详解Java中String类型与默认字符编码
为什么写这个
至于为什么要写这个,主要是一句mmp一定要讲,绕了一上午,晕死
Java程序中的中文乱码问题一直是一个困扰程序员的难题,自己也不例外,早在做项目时就遇到过很多编码方式的坑,当时想填来着,但是嫌麻烦。这次终于忍不住了,一定要弄个明白
String类型的编码方式
从网上查的资料都说,Java默认的字符编码是Unicode,而String类型的编码方式是与JVM编码方式和本机操作系统默认字符集有关的。于是我做出了测试
在Java中可以这样显示查看本地编码方式(JVM还是OS呢?)
// Gets the system property indicated by the specified key.
System.out.println(System.getProperty(file.encoding));
看注释上说是获取系统字符集,但是我对这个系统的概念表示存疑,为什么呢,因为众所周知,我们中国人的电脑大部分默认的字符编码方式就是GBK,在CMD中输入chcp可以获得一个数值936,这就表示了是GBK的编码方式。
但是我自己运行出这句话的结果竟然是UTF-8,我是在IDEA中运行的,并且已经使用IDEA设置了项目的编码方式是UTF-8,出现这样的结果我只能是猜测其实上面这句话是获取JVM(跟随项目的编码方式)的编码方式
接下来我们来回归正题,String类型的默认编码方式是什么,有下面这几句语句:
/* 测试String类型默认的编码方式
*/
// 使用String的有参构造方法
String str = new String("hhhh ty智障%shfu摸淑芬十分uif内服NSF黑");
// 1.以GBK编码方式获取str的字节数组,再用String有参构造函数构造字符串
System.out.println(new String(str.getBytes("GBK")));
// 2.以UTF-8编码方式获取str的字节数组,再以默认编码构造字符串
System.out.println(new String(str.getBytes("UTF-8")));
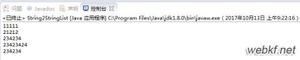
下面来看一下运行结果:
// 1.
hhhh ty����%shfu�����ʮ��uif�ڷ�NSF��i����ظ���u��Ϊ��ؼu ��δ���δ��� hhhh ty智障%shfu摸淑芬十分uif内服NSF黑i飞鸟回复额u发为呢丶u 房未婚夫未婚夫
// 2.
hhhh ty智障%shfu摸淑芬十分uif内服NSF黑i飞鸟回复额u发为呢丶u 房未婚夫未婚夫
可以很明显的可以看出,这里String类型默认的字符编码方式就是与我们查看本地系统的编码方式相同。因此我们得出结论:String类型的默认编码方式是和本地编码方式相关
String.getBytes()方法
我们大多数情况下是不使用String类型的,而是使用byte数组来传输操作数据,一般会使用String.getBytes()方法来将字符串转换成字节数组。但是这样转换的时候,会不会牵涉到编码问题呢?仔细查看了String.getBytes()的源码,分为无参的和有参的两种:
// 1.无参的getBytes()方法
public byte[] getBytes() {
// 再继续深入encode()方法可以发现使用的是系统默认的字符编码
return StringCoding.encode(value, 0, value.length);
}
// 2.带参数的getBytes(String charsetName)方法
public byte[] getBytes(String charsetName)
throws UnsupportedEncodingException {
if (charsetName == null) throw new NullPointerException();
// 继续深入可以发现,会使用参数字符集编码方式来返回字节数组,如果参数字符集不存在,则使用本地系统默认的字符编码
return StringCoding.encode(charsetName, value, 0, value.length);
}
综上,在这里再强调一下,因为修改了项目的编码方式,导致了本地系统的编码方式也变成了UTF-8,所以上述的实验都是基于IDE修改了工程项目编码方式的基础上
ByteBuffer与byte数组的互相转换
在NIO中,一般都是使用ByteBuffer来当作字符缓冲,而有的时候我们只有byte[]数组,所以是需要它们之间进行相互转换的
// ByteBuffer ----> byte[]
byte[] bytes = ByteBuffer.array();
// byte[] ------> ByteBuffer
byte[] bytes = new byte[1024];
ByteBuffer byteBuffer = ByteBuffer.wrap(bytes);
So
综上所述,再在这里总结一下:
- 本地JVM的编码方式是和本机OS默认的字符编码方式相关的,但是JVM的编码方式可以被修改
- Java程序的默认字符集是Unicode,在程序中声明的String类型的编码方式是和JVM编码方式相关的
- String.getBytes()方法默认的编码方式是JVM编码方式;同时还可以接收一个字符集名称当作参数,优先使用参数的字符集
- 因为Java代码使用的Unicode字符集,允许各编码方式之间转换,但不保证bit损失,所以String类型可以得到不同编码方式的byte数组,只要按照编码解码的方式获取字符串类型显示即可
- 文件的流通道是根据文件的编码方式决定的,所以不同编码方式的文件读写时要注意编码解码
- ByteBuffer声明的buffer可以与byte数组之间进行转换,但要注意的是ByteBuffer的大小一定要足够大以承载下所有的byte数组
小总结
搞清楚了这些甚是豁然开朗,其实很多时候中文的乱码问题根源就是编码方式与解码方式不一致,或者是不同编码方式之间转换时造成了bit损失。所以我们还是要注意规范化编码与解码方式,毕竟有的转换操作是不可逆的。
以上所述是小编给大家介绍的Java中String类型与默认字符编码详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
以上是 详解Java中String类型与默认字符编码 的全部内容, 来源链接: utcz.com/z/318624.html