Spring Data Jpa的四种查询方式详解
这篇文章主要介绍了Spring Data Jpa的四种查询方式详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
一、调用接口的方式
1.基本介绍
通过调用接口里的方法查询,需要我们自定义的接口继承Spring Data Jpa规定的接口
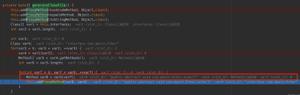
public interface UserDao extends JpaRepository<User, Integer>, JpaSpecificationExecutor<User>
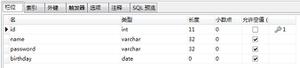
使用这几种方法的前提是你定义的实体类必须标注上相应的注解
@Entity //标注这是一个实体类
@Table(name = "tbl_user") //建立实体类与表的映射关系
public class User {
@Id //声明此属性为主键
@GeneratedValue(strategy = GenerationType.IDENTITY) //主键生成策略,自增
@Column(name = "user_id")//指定属性对应数据库表的列名
private Integer userId;
@Column(name = "user_name")
private String userName;
@Column(name = "user_address")
private String userAddress;
@Column(name = "user_salary")
private Double userSalary;
//...getter setter toString方法
}
JpaRepository<T,ID>
第一个接口里面定义了一些简单的CRUD方法,泛型T是你定义的实体类的类型,泛型ID是你的实体类里主键的类型
JpaSpecificationExecutor
这个接口可以帮助我们完成一些复杂查询,泛型T是你定义的实体类的类型
2.使用方法
只需要编写一个自己的接口继承上述两个接口并填好泛型即可调用
//测试类,调用接口的findAll方法
@Test
public void testFindAll(){
List<User> users = userDao.findAll();
for (User user : users) {
System.out.println(user);
}
}
3.注意事项
JpaRepository接口里有findOne()和getOne()方法,从字面意思上来看,两种方法都是查询一个,的确如此,但它们两个本质上却有一定的差别
findOne()
底层调用了find()方法,当我们调用这个方法的时候直接为我们查出结果
getOne()
底层调用了getReference()方法,是一种懒加载的模式,使用动态代理的方式为我们创建一个动态代理对象,当我们调用查询结果时才会发送sql语句,查询出我们需要的结果
二、jpql查询
1.基本介绍
jpql即 Jpa Query Language
jpql语法和sql其实大同小异,jpql是针对实体类进行的操作,sql是直接对数据库表的操作,所以jpql里只是将sql里数据库表名、列名等信息替换为实体类属性而已
例如
sql语句的查询:select * from tbl_user where user_name = ?
jpql语句的查询:from User where userName = ?
2.使用方法
自定义的方法,这里使用@Query注解,value是jpql语句,你可能注意到了,每个问号后面都带了一个数字,这个数字其实就表示这个属性对应方法内形参的位置,这样我们就可以不按照属性的顺序进行赋值了。
/**
* 根据用户id和name查询
* @return 用户对象
*/
@Query(value = "from User where userId = ?2 and userName = ?1")
User findUserByIdAndName(String name, int id);
测试代码
@Test
public void testJpql1(){
User user = userDao.findUserByIdAndName("张三", 1);
System.out.println(user);
}
3.注意事项
想要使用jpql的前提是你已经使用注解配置好了实体类以及参数
注解的详细信息如下:
/**
* @Entity
* 作用:指定当前类是实体类。
* @Table
* 作用:指定实体类和表之间的对应关系。
* 属性:
* name:指定数据库表的名称
* @Id
* 作用:指定当前字段是主键。
* @GeneratedValue
* 作用:指定主键的生成方式。。
* 属性:
* strategy :指定主键生成策略。
* GenerationType.IDENTITY:自增,底层数据库必须支持自增(mysql)
* GenerationType.SEQUENCE:序列,底层数据库必须支持序列(oracle)
* GenerationType.TABLE:jpa提供的一种策略,通过生成一张表的方式完成主键自增,这张表存储了下一次添加的主键的值
* GenerationType.AUTO:由程序自动选择一种策略
*
* @Column
* 作用:指定实体类属性和数据库表之间的对应关系
* 属性:
* name:指定数据库表的列名称。
* unique:是否唯一
* nullable:是否可以为空
* inserttable:是否可以插入
* updateable:是否可以更新
* columnDefinition: 定义建表时创建此列的DDL
* secondaryTable: 从表名。如果此列不建在主表上(默认建在主表),该属性定义该列所在从表的名字搭建开发环境[重点]
*/
三、sql查询
1.基本介绍
使用sql语句查询
2.使用方法
自定义的方法,与jpql不同的是,这种方法需要加上nativeQuery=true来声明这是一个本地查询(sql查询)
/**
* 使用sql进行条件查询
*/
@Query(value = "select * from tbl_user where user_name like ?",nativeQuery = true)
List<User> sqlFindByName(String name);
测试方法
@Test
public void testSql2(){
List<User> users = userDao.sqlFindByName("%张%");
for (User user : users) {
System.out.println(user);
}
}
四、方法命名规则查询
1.基本介绍
顾名思义,这种方法就是使用Spring Data JPA规定的方法名称进行查询,这种方式不需要我们写jpql或者sql,Spring Data JPA会解析方法名帮我们自动创建查询
2.使用方法
自定义方法
/**
* 根据用户名模糊查询和id匹配查询
* @param name
* @param id
* @return
*/
List<User> findUserByUserNameLikeAndUserId(String name, int id);
测试
@Test
public void TestName1(){
List<User> users = userDao.findUserByUserNameLikeAndUserAddress("%张%", "北京");
for (User user : users) {
System.out.println(user);
}
}
3.命名规则
按照Spring Data JPA 定义的规则,查询方法以findBy开头,删除方法以deleteBy...... 涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析。
如果你使用的编译器是idea,当你编写的时候idea也会给出提示。
以上是 Spring Data Jpa的四种查询方式详解 的全部内容, 来源链接: utcz.com/z/349422.html