信息。(nt:libpcap是unix/linux平台下的网络数据包捕获函数包)
--version:打印tcpdump和libpcap的version。
-i [interface],--interface=interface: 指定tcpdump 需要监听的接口. 如果没有指定, tcpdump 会从系统接口列表中搜寻编号最小的已配置好的接口(不包括 loopback 接口).一但找到第一个符合条件的接口, 搜寻马上结束。
在采用2.2版本或之后版本内核的Linux操作系统上, 'any'这个虚拟网络接口可被用来接收所有网络接口上的数据包(nt: 这会包括目的是该网络接口的,也包括目的不是该网络接口的)。需要注意的是如果真实网络接口不能工作在'混杂模式'(promiscuous)下,则无法在'any'这个虚拟网络接口上抓取其数据包。
如果-D标志被指定, tcpdump会打印系统中的接口编号,而该编号就可用于此处的interface参数
-l:对标准输出进行行缓冲(nt: 使标准输出设备遇到一个换行符就马上把这行的内容打印出来)
-L:列出指定网络接口所支持的数据链路层的类型后退出.(nt: 指定接口通过-i 来指定)
-n:不把主机的网络地址转换成名字
-m [module]:通过module指定的file装载SMI和MIB模块(nt: SMI,Structure of Management Information, 管理信息结构;MIB, Management Information Base, 管理信息库。可理解为,这两者用于SNMP(Simple Network Management Protoco)协议数据包的抓取。具体SNMP 的工作原理未知, 另需补充)。
此选项可多次使用, 从而为tcpdump装载不同的MIB模块
-M [secret]:如果TCP数据包(TCP segments)有TCP-MD5选项(在RFC 2385有相关描述), 则为其摘要的验证指定一个公共的密钥secret
-n:不将地址(比如主机地址、端口号等)转换到对应的名字
-N:不要打印主机名的域名资格,比如打印'nic'而不是'nic.ddn.mil'
-O,--no-optimize:不启用进行包匹配时所用的优化代码. 当怀疑某些bug是由优化代码引起的, 此选项将很有用
-p,--no-promiscuous-mode:把网络接口设置为非'混杂'模式。但必须注意,在特殊情况下此网络接口还是会以'混杂'模式来工作;从而,-p的设与不设,不能当做以下选项的代名词:'ether host {local-hw-add}'或'ether broadcast'(nt: 前者表示只匹配以太网地址为host的包, 后者表示匹配以太网地址为广播地址的数据包
-q :快速打印输出,即打印很少的协议相关信息, 从而输出行都比较简短
-r [file]:从指定的文件读取数据包,如果file为'-'符号, 则tcpdump会从标准输入中读取包数据
-R:设定tcpdump对ESP/AH数据包的解析按照RFC1825而不是RFC1829(nt:AH:认证头,ESP:安全负载封装,这两者会用在IP包的安全传输机制中)。如果此选项被设置,tcpdump将不会打印出'禁止中继'域(nt: relay prevention field)。另外,由于ESP/AH规范中没有规定ESP/AH数据包必须拥有协议版本号域,所以tcpdump不能从收到的ESP/AH数据包中推导出协议版本号
-s [snaplen],--snapshot-length=snaplen: 设置tcpdump的数据包抓取长度为snaplen,而不是默认的262144字节。如果产生包截短这种情况, tcpdump的相应打印输出行中会出现''[|proto]''的标志(proto 实际会显示为被截短的数据包的相关协议层次). 需要注意的是, 采用长的抓取长度(nt: snaplen比较大), 会增加包的处理时间, 并且会减少tcpdump 可缓存的数据包的数量, 从而会导致数据包的丢失. 所以, 在能抓取我们想要的包的前提下, 抓取长度越小越好。把snaplen 设置为0意味着让tcpdump自动选择合适的长度来抓取数据包
-S,--absolute-tcp-sequence-numbers: 打印TCP 数据包的顺序号时, 使用绝对的顺序号, 而不是相对的顺序号.(nt: 相对顺序号可理解为, 相对第一个TCP 包顺序号的差距,比如, 接受方收到第一个数据包的绝对顺序号为232323, 对于后来接收到的第2个,第3个数据包, tcpdump会打印其序列号为1, 2分别表示与第一个数据包的差距为1 和 2. 而如果此时-S 选项被设置, 对于后来接收到的第2个, 第3个数据包会打印出其绝对顺序号:232324, 232325)
-t:在每行输出中不打印时间戳
-tt:不对每行输出的时间进行格式处理(nt: 这种格式一眼可能看不出其含义, 如时间戳打印成1261798315)
-ttt:tcpdump输出时, 每两行打印之间会延迟一个段时间,单位毫秒
-tttt:在每行打印的时间戳之前添加日期的打印
-ttttt:设置每一行输出时相对于第一行的时间间隔,单位毫秒
-T [type]:强制tcpdump按type指定的协议所描述的包结构来分析收到的数据包。目前已知的type可取的协议为:
(1)aodv(Ad-hoc On-demand Distance Vector protocol, 按需距离向量路由协议, 在Ad hoc(点对点模式)网络中使用);
(2)cnfp(Cisco NetFlow protocol);
(3)rpc(Remote Procedure Call);
(4)rtp(Real-Time Applications protocol);
(5)rtcp(Real-Time Applications con-trol protocol);
(6)snmp(Simple Network Management Protocol);
(7)tftp(Trivial File Transfer Protocol, 碎文件协议);
(8)vat(Visual Audio Tool,可用于在internet上进行电视电话会议的应用层协议), 以及wb(distributed White Board,可用于网络会议的应用层协议)
-u:打印出未加密的NFS句柄(nt:handle可理解为NFS中使用的文件句柄, 这将包括文件夹和文件夹中的文件)
-U:使得当tcpdump在使用-w选项时,其文件写入与包的保存同步。(nt:即当每个数据包被保存时, 它将及时被写入文件中,而不是等文件的输出缓冲已满时才真正写入此文件)。-U标志在老版本的libpcap库(nt:tcpdump所依赖的报文捕获库)上不起作用, 因为其中缺乏pcap_cump_flush()函数
-v:产生详细的输出。比如包的生存时间、标识、总长度以及IP包的一些选项。这也会打开一些附加的包完整性检测, 比如对IP或ICMP包头部的校验和
-vv:产生比-v更详细的输出。比如NFS(Network File System)回应包中的附加域将会被打印,SMB(Server Message Block)数据包也会被完全解码
-vvv:更详细的输出。例如,telent时所使用的SB,SE选项将会被打印, 如果telnet同时使用-X图形界面选项,其相应的图形选项将会以16进制的方式打印出。
-w [file]:把包数据直接写入文件而不进行分析和打印输出,这些包数据可在随后通过-r选项来重新读入并进行分析和打印
-W [filecount]:此选项与-C选项配合使用, 这将限制可打开的文件数目, 并且当文件数据超过这里设置的限制时, 依次循环替代之前的文件, 这相当于一个拥有filecount 个文件的文件缓冲池。同时,该选项会使得每个文件名的开头会出现足够多并用来占位的0,可以方便这些文件被正确的排序
-x:打印每个包的头部数据, 同时会以16进制打印出每个包的数据(但不包括连接层的头部),总共打印的数据大小不会超过整个数据包的大小与snaplen 中的最小值。必须要注意的是, 如果高层协议数据没有snaplen这么长,并且数据链路层(比如,Ethernet层)有填充数据, 则这些填充数据也会被打印
-xx:打印每个包的头部数据, 同时会以16进制打印出每个包的数据, 其中包括数据链路层的头部
-X:当分析和打印时, tcpdump会打印每个包的头部数据,同时会以16进制和ASCII码形式打印出每个包的数据(但不包括链路层的头部)。这对于分析一些新协议的数据包很方便
-XX:当分析和打印时,tcpdump会打印每个包的头部数据,同时会以16进制和ASCII码形式打印出每个包的数据, 其中包括数据链路层的头部.这对于分析一些新协议的数据包很方便
-y [datalinktype],--linktype=datalinktype:设置tcpdump只捕获数据链路层协议类型是datalinktype的数据包
-z [postrotate-command]:与-C或-G联用,当每一个文件被关闭时执行命令postrotate-command。比如,-z gzip或-z bzip2将对每一个保存的文件进行压缩
-Z [user],--relinquish-privileges=user:使tcpdump放弃自己的超级权限(如果以root用户启动tcpdump,tcpdump将会有超级用户权限),并把当前tcpdump的用户ID设置为user, 组ID设置为user首要所属组的ID
expression:条件表达式用于选择捕获符合条件的数据包,无expression,网络上任何两台主机间的所有数据包都将被截获
三、常用示例
3.1监视指定主机的数据包
(1)打印所有到达或从主机sunrise发出的数据包,host可以是IP地址或主机名
tcpdump host sunrise
(2)打印主机A与B或C之间来往的所有数据包
tcpdump host A and \( B or C \)
(3)打印ace与任何其他主机之间通信的IP数据包, 但不包括与helios之间的数据包.
tcpdump ip host ace and not helios
3.2监视指定网络的数据包
(1)打印本地主机与Berkeley网络上的主机之间的所有通信数据包
tcpdump net ucb-ether
(2)打印所有通过网关snup的ftp数据包。注意,表达式被单引号括起来了, 这可以防止shell对其中的括号进行错误解析
tcpdump 'gateway snup and (port ftp or ftp-data)'
(3)打印不是本地网络的数据包
tcpdump ip and not net localnet
3.3监视指定协议的数据包
(1)打印TCP会话中的的开始和结束数据包, 并且数据包的源或目的不是本地网络上的主机。(nt:localnet,实际使用时要真正替换成本地网络的名字)
tcpdump 'tcp[tcpflags] & (tcp-syn|tcp-fin) != 0 and not src and dst net localnet'
(2)打印长度超过576字节, 并且网关地址是snup的IP数据包
tcpdump 'gateway snup and ip[2:2] > 576'
ip[2:2]表示整个ip数据包的长度。
(3)打印除'echo request'或者'echo reply'类型以外的ICMP数据包(比如,需要打印所有非ping 程序产生的数据包时可用到此表达式 。(nt: ‘echo reuqest' 与 ‘echo reply' 这两种类型的ICMP数据包通常由ping程序产生))
tcpdump 'icmp[icmptype] != icmp-echo and icmp[icmptype] != icmp-echoreply'
3.4监视指定主机和端口的数据包
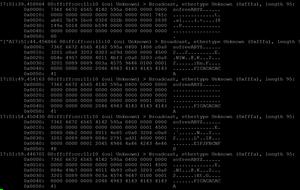
(1)抓取主机100.94.138.110所有经由接口eth1接收的数据包,且端口号是20700。
tcpdump -i eth1 -lnXps0 dst 100.94.138.110 and dst port 20700 -c 10
命令选项说明:lnXps0请参照上文的命令选项详解,-c 10表示只捕捉10个数据包。
总结
参考文档
[1]维基百科.tcpdump
[2]tcpdump官方网站
[3]Linux tcpdump命令详解
以上是 Linux中tcpdump命令实例详解 的全部内容, 来源链接: utcz.com/z/352166.html