Java工作中常见的并发问题处理方法总结
问题复现
1. “设备Aの奇怪分身”
时间回到很久很久以前的一个深夜,那时我开发的多媒体广告播放控制系统刚刚投产上线,公司开出的第一家线下生鲜店里,几十个大大小小的多媒体硬件设备正常联网后,正由我一台一台的注册及接入到已经上线的多媒体广告播控系统中。
注册过程简述如下:
每一个设备注册到系统中后,相应的在数据库设备表中都会新增一条记录,来存储这个设备的各项信息。
本来一切都有条不紊的进行着,直到设备A的注册打破了这默契的宁静……
设备A注册完成后,我突然发现,数据库设备表中,新增了两条记录,而且是两条一模一样的记录!
我开始以为自己眼花了……
仔细一看,确确实实是新增了两条,而且连设备唯一标识(划横线,后面要考)和创建时间都一模一样!
看着屏幕,我陷入了沉思……
为什么会有两条呢?
在我的注册逻辑里,落库之前会先查一遍数据库该设备是否已存在,如果存在就更新已有的,不存在才新增。
所以我百思不得其解,按这个逻辑,第二条一模一样的数据是哪来的?
2. 真相背后的并发请求
经过一番排查及思考,我发现问题可能就出在注册请求上。
设备A在向云端发送http注册请求时,可能会同时发送多个相同请求。
云服务器当时部署在多台Docker容器上,通过查看日志发现,有两台容器同时收到了来自设备A的注册请求。
由此,我推测:
设备A同时发送了两个注册请求,这两个请求分别在同一时间打到了云端的不同容器上,按照我的注册逻辑,这两个容器接收到注册请求后,同时去查询了数据库的设备表,这时候设备表里还没有设备A的记录,所以两台容器都执行了新增的操作,因为速度很快,所以这两条新增记录在精确到秒的创建时间上,并没有体现出差别。
3. 并发新增的延伸
既然并发的新增操作会产生问题,那么并发的更新操作是否会有问题呢?
解决方法
解决并发新增
1. 数据库唯一索引(UNIQUE INDEX)
在数据库建表的时候,通过对具有唯一性的字段(比如上述的设备唯一标识)创建唯一索引,或对组合起来后就具备唯一性的几个字段创建联合唯一索引。
这样在并发新增时,只要有一个新增成功,其他的新增操作都会因为数据库抛出的异常(java.sql.SQLIntegrityConstraintViolationException)而失败,我们只需要处理好新增失败的情况就行了。
注意唯一索引的字段需要非空,因为字段值为空时会导致唯一索引约束失效
2. java分布式锁
通过在程序中引入分布式锁,在进行新增操作前需要先获取分布式锁,获取成功才能继续,否则新增失败。
这样也能解决并发插入带来的数据重复问题,只是引入分布式锁的同时也增加了系统的复杂性,如果要落库的数据上有唯一性字段的话,还是推荐采用唯一索引的方法。
在构建分布式锁的过程中,我们需要用到Redis,这里以设备注册时使用的分布式锁为例。
分布式锁简单问答:
Q:锁究竟是什么?
A:锁实质上是存储在Redis中,基于特定规则生成的一个字符串(示例里是固定前缀+设备唯一标识),相当于每个设备注册的时候都有自己对应的一把锁,因为锁只有一把,即使该设备有多个相同的注册请求同时到来,也只有其中获取到那把锁的那一个请求能成功走下去。
Q:什么是获取锁?
A:同一个设备,基于相同的规则生成的字符串(后文以Key代称该字符串)总是相同的,在执行新增操作前,先去Redis中查询这个Key是否存在,如果已存在,就意味着获取锁失败;如果不存在,就将这个Key现存到Redis中,如果存储成功,表示获取锁成功,如果存储失败,还是意味着获取锁失败。
Q:锁是怎么工作的?
A:前面说过,同一个设备,基于相同的规则生成的字符串(Key)总是相同的,在当前线程执行新增操作前,先在Redis中查询这个Key是否存在,如果已存在,表示此时已经有别的线程成功获取了锁,正在做当前线程想要做的新增操作,则当前线程不需要进行后续操作了(是的,你是多余的)
当这个Key不存在时,表示现在还没有其他线程获得锁,则当前线程可以继续进行下一步操作——在Redis中赶紧存入这个Key,当这个Key存储失败时,意味着有别的线程抢先存入了Key成功获取了锁,当前线程晚了一步,想做的工作被别人抢先做了(当前线程可以退下了)
当且仅当在Redis中存入这个Key也成功时,表示当前线程终于获取锁成功,可以安心进行后面的新增操作了,期间别的想做相同新增操作的线程因为获取不到锁,只能全都退场拜拜????,当前线程执行完后要记得释放锁(从Redis中删除这个Key)。
注册时使用的分布式锁代码如下:
public class LockUtil {
// 对redis底层set/get方法进行了简单封装的工具类
@Autowired
private RedisService redisService;
// 生成锁的固定前缀,从配置文件读取值
@Value("${redis.register.prefix}")
private String REDIS_REGISTER_KEY_PREFIX;
// 锁过期时间:即获取锁后线程能进行操作的最长时间,超过该时间后锁自动被释放(失效),别人可以重新开始获取锁进行对应操作
// 设定锁过期时间是为了防止某线程成功获取锁后在执行任务过程中发生意外挂掉了造成锁永远无法被释放
@Value("${redis.register.timeout}")
private Long REDIS_REGISTER_TIMEOUT;
/**
* 获取设备注册时的分布式锁
* @param deviceMacAddress 设备的Mac地址
* @return
*/
public boolean getRegisterLock(String deviceMacAddress) {
if (StringUtils.isEmpty(deviceMacAddress)) {
return false;
}
// 获取设备对应锁的字符串(Key)
String redisKey = getRegisterLockKey(deviceMacAddress);
// 开始尝试获取锁
// 如果当前任务锁key已存在,则表示当前时间内有其他线程正在对该设备执行任务,当前线程可以退下了
if (redisService.exists(redisKey)){
return false;
}
// 开始尝试加锁,注意此处需使用SETNX指令(因为可能存在多个线程同时到达这一步开始加锁,使用SETNX来确保有且仅有一个设置成功返回)
boolean setLock = redisService.setNX(redisKey, null);
// 开始尝试设置锁过期时间,到了过期时间线程还没有释放锁的话,由保存锁的Redis来确保锁最终被释放,以免出现死锁
// 锁过期时间的设置上,可以评估线程执行任务的正常用时,在正常用时的基础上稍微再大一点
boolean setExpire = redisService.expire(redisKey, REDIS_REGISTER_TIMEOUT);
// 设置锁和设置过期时间均成功时才认为当前线程获取锁成功,否则认为获取锁失败
if (setLock && setExpire) {
return true;
}
// 当发生设置锁成功,但设置过期时间失败的情况时,手动清除刚刚设置的锁Key
redisService.del(redisKey);
return false;
}
/**
* 删除设备注册时的分布式锁
* @param deviceMacAddress 设备的Mac地址
*/
public void delRegisterLock(String deviceMacAddress) {
redisService.del(getRegisterLockKey(deviceMacAddress));
}
/**
* 获取设备注册时分布式锁的key
* @param deviceMacAddress 设备mac地址(每个设备的mac地址都是唯一的)
* @return
*/
private String getRegisterLockKey(String deviceMacAddress) {
return REDIS_REGISTER_KEY_PREFIX + "_" + deviceMacAddress;
}
}
在正常的注册逻辑中使用锁的示例如下:
public ReturnObj registry(@RequestBody String device){
Devices deviceInfo = JSON.parseObject(device, Devices.class);
// 开始注册前加锁
boolean registerLock = lockUtil.getRegisterLock(deviceInfo.getMacAddress());
if (!registerLock) {
log.info("获取设备注册锁失败,当前注册请求失败!");
return ReturnObj.createBussinessErrorResult();
}
// 加锁成功,开始注册设备
ReturnObj result = registerDevice(deviceInfo);
// 注册设备完成,删除锁
lockUtil.delRegisterLock(deviceInfo.getMacAddress());
return result;
}
解决并发更新
1. 并发更新真的会引发问题吗?
当发生同时更新或一前一后更新的情况对业务并无影响的时候,那就无需进行任何处理,免得徒劳增加系统复杂度。
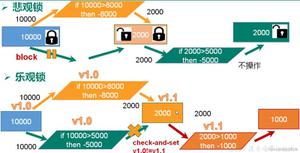
2. 乐观锁
通过乐观锁的方式可以避免重复更新,即:在数据库表中加入一个“版本号”(version)的字段,在做更新操作前先查询记录,记下查询出的版本号,之后在实际更新操作的时候判断此前查询出的版本号是否与当前数据库中该条记录的版本号一致,如果一致,说明在当前线程从查询到更新这段时间里,没有其他线程更新这条记录;如果不一致,说明再此期间已经有其他线程更改了这条记录,当前线程的更新操作已经不安全了,只能放弃。
判断SQL示例:
update a_table set name=test1, age=12, version=version+1 where id = 3 and version = 1
乐观锁通过版本号的方式,在最后更新的关头才判断自己之前从数据库读取的数据有没有被别人修改,其效率高于悲观锁,因为在当前线程查询和最后更新前的这段时间里,其他线程可以照常读取这同一条记录,且可以抢先更新。
悲观锁
悲观锁与乐观锁恰好相反,在当前线程查询这条待更新的数据时,就锁住了这条数据,不允许在自己更新完成前有其他线程修改数据。
通过使用 select … for update 来告诉数据库“我马上要更新这条数据,把它给我锁起来”。
注意:FOR UPDATE 仅适用于InnoDB,且必须在事务中才能生效,当查询条件有明确主键且有此记录时为行锁定(row lock,只锁定根据查询条件定位到的这一行数据),查询条件无主键或主键不明确时为表锁定(table lock,锁定全表,会造成全表的数据在锁定期都无法被更改),所以使用悲观锁时查询条件最好能明确定位到某一行或几行,不要引发全表锁定
到此这篇关于Java工作中常见的并发问题处理方法总结的文章就介绍到这了,更多相关Java工作中并发问题内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Java工作中常见的并发问题处理方法总结 的全部内容, 来源链接: utcz.com/z/327688.html