如何删除R数据帧列中连续重复的重复项?
通常会重复使用会在数据中产生重复的值,并且如果它们不太可能在分析的输出中造成偏差,我们可能希望摆脱这些值。例如,如果我们有一列定义一个流程,并且我们对该流程的输出进行五次操作,但一直都采用相同的输出,那么我们可能只想使用一个输出。
例1
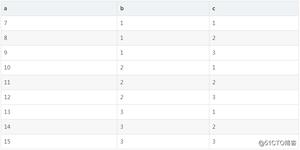
请看以下数据帧-
ID<−1:20x<−sample(0:2,20,replace=TRUE)
df1<−data.frame(ID,x)
df1
输出结果
ID x1 1 1
2 2 1
3 3 0
4 4 1
5 5 0
6 6 2
7 7 1
8 8 1
9 9 1
10 10 2
11 11 2
12 12 1
13 13 2
14 14 2
15 15 0
16 16 1
17 17 2
18 18 1
19 19 1
20 20 0
删除df1列中连续重复的重复项x-
Repeated1<−cumsum(rle(as.character(df1$x))$length)df1[Repeated1,]
输出结果
ID x2 2 1
3 3 0
4 4 1
5 5 0
6 6 2
9 9 1
11 11 2
12 12 1
14 14 2
15 15 0
16 16 1
17 17 2
19 19 1
20 20 0
例2
ID<−1:20y<−sample(1:5,20,replace=TRUE)
df2<−data.frame(ID,y)
df2
输出结果
ID y1 1 1
2 2 5
3 3 1
4 4 2
5 5 5
6 6 1
7 7 2
8 8 1
9 9 1
10 10 4
11 11 4
12 12 2
13 13 3
14 14 4
15 15 5
16 16 4
17 17 1
18 18 1
19 19 5
20 20 4
删除df2列y中连续重复的重复项-
Repeated2<−cumsum(rle(as.character(df2$y))$length)df2[Repeated2,]
输出结果
ID y1 1 1
2 2 5
3 3 1
4 4 2
5 5 5
6 6 1
7 7 2
9 9 1
11 11 4
12 12 2
13 13 3
14 14 4
15 15 5
16 16 4
18 18 1
19 19 5
20 20 4
例子3
ID<−1:20z<−sample(11:13,20,replace=TRUE)
df3<−data.frame(ID,z)
df3
输出结果
ID z1 1 12
2 2 13
3 3 13
4 4 13
5 5 11
6 6 12
7 7 12
8 8 13
9 9 12
10 10 13
11 11 13
12 12 12
13 13 12
14 14 13
15 15 13
16 16 13
17 17 12
18 18 12
19 19 12
20 20 13
在df3列z中删除连续重复的重复项-
Repeated3<−cumsum(rle(as.character(df3$z))$length)df3[Repeated3,]
输出结果
ID z1 1 12
4 4 13
5 5 11
7 7 12
8 8 13
9 9 12
11 11 13
13 13 12
16 16 13
19 19 12
20 20 13
以上是 如何删除R数据帧列中连续重复的重复项? 的全部内容, 来源链接: utcz.com/z/326939.html