对Postgresql中的json和array使用介绍
结合近期接触到的知识点,做了一个归纳。会持续更新
json
官网文档 http://www.postgres.cn/docs/12/datatype-json.html
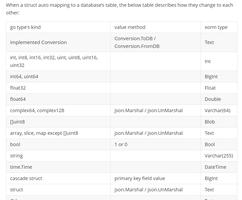
json的两种格式
总结:json输入快,处理慢。是精准拷贝,所以能准确存储遗留对象的原格式,如对象键顺序。jsonb输入慢,处理快。会被重新解析成json数据,不保存原对象的键顺序,并且去重相同的键值,以最后一个为准。通常,除非有特别特殊的需要(例如遗留的对象键顺序假设),大多数应用应该 更愿意把 JSON 数据存储为jsonb
官网:
json 和 jsonb数据类型接受***几乎***完全相同的值集合作为输入。 主要的实际区别之一是效率。json数据类型存储输入文本的精准拷贝,处理函数必须在每 次执行时必须重新解析该数据。而jsonb数据被存储在一种分解好的 二进制格式中,它在输入时要稍慢一些,因为需要做附加的转换。但是 jsonb在处理时要快很多,因为不需要解析。jsonb也支 持索引,这也是一个令人瞩目的优势。
由于json类型存储的是输入文本的准确拷贝,其中可能会保留在语法 上不明显的、存在于记号之间的空格,还有 JSON 对象内部的键的顺序。还有, 如果一个值中的 JSON 对象包含同一个键超过一次,所有的键/值对都会被保留( 处理函数会把最后的值当作有效值)。相反,jsonb不保留空格、不 保留对象键的顺序并且不保留重复的对象键。如果在输入中指定了重复的键,只有 最后一个值会被保留。
通常,除非有特别特殊的需要(例如遗留的对象键顺序假设),大多数应用应该 更愿意把 JSON 数据存储为jsonb
由于json类型存储的是输入文本的准确拷贝,其中可能会保留在语法 上不明显的、存在于记号之间的空格,还有 JSON 对象内部的键的顺序。还有, 如果一个值中的 JSON 对象包含同一个键超过一次,所有的键/值对都会被保留( 处理函数会把最后的值当作有效值)。相反,jsonb不保留空格、不 保留对象键的顺序并且不保留重复的对象键。如果在输入中指定了重复的键,只有 最后一个值会被保留。
-----------1.键的顺序
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::json;
json
-------------------------------------------------
{"bar": "baz", "balance": 7.77, "active":false}
(1 row)
SELECT '{"bar": "baz", "balance": 7.77, "active":false}'::jsonb;
jsonb
--------------------------------------------------
{"bar": "baz", "active": false, "balance": 7.77}
(1 row)
---------2.去重
SELECT '{"bar": "baz", "balance": 7.77, "balance":false}'::jsonb; --去重
{"bar": "baz", "balance": false}
SELECT '{"bar": "baz", "balance": 7.77, "balance":false}'::json; --不去重
{"bar": "baz", "balance": 7.77, "balance":false}
select '[1, 2, 2]'::jsonb --数组不去重
[1, 2, 2]
将字符串转为json格式
sq-- 简单标量/基本值
-- 基本值可以是数字、带引号的字符串、true、false或者null
SELECT '5'::json;
-- 有零个或者更多元素的数组(元素不需要为同一类型)
SELECT '[1, 2, "foo", null]'::json;
-- 包含键值对的对象
-- 注意对象键必须总是带引号的字符串
SELECT '{"bar": "baz", "balance": 7.77, "active": false}'::json;
-- 数组和对象可以被任意嵌套
SELECT '{"foo": [true, "bar"], "tags": {"a": 1, "b": null}}'::json;
输出:
5
[1, 2, “foo”, null]
{“bar”: “baz”, “balance”: 7.77, “active”: false}
{“foo”: [true, “bar”], “tags”: {“a”: 1, “b”: null}}
判断是否包含/存在 @> 和 ?
-- 简单的标量/基本值只包含相同的值:
SELECT '"foo"'::jsonb @> '"foo"'::jsonb; --得 真t
-- 右边的数字被包含在左边的数组中:
SELECT '[1, 2, 3]'::jsonb @> '[1, 3]'::jsonb; --t
-- 数组元素的顺序没有意义,因此这个例子也返回真:
SELECT '[1, 2, 3]'::jsonb @> '[3, 1]'::jsonb; --t
-- 重复的数组元素也没有关系:
SELECT '[1, 2, 3]'::jsonb @> '[1, 2, 2]'::jsonb; --t
-- 右边具有一个单一键值对的对象被包含在左边的对象中:
SELECT '{"product": "PostgreSQL", "version": 9.4, "jsonb": true}'::jsonb @> '{"version": 9.4}'::jsonb; --t
jsonb还有一个存在操作符,它是包含的一种 变体:它测试一个字符串(以一个text值的形式给出)是否出 现在jsonb值顶层的一个对象键或者数组元素中。
除非特别注解, 下面这些例子返回真:
-- 字符串作为一个数组元素存在:
SELECT '["foo", "bar", "baz"]'::jsonb ? 'bar'; --t
-- 字符串作为一个对象键存在:
SELECT '{"foo": "bar"}'::jsonb ? 'foo'; --t
-- 不考虑对象值:
SELECT '{"foo": "bar"}'::jsonb ? 'bar'; -- 得到假
当涉及很多键或元素时,JSON 对象比数组更适合于做包含或存在测试, 因为它们不像数组,进行搜索时会进行内部优化,并且不需要被线性搜索。
索引
-> 数组中是查找第几项,json中是取某key的元素object
->> json中是取某key的元素text
#> json中是通过路径取元素object
#>> json中是通过路径取元素text
json:='[{"a":"foo"},{"b":"bar"},{"c":"baz"}]'::json
--获取json数组中的某一项元素
--下标从0开始
select json->2 from test where name='jsonarray' --{"c": "baz"}
--获取json某一key的值为object
select (json->2)->'c' from test where name='jsonarray' --"baz"
--获取json某一key的值为text
select (json->2)->>'c' from test where name='jsonarray' --"baz"
--获取json某值通过路径 object
'{"a": {"b":{"c": "foo"}}}'::json#>'{a,b}' --{"c": "foo"}
--获取json某值通过路径 text
'{"a":[1,2,3],"b":[4,5,6]}'::json#>>'{a,2}' --3
补充:postgresql 数据库 jsonb/json中 array或int 类型进行的交集比较 存储过程字符串、整数数组条件查询
首先要新增这两个存储过程
新增存储过程字符串数组条件查询
CREATE OR REPLACE FUNCTION json_arr2text_arr(_js json) RETURNS text[] AS
$$
DECLARE
anyArray text[];
begin
SELECT ARRAY(SELECT json_array_elements_text(_js)) INTO anyArray;
RETURN anyArray;
end
$$
LANGUAGE plpgsql;
查询字符串数组中存在NP1的记录
select * from tb_template_area_safe WHERE json_arr2text_arr(area_functions) @> array['NP1'];
新增存储过程整数数组条件查询
CREATE OR REPLACE FUNCTION json_arr2int_arr(_js json) RETURNS int[] AS
$$
DECLARE
anyArray int[];
begin
SELECT ARRAY(SELECT json_array_elements_text(_js)::int) INTO anyArray;
RETURN anyArray;
end;
$$
LANGUAGE plpgsql;
查询条件是 左面 的 包含右面的
两者的交集 &&
SELECT tdnm.mid, tdnm.title, tdnm.content, tdnm.ui_id, tdnm.create_time, tdnm.cancel_time,
tdnm.job_ids, tdnm.remarks, tdnm.message_level_code, tdnm.channels FROM tb_data_notify_message
tdnm WHERE 1=1 and json_arr2text_arr(tdnm.job_ids)
&&array[['1','10']] ORDER BY create_time DESC
数组操作符:
| Operator | Description | Example | Result |
|---|---|---|---|
| = | equal | ARRAY[1.1,2.1,3.1]::int[] = ARRAY[1,2,3] | t |
| <> | not equal | ARRAY[1,2,3] <> ARRAY[1,2,4] | t |
| < | less than | ARRAY[1,2,3] < ARRAY[1,2,4] | t |
| > | greater than | ARRAY[1,4,3] > ARRAY[1,2,4] | t |
| <= | less than or equal | ARRAY[1,2,3] <= ARRAY[1,2,3] | t |
| >= | greater than or equal | ARRAY[1,4,3] >= ARRAY[1,4,3] | t |
| @> | contains | ARRAY[1,4,3] @> ARRAY[3,1] | t |
| <@ | is contained by | ARRAY[2,7] <@ ARRAY[1,7,4,2,6] | t |
| && | overlap (have elements in common) | ARRAY[1,4,3] && ARRAY[2,1] | t |
| || | array-to-array concatenation | ARRAY[1,2,3] || ARRAY[4,5,6] | {1,2,3,4,5,6} |
| || | array-to-array concatenation | ARRAY[1,2,3] || ARRAY[[4,5,6],[7,8,9]] | {{1,2,3},{4,5,6},{7,8,9}} |
| || | element-to-array concatenation | 3 || ARRAY[4,5,6] | {3,4,5,6} |
| || | array-to-element concatenation | ARRAY[4,5,6] || 7 | {4,5,6,7} |
PostgreSQL 9.4.4 中文手册
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
以上是 对Postgresql中的json和array使用介绍 的全部内容, 来源链接: utcz.com/z/351704.html