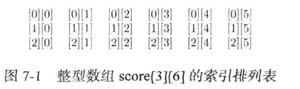
创建一个非重复值的子集,没有来自 R 中向量的第一个重复项。
通常,重复值在第一次出现后被考虑,但第一次出现的值也是其余值的重复值,因此我们可能也想排除它。
借助带有否定运算符的重复函数,可以轻松完成 R 中向量的非重复值的子集化,如下面给出的示例所示。
示例 1
以下代码段创建了一个示例数据框 -
x1<-rpois(200,100)x1
创建以下数据框 -
[1] 109 108 91 101 96 89 87 80 106 89 92 95 106 111 100 101 96 96[19] 81 101 101 101 107 97 87 100 94 98 110 98 95 99 102 103 98 92
[37] 105 115 83 109 93 110 110 112 94 87 94 100 115 97 111 109 97 100
[55] 122 96 93 92 99 105 111 93 115 93 111 117 94 85 98 92 109 114
[73] 92 104 106 97 125 104 87 111 107 106 109 106 96 106 83 105 102 94
[91] 101 116 121 89 96 90 96 131 113 93 105 97 87 111 99 111 106 100
[109] 93 93 99 105 84 108 101 102 109 94 94 76 92 97 96 95 107 113
[127] 96 105 88 86 100 81 87 98 104 113 93 86 85 101 98 108 93 103
[145] 96 109 111 107 97 82 101 106 91 96 103 94 102 88 107 115 122 97
[163] 105 123 103 109 120 84 120 90 95 95 103 98 95 112 103 111 104 92
[181] 86 84 103 101 97 95 94 117 97 85 104 89 95 83 90 101 94 102
[199] 92 102
要对 x1 中的非重复值进行子集化并排除上面创建的数据框中的第一个重复项,请将以下代码添加到上面的代码段中 -
x1<-rpois(200,100)输出结果x1[!(duplicated(x1)|duplicated(x1,fromLast=TRUE))]
如果您将上述所有给定的片段作为单个程序执行,它会生成以下输出 -
[1] 80 114 125 116 121 131 76 82 123
示例 2
以下代码段创建了一个示例数据框 -
x2<-rpois(200,50)x2
创建以下数据框 -
[1] 45 55 42 49 57 51 56 51 54 43 49 53 56 53 47 46 63 72 49 63 61 48 53 51 36[26] 52 56 52 46 41 53 48 50 51 60 47 48 48 54 46 53 48 40 53 45 53 45 48 43
49
[51] 59 45 56 52 58 48 64 32 49 48 42 49 37 46 61 55 48 45 54 48 54 64 57 52
54
[76] 67 40 44 58 46 48 43 57 44 47 51 39 51 45 51 50 39 51 33 51 51 48 57 51
55
[101] 53 45 54 44 55 43 48 42 50 44 45 61 54 48 60 28 50 49 55 47 66 41 54 55
45
[126] 44 50 48 37 46 61 44 57 55 43 52 68 36 52 33 53 48 49 55 69 55 45 49 41
47
[151] 45 42 51 56 46 55 43 47 53 53 39 49 60 47 49 45 47 52 53 52 52 41 57 48
45
[176] 47 49 61 43 60 53 45 47 56 49 52 47 56 50 67 40 60 54 39 34 51 55 52 38
51
要对 x2 中的非重复值进行子集化,排除上面创建的数据框中的第一个重复项,请将以下代码添加到上面的代码段中 -
x2<-rpois(200,50)输出结果x2[!(duplicated(x2)|duplicated(x2,fromLast=TRUE))]
如果您将上述所有给定的片段作为单个程序执行,它会生成以下输出 -
[1] 72 59 32 28 66 68 69 34 38
示例 3
以下代码段创建了一个示例数据框 -
x3<-sample(1:100,200,replace=TRUE)x3
创建以下数据框 -
[1] 44 53 51 89 97 9 40 65 95 76 22 2 53 71 64 33 61 97[19] 1 100 18 15 97 10 57 31 19 2 53 98 67 67 73 11 43 21
[37] 13 56 78 36 7 74 97 59 36 39 43 47 12 58 69 67 70 49
[55] 100 74 43 35 14 26 86 24 38 46 2 98 74 88 95 33 75 35
[73] 12 66 14 60 77 59 74 84 26 3 13 93 77 33 3 93 81 47
[91] 64 5 13 37 23 43 47 5 21 32 75 22 82 78 9 88 76 26
[109] 69 8 15 39 29 15 5 53 57 94 57 26 95 12 38 4 41 90
[127] 6 76 2 32 56 42 62 38 39 88 26 26 87 9 51 89 24 56
[145] 60 52 70 23 33 99 19 58 58 97 40 29 88 38 5 74 18 63
[163] 53 60 19 17 40 45 81 13 16 21 97 20 89 57 52 87 65 80
[181] 26 78 83 16 69 32 84 60 69 94 98 26 57 73 73 46 15 71
[199] 73 8
要对 x3 中的非重复值进行子集化,排除上面创建的数据框中的第一个重复项,请将以下代码添加到上面的代码段中 -
x3<-sample(1:100,200,replace=TRUE)输出结果x3[!(duplicated(x3)|duplicated(x3,fromLast=TRUE))]
如果您将上述所有给定的片段作为单个程序执行,它会生成以下输出 -
[1] 40 47 76 18 10 83 22 26 58 21 45 48 92 3 63 73 32 72 49 38 93
示例 4
以下代码段创建了一个示例数据框 -
x4<-round(rnorm(200,5,1.73),1)x4
创建以下数据框 -
[1] 3.0 6.9 8.2 6.5 3.2 5.3 6.7 2.9 4.9 4.3 5.2 6.2 7.4 3.3 7.1[16] 1.2 1.7 4.2 5.2 4.3 6.3 5.8 2.6 4.2 6.0 5.3 4.6 5.3 4.1
7.0
[31] 5.6 3.2 3.5 4.3 6.3 1.6 3.2 5.4 5.9 5.6 5.0 5.4 0.8 2.5
4.1
[46] 4.3 6.8 5.9 5.1 4.0 5.2 6.5 4.2 1.7 6.3 5.6 2.4 7.7 8.6
5.9
[61] 5.0 3.5 4.0 4.9 6.8 6.3 1.4 6.4 1.9 6.7 6.1 6.2 5.5 2.2
7.7
[76] 3.8 5.9 6.7 3.6 4.1 2.8 4.9 3.9 5.5 1.3 8.2 4.5 6.5 5.3
8.7
[91] 6.9 4.2 4.8 5.1 7.5 5.4 6.8 6.1 5.0 2.2 4.3 8.0 3.5 4.6
4.3
[106] 4.1 2.7 2.3 5.5 4.6 8.5 8.8 7.1 5.8 7.1 5.5 4.6 4.6 7.7
3.4
[121] 4.4 6.3 2.2 2.8 1.4 4.8 2.9 6.7 7.7 6.0 3.2 3.9 7.1 5.8
4.2
[136] 7.8 2.8 4.7 3.2 7.8 3.9 2.4 4.6 4.4 5.5 7.4 6.2 4.5 1.3
3.2
[151] 5.8 4.2 4.5 3.1 5.4 7.6 5.1 5.3 6.3 6.9 6.9 5.3 5.2 5.4 -
2.8
[166] 5.8 8.0 7.3 3.3 4.0 6.1 4.7 5.2 6.7 7.1 4.4 6.2 2.5 4.1
3.7
[181] 6.0 5.3 5.5 9.3 5.3 6.0 2.9 3.6 4.7 5.4 3.4 6.8 6.3 5.1
6.2
[196] 7.8 3.2 4.5 5.7 3.1
要对 x4 中的非重复值进行子集化,排除上面创建的数据框中的第一个重复项,请将以下代码添加到上面的代码段中 -
x4<-round(rnorm(200,5,1.73),1)输出结果x4[!(duplicated(x4)|duplicated(x4,fromLast=TRUE))]
如果您将上述所有给定的片段作为单个程序执行,它会生成以下输出 -
[1] 3.0 1.2 2.6 7.0 1.6 0.8 8.6 6.4 1.9 3.8 8.7 7.5 2.7 2.3 8.5[16] 8.8 7.6 -2.8 7.3 3.7 9.3 5.
例 5
以下代码段创建了一个示例数据框 -
x5<-round(rnorm(200,50,8),0)x5
创建以下数据框 -
[1] 37 43 50 56 39 48 45 47 66 63 47 38 53 50 48 50 50 61 45 37 56 59 59 56 50[26] 49 46 39 40 46 41 58 46 54 44 59 47 29 51 56 36 42 68 41 52 49 56 65 52
49
[51] 59 50 51 53 53 47 44 56 41 49 55 63 51 50 52 47 40 48 55 44 44 51 43 53
52
[76] 45 56 41 43 36 42 48 41 58 57 50 52 53 50 54 46 54 42 45 46 54 28 44 45
40
[101] 33 45 35 64 49 49 47 39 47 41 48 52 58 64 56 45 54 45 42 43 37 46 53 56
49
[126] 48 53 52 33 51 64 43 67 38 52 51 44 63 56 54 58 55 46 58 53 60 46 45 47
66
[151] 54 53 56 68 47 53 54 40 45 44 63 46 45 51 51 52 46 60 40 40 55 56 48 57
48
[176] 53 60 68 61 52 46 57 47 67 51 44 54 37 70 55 65 46 51 53 49 53 44 61 54
54
要对 x5 中的非重复值进行子集化并排除上面创建的数据框中的第一个重复项,请将以下代码添加到上面的代码段中 -
x5<-round(rnorm(200,50,8),0)输出结果x5[!(duplicated(x5)|duplicated(x5,fromLast=TRUE))]
如果您将上述所有给定的片段作为单个程序执行,它会生成以下输出 -
[1] 29 28 35 70
以上是 创建一个非重复值的子集,没有来自 R 中向量的第一个重复项。 的全部内容, 来源链接: utcz.com/z/335409.html