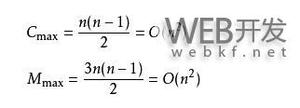详解python算法之冒泡排序
概念: 重复地走访过要排序的元素列,依次比较两个相邻的元素,如果他们的顺序(如从大到小、首字母从A到Z)错误就把他们交换过来。走访元素的工作是重复地进行直到没有相邻元素需要交换,也就是说该元素已经排序完成
这个算法的名字由来是因为越大的元素会经由交换慢慢“浮”到数列的顶端(升序或降序排列),就如同碳酸饮料中二氧化碳的气泡最终会上浮到顶端一样,故名“冒泡排序”。
算法原理
排序算法" title="冒泡排序算法">冒泡排序算法的原理如下:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。
对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
针对所有的元素重复以上的步骤,除了最后一个。
持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
算法分析
时间复杂度
若文件的初始状态是正序的,一趟扫描即可完成排序。所需的关键字比较次数
和记录移动次数 均达到最小值: , 。
所以,冒泡排序最好的时间复杂度为 。
冒泡排序的最坏时间复杂度为
代码实现
伪代码
function bubble_sort (array, length) {
var i, j;
for(i from 1 to length-1){
for(j from 0 to length-1-i){
if (array[j] > array[j+1])
swap(array[j], array[j+1])
}
}
}
伪代码解释
函数 冒泡排序 输入 一个数组名称为array 其长度为length
i 从 1 到 (length - 1)
j 从 0 到 (length - 1 - i)
如果 array[j] > array[j + 1]
交换 array[j] 和 array[j + 1] 的值
如果结束
j循环结束
i循环结束
函数结束
助记码
i∈[0,N-1) //循环N-1遍
j∈[0,N-1-i) //每遍循环要处理的无序部分
swap(j,j+1) //两两排序(升序/降序)
python代码
#-*-coding:utf-8-*-
'''冒泡排序也称 bubble sort从小到大排序'''
import time
def bubble_sort(lst):
'''冒泡排序'''
# 第一次循环
for n in range(len(lst) - 1, 0, -1): #计算原列表的长度-1,取倒序索引
for i in range(n):
if lst[i] > lst[i + 1]: # 比较最后一个与倒数第二个数的值,如果倒数第二个的值,大于最后一个的值
temp = lst[i] # 则将倒数第二个值赋值给临时变量temp
lst[i] = lst[i + 1] # 替换原列表中倒数第二个索引的值为最后一个
lst[i + 1] = temp # 同时改变原列表中最后一个索引值为倒数第二个的值
return lst
if __name__ == "__main__":
lst = [54, 26, 93, 17, 77, 31, 44, 55, 20]
af_sort=bubble_sort(lst)
print(af_sort)
总结冒泡排序的实现(类似下面)通常会对已经排序好的数列拙劣地运行(),而插入排序在这个例子只需要个运算。算法的核心知识点是: 循环比较, 交叉换位!
以上是 详解python算法之冒泡排序 的全部内容, 来源链接: utcz.com/z/318689.html