Java IO流常用字节字符流原理解析
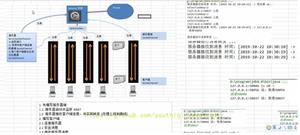
Java的流体系十分庞大,我们来看看体系图:
这么庞大的体系里面,常用的就那么几个,我们把它们抽取出来,如下图:
一:字节流
1:字节输入流
字节输入流的抽象基类是InputStream,常用的子类是 FileInputStream和BufferedInputStream。
1)FileInputStream
文件字节输入流:一切文件在系统中都是以字节的形式保存的,无论你是文档文件、视频文件、音频文件...,需要读取这些文件都可以用FileInputStream去读取其保存在存储介质(磁盘等)上的字节序列。
FileInputStream在创建时通过把文件名作为构造参数连接到该文件的字节内容,建立起字节流传输通道。
然后通过 read()、read(byte[])、read(byte[],int begin,int len) 三种方法从字节流中读取 一个字节、一组字节。
2)BufferedInputStream
带缓冲的字节输入流:上面我们知道文件字节输入流的读取时,是直接同字节流中读取的。由于字节流是与硬件(存储介质)进行的读取,所以速度较慢。而CPU需要使用数据时通过read()、read(byte[])读取数据时就要受到硬件IO的慢速度限制。我们又知道,CPU与内存发生的读写速度比硬件IO快10倍不止,所以优化读写的思路就有了:在内存中建立缓存区,先把存储介质中的字节读取到缓存区中。CPU需要数据时直接从缓冲区读就行了,缓冲区要足够大,在被读完后又触发fill()函数自动从存储介质的文件字节内容中读取字节存储到缓冲区数组。
BufferedInputStream 内部有一个缓冲区,默认大小为8M,每次调用read方法的时候,它首先尝试从缓冲区里读取数据,若读取失败(缓冲区无可读数据),则选择从物理数据源 (譬如文件)读取新数据(这里会尝试尽可能读取多的字节)放入到缓冲区中,最后再将缓冲区中的内容返回给用户.由于从缓冲区里读取数据远比直接从存储介质读取速度快,所以BufferedInputStream的效率很高。
public class OutputStreamWriter extends Writer {
// 流编码类,所有操作都交给它完成。
private final StreamEncoder se;
// 创建使用指定字符的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, String charsetName)
throws UnsupportedEncodingException
{
super(out);
if (charsetName == null)
throw new NullPointerException("charsetName");
se = StreamEncoder.forOutputStreamWriter(out, this, charsetName);
}
// 创建使用默认字符的OutputStreamWriter。
public OutputStreamWriter(OutputStream out) {
super(out);
try {
se = StreamEncoder.forOutputStreamWriter(out, this, (String)null);
}
catch (UnsupportedEncodingException e) {
throw new Error(e);
}
}
// 创建使用指定字符集的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, Charset cs) {
super(out);
if (cs == null)
throw new NullPointerException("charset");
se = StreamEncoder.forOutputStreamWriter(out, this, cs);
}
// 创建使用指定字符集编码器的OutputStreamWriter。
public OutputStreamWriter(OutputStream out, CharsetEncoder enc) {
super(out);
if (enc == null)
throw new NullPointerException("charset encoder");
se = StreamEncoder.forOutputStreamWriter(out, this, enc);
}
// 返回该流使用的字符编码名。如果流已经关闭,则此方法可能返回 null。
public String getEncoding() {
return se.getEncoding();
}
// 刷新输出缓冲区到底层字节流,而不刷新字节流本身。该方法可以被PrintStream调用。
void flushBuffer() throws IOException {
se.flushBuffer();
}
// 写入单个字符
public void write(int c) throws IOException {
se.write(c);
}
// 写入字符数组的一部分
public void write(char cbuf[], int off, int len) throws IOException {
se.write(cbuf, off, len);
}
// 写入字符串的一部分
public void write(String str, int off, int len) throws IOException {
se.write(str, off, len);
}
// 刷新该流。可以发现,刷新缓冲区其实是通过流编码类的flush()实现的,故可以看出,缓冲区是流编码类自带的而不是OutputStreamWriter实现的。
public void flush() throws IOException {
se.flush();
}
// 关闭该流。
public void close() throws IOException {
se.close();
}
}
每次调用 write() 方法都会导致在给定字符(或字符集)上调用编码转换器。在写入底层输出流之前,得到的这些字节将在缓冲区中累积(传递给 write() 方法的字符没有缓冲,输出数组才有缓冲)。为了获得最高效率,可考虑将 OutputStreamWriter 包装到 BufferedWriter 中,以避免频繁调用转换器。
2)BufferedWriter
带缓冲的字符输出流:与OutputStreamWriter的缓冲不同,BufferedWriter的缓冲是真正由自己创建的缓冲数组来实现的。故此:不需要频繁调用编码转换器进行缓冲,而且,它可以提供单个字符、数组和字符串的缓冲(编码转换器只能缓冲字符数组和字符串)。
BufferedWriter可以在创建时把一个OutputStreamWriter进行包装,为输出流建立缓冲;
然后,通过
void write(char[] cbuf, int off, int len)
写入字符数组的某一部分。
void write(int c)
写入单个字符。
void write(String s, int off, int len)
写入字符串的某一部分。
向缓冲区写入数据。
还可以通过
void newLine()
写入一个行分隔符。
最后,可以手动控制缓冲区的数据刷新:
void flush() 刷新该流的缓冲。
以上是 Java IO流常用字节字符流原理解析 的全部内容, 来源链接: utcz.com/z/312052.html