详解linux正则表达式(基础正则表达式+扩展正则表达式)
正则表达式应用非常广泛,例如:php,Python,java等,但在linux中最常用的正则表达式的命令就是grep(egrep),sed,awk等,换句话 说linux三剑客要想能工作的更高效,就一定离不开正则表达式的配合。
1、什么是正则表达式?
简单的说,正则表达式就是为处理大量的字符串而定义的一套规则和方法。通过定义的这些特殊符号的辅助,系统管理员就可以快速过滤、替换或者输出需要的字符串。linux正则表达式一般以行为单位处理的。
2、为什么要学正则表达式
在企业工作中,我们每天做的linux运维工作中,时刻都会面对大量带有字符串的文本配置、程序、命令输出及日志文件等,而我们经常会有迫切的需要从大量的字符串内容中查找符合工作需要的特定字符串,这就要靠正则表达式,因此,可以说正则表达式就是为过滤这样字符串的需求而生的!
3、容易混淆的两个注意事项:
1)linux正则表达式一般是以行为单位处理的。
2)正则表达式和我们常用的通配符特殊字符是有本质区别的,例如:ls *.txt 这里的*就是通配符(表示所有),不是正则表达式。
注意字符集问题:
确保字符集:export LC_ALL=C
---------------------------------------------
基础正则表达式+扩展正则表达式含义解释:
---------------------------------------------
. 代表且只能代表任意一个字符(不包括空行)
* 重复前面任意0个或多个字符
.* 匹配所有字符。(包括空行)
sed -ri 's#(.*)#\1#g' bqh.txt
把前面正则匹配的括号内的结果,在后面用\1取出来操作。
^ 表示以什么开头,^bqh 以bqh开头
$ 是以什么结尾
^$ 表示空行。
\ 例\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
^.* 以任意多个字符开头。
.*$ 以任意多个字符结尾。
(.*) 从第一字符匹配,到空格停止,
[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别。
a\{n,m\} 重复n到m次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n,\} 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n\} 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
①^word 搜索以word开头的;vi ^ 一行的开够
②word$ 搜索以word结尾的;vi $ 一行的开头
③^$ 表示空行。
扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
? 复0个或一个0前面的字符
| 用或的方式查找多个符合的字符串
() 找出“用户组”字符串
实战举例:
^m 搜索以m开头的
p$搜索以p结尾的
^$表示空号
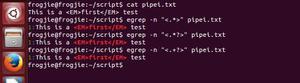
去掉空行:grep –v “^$” bqh.log
查看去掉的后的空行内容:grep -vn “^$” bqh.log
. 代表且只能代表任意一个字符(不包括空行)
查找带0的字符:
.* 匹配所有字符。(包括空行)
查找以.结尾的字符:
错误方法:grep ".$" bqh.log
正确方法:
grep “\.$” bqh.log
注意:\. 就只代表点本身,转义符号,让有着特殊身份移动的字符,脱掉马甲,还原原型\$
* 例1*重复1个或多个前面的一个字符。
grep –o “1*” bqh.log //-o精确匹配
^.* 以任意多个字符开头。
.*$ 以任意多个字符结尾。
[abc] 匹配字符集合内的任意一个字符【a-zA-Z】
匹配字符集合内的a-z任意一个小写字符:
[^abc] 匹配不包括^后的任意字符的内容;中括号里的^为取反,注意和以...开头区别
匹配非数字的任意字符:
a\{n,m\} 重复n到m次,前一个重复的字符。如果有用egrep/sed -r /grep -E可以去掉斜线。
\{n,\} 重复至少n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
\{n\} 重复n次,前一个重复的字符。如果有用egrep/sed -r 可以去掉斜线。
注意:egrep,grep -E或sed -r过滤一般特殊字符可以不转义。多使用参数。
---------------------------------------------------------------------------------
扩展的正则表达式:ERP(egrep或grep -E)
+ 重复一个或一个以上前面的字符
? 复0个或一个0前面的字符
| 用或的方式查找多个符合的字符串
() 找出“用户组”字符串
总结
以上所述是小编给大家介绍的详解linux正则表达式(基础正则表达式+扩展正则表达式),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
以上是 详解linux正则表达式(基础正则表达式+扩展正则表达式) 的全部内容, 来源链接: utcz.com/z/342163.html