死磕Spring之IoC篇 - BeanDefinition 的解析过程(面向注解)
本文内容纲要:
- BeanDefinition 的解析过程(面向注解)- 类图
- ClassPathBeanDefinitionScanner
- ClassPathScanningCandidateComponentProvider
- 总结
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读
Spring 版本:5.1.14.RELEASE
开始阅读这一系列文章之前,建议先查看《深入了解 Spring IoC(面试题)》这一篇文章
该系列其他文章请查看:《死磕 Spring 之 IoC 篇 - 文章导读》
BeanDefinition 的解析过程(面向注解)
前面的几篇文章对 Spring 解析 XML 文件生成 BeanDefinition 并注册的过程进行了较为详细的分析,这种定义 Bean 的方式是**面向资源(XML)**的方式。面向注解定义 Bean 的方式 Spring 的处理过程又是如何进行的?本文将会分析 Spring 是如何将 @Component 注解或其派生注解 标注的 Class 类解析成 BeanDefinition(Bean 的“前身”)并注册。
在上一篇 《解析自定义标签(XML 文件)》文章中提到了处理 <context:component-scan /> 标签的过程中,底层借助于 ClassPathBeanDefinitionScanner 扫描器,去扫描指定路径下符合条件的 BeanDefinition 们,这个类就是处理 @Component 注解定义 Bean 的底层实现。关于 @ComponentScan 注解的原理也是基于这个扫描器来实现的,我们先来看看这个扫描器的处理过程。
类图
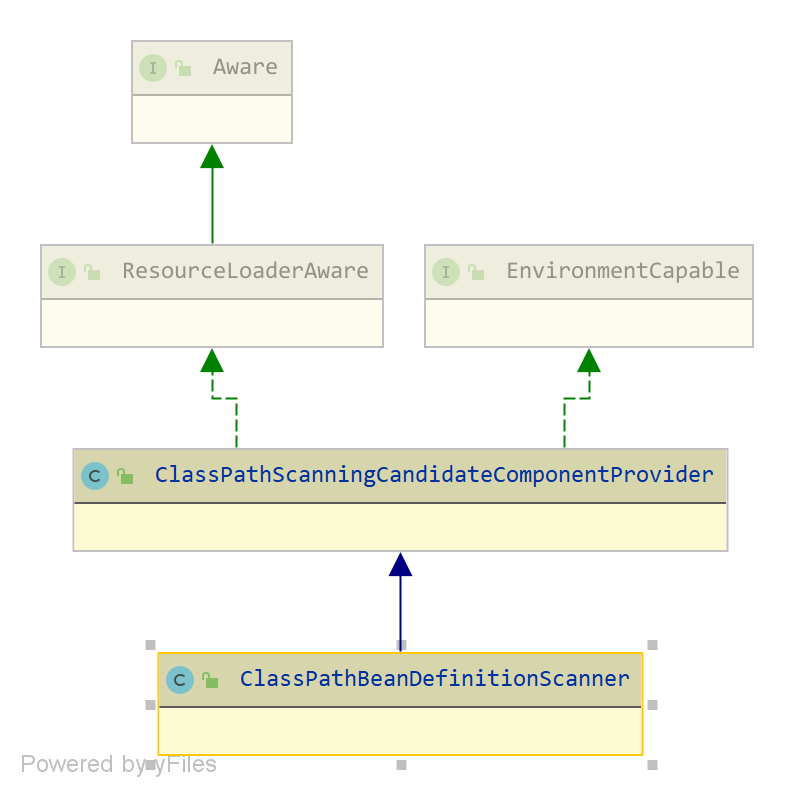
ClassPathBeanDefinitionScanner
org.springframework.context.annotation.ClassPathBeanDefinitionScanner,继承 ClassPathScanningCandidateComponentProvider,classpath 下 BeanDefinition 的扫描器,支持设置过滤器
默认有三个过滤器: @Component 注解的过滤器,Java EE 6 的 javax.annotation.ManagedBean 注解过滤器,JSR-330 的 javax.inject.Named 注解过滤器,这里我们重点关注第一个过滤器
构造函数
public class ClassPathBeanDefinitionScanner extends ClassPathScanningCandidateComponentProvider { /** BeanDefinition 注册中心 DefaultListableBeanFactory */
private final BeanDefinitionRegistry registry;
/** BeanDefinition 的默认配置 */
private BeanDefinitionDefaults beanDefinitionDefaults = new BeanDefinitionDefaults();
@Nullable
private String[] autowireCandidatePatterns;
/** Bean 的名称生成器 */
private BeanNameGenerator beanNameGenerator = new AnnotationBeanNameGenerator();
private ScopeMetadataResolver scopeMetadataResolver = new AnnotationScopeMetadataResolver();
/** 是否注册几个关于注解的 PostProcessor 处理器 */
private boolean includeAnnotationConfig = true;
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry) {
this(registry, true);
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters) {
this(registry, useDefaultFilters, getOrCreateEnvironment(registry));
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment) {
this(registry, useDefaultFilters, environment,
(registry instanceof ResourceLoader ? (ResourceLoader) registry : null));
}
public ClassPathBeanDefinitionScanner(BeanDefinitionRegistry registry, boolean useDefaultFilters,
Environment environment, @Nullable ResourceLoader resourceLoader) {
Assert.notNull(registry, "BeanDefinitionRegistry must not be null");
this.registry = registry;
if (useDefaultFilters) {
// 注册默认的过滤器,@Component 注解的过滤器(具有层次性)
registerDefaultFilters();
}
setEnvironment(environment);
// 设置资源加载对象,会尝试加载出 CandidateComponentsIndex 对象(保存 `META-INF/spring.components` 文件中的内容,不存在该对象为 `null`)
setResourceLoader(resourceLoader);
}
}
属性不多,构造函数都会进入最下面这个构造方法,主要调用了两个方法,如下:
调用父类的
registerDefaultFilters()方法,注册几个默认的过滤器,方法如下:protected void registerDefaultFilters() {// 添加 @Component 注解的过滤器(具有层次性),@Component 的派生注解都符合条件
this.includeFilters.add(new AnnotationTypeFilter(Component.class));
ClassLoader cl = ClassPathScanningCandidateComponentProvider.class.getClassLoader();
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.annotation.ManagedBean", cl)), false));
logger.trace("JSR-250 'javax.annotation.ManagedBean' found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-250 1.1 API (as included in Java EE 6) not available - simply skip.
}
try {
this.includeFilters.add(new AnnotationTypeFilter(
((Class<? extends Annotation>) ClassUtils.forName("javax.inject.Named", cl)), false));
logger.trace("JSR-330 'javax.inject.Named' annotation found and supported for component scanning");
}
catch (ClassNotFoundException ex) {
// JSR-330 API not available - simply skip.
}
}
添加
@Component注解的过滤器(具有层次性),@Component的派生注解都符合条件也会添加 Java EE 6 的
javax.annotation.ManagedBean注解过滤器,JSR-330 的javax.inject.Named注解过滤器调用父类的
setResourceLoader(@Nullable ResourceLoader resourceLoader)方法,设置资源加载对象并尝试加载出 CandidateComponentsIndex 对象,方法如下:@Overridepublic void setResourceLoader(@Nullable ResourceLoader resourceLoader) {
this.resourcePatternResolver = ResourcePatternUtils.getResourcePatternResolver(resourceLoader);
this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader);
// 获取所有 `META-INF/spring.components` 文件中的内容
this.componentsIndex = CandidateComponentsIndexLoader.loadIndex(this.resourcePatternResolver.getClassLoader());
}
这里有个关键的步骤,加载出 CandidateComponentsIndex 对象,尝试去获取所有
META-INF/spring.components文件中的内容,后续进行分析
1. scan 方法
scan(String... basePackages) 方法,扫描出包路径下符合条件 BeanDefinition 并注册,方法如下:
public int scan(String... basePackages) { // <1> 获取扫描前的 BeanDefinition 数量
int beanCountAtScanStart = this.registry.getBeanDefinitionCount();
// <2> 进行扫描,将过滤出来的所有的 .class 文件生成对应的 BeanDefinition 并注册
doScan(basePackages);
// Register annotation config processors, if necessary.
// <3> 如果 `includeAnnotationConfig` 为 `true`(默认),则注册几个关于注解的 PostProcessor 处理器(关键)
// 在其他地方也会注册,内部会进行判断,已注册的处理器不会再注册
if (this.includeAnnotationConfig) {
AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry);
}
// <4> 返回本次扫描注册的 BeanDefinition 数量
return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart);
}
过程如下:
- 获取扫描前的 BeanDefinition 数量
- 进行扫描,将过滤出来的所有的 .class 文件生成对应的 BeanDefinition 并注册,调用
doScan(String... basePackages)方法 - 如果
includeAnnotationConfig为true(默认),则注册几个关于注解的 PostProcessor 处理器(关键),在其他地方也会注册,内部会进行判断,已注册的处理器不会再注册,记住这个 AnnotationConfigUtils 类 - 返回本次扫描注册的 BeanDefinition 数量
2. doScan 方法
doScan(String... basePackages) 方法,扫描出包路径下符合条件 BeanDefinition 并注册,方法如下:
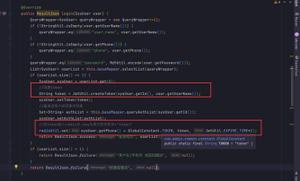
protected Set<BeanDefinitionHolder> doScan(String... basePackages) { Assert.notEmpty(basePackages, "At least one base package must be specified");
// <1> 定义个 Set 集合 `beanDefinitions`,用于保存本次扫描成功注册的 BeanDefinition 们
Set<BeanDefinitionHolder> beanDefinitions = new LinkedHashSet<>();
for (String basePackage : basePackages) { // 遍历需要扫描的包名
// <2> 【核心】扫描包路径,通过 ASM(Java 字节码的操作和分析框架)解析出所有符合条件的 BeanDefinition
Set<BeanDefinition> candidates = findCandidateComponents(basePackage);
// <3> 对第 `2` 步解析出来的 BeanDefinition 依次处理,并注册
for (BeanDefinition candidate : candidates) {
// <3.1> 解析出 @Scope 注解的元信息并设置
ScopeMetadata scopeMetadata = this.scopeMetadataResolver.resolveScopeMetadata(candidate);
candidate.setScope(scopeMetadata.getScopeName());
// <3.2> 获取或者生成一个的名称 `beanName`
String beanName = this.beanNameGenerator.generateBeanName(candidate, this.registry);
// <3.3> 设置相关属性的默认值
if (candidate instanceof AbstractBeanDefinition) {
postProcessBeanDefinition((AbstractBeanDefinition) candidate, beanName);
}
// <3.4> 根据这个类的相关注解设置属性值(存在则会覆盖默认值)
if (candidate instanceof AnnotatedBeanDefinition) {
AnnotationConfigUtils.processCommonDefinitionAnnotations((AnnotatedBeanDefinition) candidate);
}
// <3.5> 检查 beanName 是否已存在,已存在但是不兼容则会抛出异常
if (checkCandidate(beanName, candidate)) {
// <3.6> 将 BeanDefinition 封装成 BeanDefinitionHolder 对象,这里多了一个 `beanName`
BeanDefinitionHolder definitionHolder = new BeanDefinitionHolder(candidate, beanName);
// <3.7> 如果代理模式是 `TARGET_CLASS`,则再创建一个 BeanDefinition 代理对象(重新设置了相关属性),原始 BeanDefinition 已注册
definitionHolder = AnnotationConfigUtils.applyScopedProxyMode(scopeMetadata, definitionHolder, this.registry);
// <3.8> 添加至 `beanDefinitions` 集合
beanDefinitions.add(definitionHolder);
// <3.9> 注册该 BeanDefinition
registerBeanDefinition(definitionHolder, this.registry);
}
}
}
// <4> 返回 `beanDefinitions`(已注册的 BeanDefinition 集合)
return beanDefinitions;
}
过程如下:
定义个 Set 集合
beanDefinitions,用于保存本次扫描成功注册的 BeanDefinition 们**【核心】**扫描包路径,通过 ASM(Java 字节码的操作和分析框架)解析出所有符合条件的 BeanDefinition,调用父类的
findCandidateComponents(String basePackage)方法对第
2步解析出来的 BeanDefinition 依次处理,并注册- 解析出 @Scope 注解的元信息并设置
- 获取或者生成一个的名称
beanName - 设置相关属性的默认值
- 根据这个类的相关注解设置属性值(存在则会覆盖默认值)
- 检查
beanName是否已存在,已存在但是不兼容则会抛出异常 - 将 BeanDefinition 封装成 BeanDefinitionHolder 对象,这里多了一个
beanName - 如果代理模式是
TARGET_CLASS,则再创建一个 BeanDefinition 代理对象(重新设置了相关属性),原始 BeanDefinition 已注册 - 添加至
beanDefinitions集合 - 注册该 BeanDefinition
返回
beanDefinitions(已注册的 BeanDefinition 集合)
第 2 步是这个扫描过程的核心步骤,在父类 ClassPathScanningCandidateComponentProvider 中进行分析,接下来的处理过程不复杂,获取相关属性进行配置
第 7 步创建代理对象,和 AOP 相关,感兴趣的可自行查看
ClassPathScanningCandidateComponentProvider
org.springframework.context.annotation.ClassPathScanningCandidateComponentProvider,classpath 下扫描符合条件的 BeanDefinition
构造函数
public class ClassPathScanningCandidateComponentProvider implements EnvironmentCapable, ResourceLoaderAware { static final String DEFAULT_RESOURCE_PATTERN = "**/*.class";
private String resourcePattern = DEFAULT_RESOURCE_PATTERN;
/** 包含过滤器 */
private final List<TypeFilter> includeFilters = new LinkedList<>();
/** 排除过滤器 */
private final List<TypeFilter> excludeFilters = new LinkedList<>();
@Nullable
private Environment environment;
/** {@link Condition} 注解计算器 */
@Nullable
private ConditionEvaluator conditionEvaluator;
/** 资源加载器,默认 PathMatchingResourcePatternResolver */
@Nullable
private ResourcePatternResolver resourcePatternResolver;
/** MetadataReader 工厂 */
@Nullable
private MetadataReaderFactory metadataReaderFactory;
/** 所有 `META-INF/spring.components` 文件的内容 */
@Nullable
private CandidateComponentsIndex componentsIndex;
protected ClassPathScanningCandidateComponentProvider() {
}
public ClassPathScanningCandidateComponentProvider(boolean useDefaultFilters) {
this(useDefaultFilters, new StandardEnvironment());
}
public ClassPathScanningCandidateComponentProvider(boolean useDefaultFilters, Environment environment) {
if (useDefaultFilters) {
registerDefaultFilters();
}
setEnvironment(environment);
setResourceLoader(null);
}
@Override
public void setResourceLoader(@Nullable ResourceLoader resourceLoader) {
this.resourcePatternResolver = ResourcePatternUtils.getResourcePatternResolver(resourceLoader);
this.metadataReaderFactory = new CachingMetadataReaderFactory(resourceLoader);
// 获取所有 `META-INF/spring.components` 文件中的内容
this.componentsIndex = CandidateComponentsIndexLoader.loadIndex(this.resourcePatternResolver.getClassLoader());
}
}
构造函数在上一小节的 ClassPathBeanDefinitionScanner 的构造函数中都已经讲过了
我们来看到 componentsIndex 属性,调用 CandidateComponentsIndexLoader#loadIndex(@Nullable ClassLoader classLoader) 方法生成的
CandidateComponentsIndexLoader
org.springframework.context.index.CandidateComponentsIndexLoader,CandidateComponentsIndexLoader 的加载器,代码如下:
public final class CandidateComponentsIndexLoader { public static final String COMPONENTS_RESOURCE_LOCATION = "META-INF/spring.components";
public static final String IGNORE_INDEX = "spring.index.ignore";
private static final boolean shouldIgnoreIndex = SpringProperties.getFlag(IGNORE_INDEX);
private static final Log logger = LogFactory.getLog(CandidateComponentsIndexLoader.class);
/** CandidateComponentsIndex 的缓存,与 ClassLoader 对应 */
private static final ConcurrentMap<ClassLoader, CandidateComponentsIndex> cache = new ConcurrentReferenceHashMap<>();
private CandidateComponentsIndexLoader() {
}
@Nullable
public static CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader) {
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = CandidateComponentsIndexLoader.class.getClassLoader();
}
// 获取所有 `META-INF/spring.components` 文件中的内容
return cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex);
}
@Nullable
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
// 是否忽略 Index 的提升,通过配置 `spring.index.ignore` 变量,默认为 `false`
if (shouldIgnoreIndex) {
return null;
}
try {
// 获取所有的 `META-INF/spring.components` 文件
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
if (!urls.hasMoreElements()) {
return null;
}
// 加载所有 `META-INF/spring.components` 文件的内容
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + result.size() + "] index(es)");
}
// 总共配置多少个 component 组件
int totalCount = result.stream().mapToInt(Properties::size).sum();
// 如果配置了 component 组件,则封装成 CandidateComponentsIndex 对象并返回
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
}
catch (IOException ex) {
throw new IllegalStateException("Unable to load indexes from location [" +
COMPONENTS_RESOURCE_LOCATION + "]", ex);
}
}
}
CandidateComponentsIndexLoader 被 final 修饰,也不允许实例化,提供 loadIndex(@Nullable ClassLoader classLoader) 静态方法,获取所有 META-INF/spring.components 文件中的内容,存在文件并包含内容则创建对应的 CandidateComponentsIndex 对象
整过过程不复杂,如下:
- 根据
spring.index.ignore变量判断是否需要忽略本次加载过程,默认为false - 获取所有的
META-INF/spring.components文件 - 加载出所有
META-INF/spring.components文件的内容,并生成多个 key-value - 内容不为空则创建对应的 CandidateComponentsIndex 对象返回
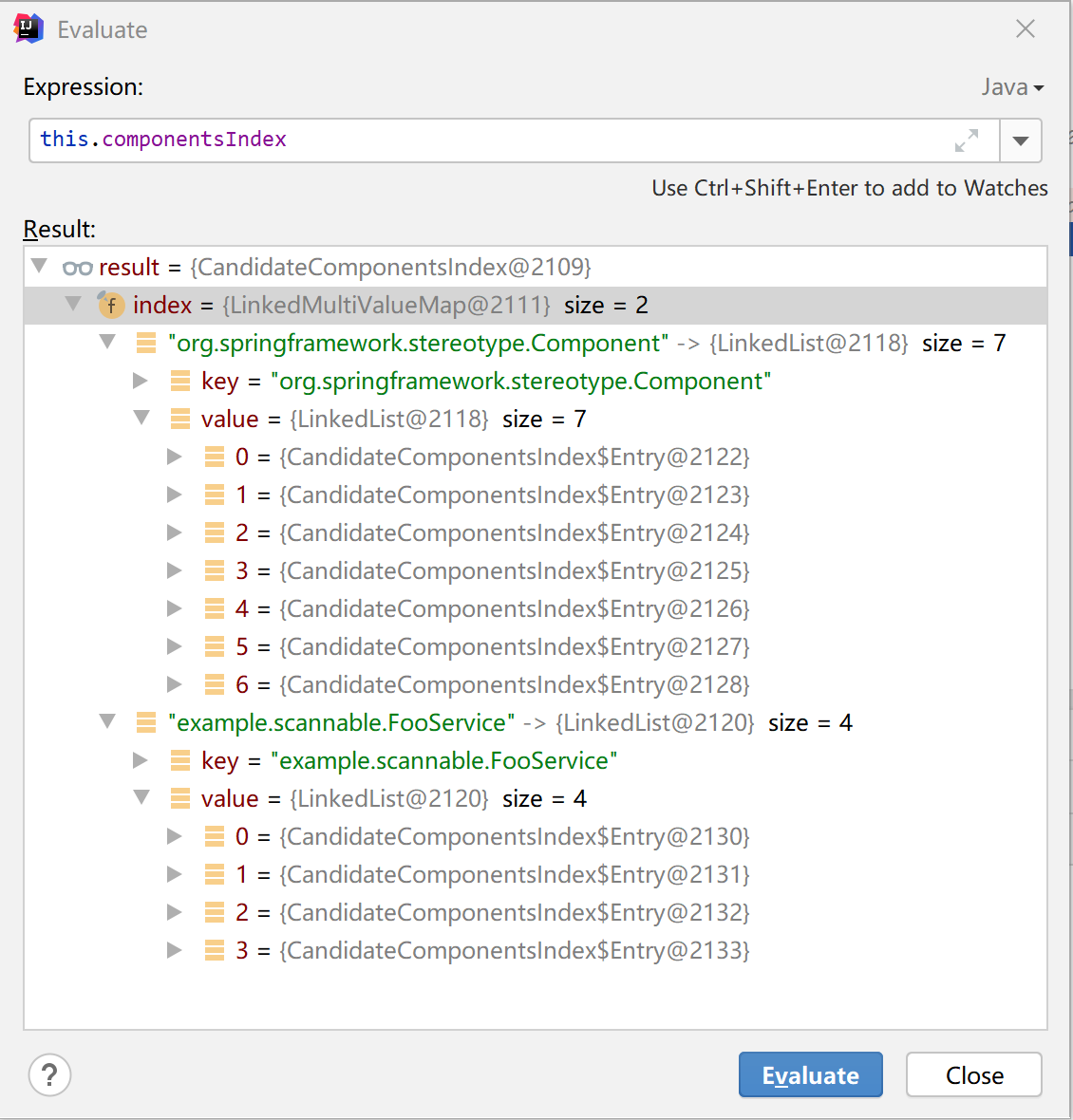
例如 META-INF/spring.components 文件这样配置:
example.scannable.AutowiredQualifierFooService=example.scannable.FooServiceexample.scannable.DefaultNamedComponent=org.springframework.stereotype.Component
example.scannable.NamedComponent=org.springframework.stereotype.Component
example.scannable.FooService=example.scannable.FooService
example.scannable.FooServiceImpl=org.springframework.stereotype.Component,example.scannable.FooService
example.scannable.ScopedProxyTestBean=example.scannable.FooService
example.scannable.StubFooDao=org.springframework.stereotype.Component
example.scannable.NamedStubDao=org.springframework.stereotype.Component
example.scannable.ServiceInvocationCounter=org.springframework.stereotype.Component
example.scannable.sub.BarComponent=org.springframework.stereotype.Component
生成的 CandidateComponentsIndex 对象如下所示:
3. findCandidateComponents 方法
findCandidateComponents(String basePackage) 方法,解析出包路径下所有符合条件的 BeanDefinition,方法如下:
public Set<BeanDefinition> findCandidateComponents(String basePackage) { /*
* 2. 扫描包路径,通过 ASM(Java 字节码的操作和分析框架)解析出符合条件的 AnnotatedGenericBeanDefinition 们,并返回
* 说明:
* 针对 `1` 解析过程中去扫描指定路径下的 .class 文件的性能问题,从 Spring 5.0 开始新增了一个 @Indexed 注解(新特性),
* @Component 注解上面就添加了 @Indexed 注解
*
* 这里不会去扫描指定路径下的 .class 文件,而是读取所有 `META-INF/spring.components` 文件中符合条件的类名,
* 直接添加 .class 后缀就是编译文件,而不要去扫描
*
* 没在哪看见这样使用过,可以参考 ClassPathScanningCandidateComponentProviderTest#customAnnotationTypeIncludeFilterWithIndex 测试方法
*/
if (this.componentsIndex != null // `componentsIndex` 不为空,存在 `META-INF/spring.components` 文件并且解析出数据则会创建
&& indexSupportsIncludeFilters()) // `includeFilter` 过滤器的元素(注解或类)必须标注 @Indexed 注解
{
return addCandidateComponentsFromIndex(this.componentsIndex, basePackage);
}
else {
/*
* 1. 扫描包路径,通过 ASM(Java 字节码的操作和分析框架)解析出符合条件的 ScannedGenericBeanDefinition 们,并返回
* 首先需要去扫描指定路径下所有的 .class 文件,该过程对于性能有不少的损耗
* 然后通过 ASM 根据 .class 文件可以获取到这个类的所有元信息,也就可以解析出对应的 BeanDefinition 对象
*/
return scanCandidateComponents(basePackage);
}
}
这个方法的实现有两种方式,都是基于 ASM(Java 字节码的操作和分析框架)实现的,默认情况下都是第 1 种,分别如下:
1,调用scanCandidateComponents(String basePackage)方法,默认扫描包路径,通过 ASM(Java 字节码的操作和分析框架)解析出符合条件的 ScannedGenericBeanDefinition 们,并返回。首先需要去扫描指定路径下所有的 .class 文件,该过程对于性能有不少的损耗;然后通过 ASM 根据 .class 文件可以获取到这个类的所有元信息,也就可以解析出对应的 BeanDefinition 对象
2,componentsIndex不为空,也就是说是通过META-INF/spring.components文件配置的 Bean,并且定义 Bean 的注解必须标注@Index注解,则调用addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage)方法进行解析扫描包路径,通过 ASM(Java 字节码的操作和分析框架)解析出符合条件的 AnnotatedGenericBeanDefinition 们,并返回。针对
1解析过程中去扫描指定路径下的 .class 文件的性能问题,从 Spring 5.0 开始新增了一个@Index注解(新特性),@Component 注解上面就添加了 @Index 注解;这里不会去扫描指定路径下的 .class 文件,而是读取所有META-INF/spring.components文件中符合条件的类名,直接添加 .class 后缀就是编译文件,而不要去扫描,提高性能。
ASM 是一个 Java 字节码操控框架。它能被用来动态生成类或者增强既有类的功能。ASM 可以直接产生二进制 class 文件,也可以在类被加载入 Java 虚拟机之前动态改变类行为。Java Class 被存储在严格格式定义的 .class 文件里,这些类文件拥有足够的元数据来解析类中的所有元素:类名称、方法、属性以及 Java 字节码(指令)。ASM 从类文件中读入信息后,能够改变类行为,分析类信息,甚至能够根据用户要求生成新类。
Spring 在很多地方都使用到了 ASM
4. scanCandidateComponents 方法
scanCandidateComponents(String basePackage) 方法,解析出包路径下所有符合条件的 BeanDefinition,方法如下:
private Set<BeanDefinition> scanCandidateComponents(String basePackage) { // <1> 定义 `candidates` 用于保存符合条件的 BeanDefinition
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
// <2> 根据包名生成一个扫描的路径,例如 `classpath*:包路径/**/*.class`
String packageSearchPath = ResourcePatternResolver.CLASSPATH_ALL_URL_PREFIX +
resolveBasePackage(basePackage) + '/' + this.resourcePattern;
// <3> 扫描到包路径下所有的 .class 文件
Resource[] resources = getResourcePatternResolver().getResources(packageSearchPath);
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// <4> 开始对第 `3` 步扫描到的所有 .class 文件(需可读)进行处理,符合条件的类名会解析出一个 ScannedGenericBeanDefinition
for (Resource resource : resources) {
if (resource.isReadable()) { // 文件资源可读
try {
// <4.1> 根据这个类名找到 `.class` 文件,通过 ASM(Java 字节码操作和分析框架)获取这个类的所有信息
// `metadataReader` 对象中包含 ClassMetadata 类元信息和 AnnotationMetadata 注解元信息
// 也就是说根据 `.class` 文件就获取到了这个类的元信息,而不是在 JVM 运行时通过 Class 对象进行操作,提高性能
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(resource);
// <4.2> 根据所有的过滤器判断这个类是否符合条件(例如必须标注 @Component 注解或其派生注解)
if (isCandidateComponent(metadataReader)) {
// <4.3> 如果符合条件,则创建一个 ScannedGenericBeanDefinition 对象
ScannedGenericBeanDefinition sbd = new ScannedGenericBeanDefinition(metadataReader);
// 来源和源对象都是这个 .class 文件资源
sbd.setResource(resource);
sbd.setSource(resource);
/*
* <4.4> 再次判断这个类是否符合条件(不是内部类并且是一个具体类)
* 具体类:不是接口也不是抽象类,如果是抽象类则需要带有 @Lookup 注解
*/
if (isCandidateComponent(sbd)) {
// <4.5> 符合条件,则添加至 `candidates` 集合
candidates.add(sbd);
}
}
} catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to read candidate component class: " + resource, ex);
}
}
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
// <5> 返回 `candidates` 集合
return candidates;
}
过程如下:
定义
candidates用于保存符合条件的 BeanDefinition根据包名生成一个扫描的路径,例如
classpath*:包路径/**/*.class扫描到包路径下所有的 .class 文件
开始对第
3步扫描到的所有 .class 文件(需可读)进行处理,符合条件的类名会解析出一个 ScannedGenericBeanDefinition- 根据这个类名找到
.class文件,通过 ASM(Java 字节码操作和分析框架)获取这个类的所有信息,生成metadataReader对象。这个对象其中包含 ClassMetadata 类元信息和 AnnotationMetadata 注解元信息,也就是说根据.class文件就获取到了这个类的元信息,而不是在 JVM 运行时通过 Class 对象进行操作,提高性能 - 根据所有的过滤器判断这个类是否符合条件(例如必须标注 @Component 注解或其派生注解)
- 如果符合条件,则创建一个 ScannedGenericBeanDefinition 对象,来源和源对象都是这个 .class 文件资源
- 再次判断这个类是否符合条件(不是内部类并且是一个具体类),具体类:不是接口也不是抽象类,如果是抽象类则需要带有 @Lookup 注解
- 符合条件,则添加至
candidates集合
- 根据这个类名找到
返回
candidates集合
关于 ASM 的实现本文不进行探讨,感兴趣的可自行研究
4. addCandidateComponentsFromIndex 方法
addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) 方法,根据 META-INF/spring.components 文件,获取带有 @Indexed 注解的类名,然后解析出符合条件的 BeanDefinition,方法如下:
private Set<BeanDefinition> addCandidateComponentsFromIndex(CandidateComponentsIndex index, String basePackage) { // <1> 定义 `candidates` 用于保存符合条件的 BeanDefinition
Set<BeanDefinition> candidates = new LinkedHashSet<>();
try {
Set<String> types = new HashSet<>();
// <2> 根据过滤器从所有 `META-INF/spring.components` 文件中获取所有符合条件的**类名称**
for (TypeFilter filter : this.includeFilters) {
// <2.1> 获取过滤注解(或类)的名称(例如 `org.springframework.stereotype.Component`)
String stereotype = extractStereotype(filter);
if (stereotype == null) {
throw new IllegalArgumentException("Failed to extract stereotype from " + filter);
}
// <2.2> 获取注解(或类)对应的条目,并过滤出 `basePackage` 包名下的条目(类的名称)
types.addAll(index.getCandidateTypes(basePackage, stereotype));
}
boolean traceEnabled = logger.isTraceEnabled();
boolean debugEnabled = logger.isDebugEnabled();
// <3> 开始对第 `2` 步过滤出来类名进行处理,符合条件的类名会解析出一个 AnnotatedGenericBeanDefinition
for (String type : types) {
// <3.1> 根据这个类名找到 `.class` 文件,通过 ASM(Java 字节码操作和分析框架)获取这个类的所有信息
// `metadataReader` 对象中包含 ClassMetadata 类元信息和 AnnotationMetadata 注解元信息
// 也就是说根据 `.class` 文件就获取到了这个类的元信息,而不是在 JVM 运行时通过 Class 对象进行操作,提高性能
MetadataReader metadataReader = getMetadataReaderFactory().getMetadataReader(type);
// <3.2> 根据所有的过滤器判断这个类是否符合条件(例如必须标注 @Component 注解或其派生注解)
if (isCandidateComponent(metadataReader)) {
// <3.3> 如果符合条件,则创建一个 AnnotatedGenericBeanDefinition 对象
AnnotatedGenericBeanDefinition sbd = new AnnotatedGenericBeanDefinition(
metadataReader.getAnnotationMetadata());
/*
* <3.4> 再次判断这个类是否符合条件(不是内部类并且是一个具体类)
* 具体类:不是接口也不是抽象类,如果是抽象类则需要带有 @Lookup 注解
*/
if (isCandidateComponent(sbd)) {
// <3.5> 符合条件,则添加至 `candidates` 集合
candidates.add(sbd);
}
}
}
} catch (IOException ex) {
throw new BeanDefinitionStoreException("I/O failure during classpath scanning", ex);
}
// <4> 返回 `candidates` 集合
return candidates;
}
过程如下:
定义
candidates用于保存符合条件的 BeanDefinition根据过滤器从所有
META-INF/spring.components文件中获取所有符合条件的类名称- 获取过滤注解(或类)的名称(例如
org.springframework.stereotype.Component) - 获取注解(或类)对应的条目,并过滤出
basePackage包名下的条目(类的名称)
- 获取过滤注解(或类)的名称(例如
开始对第
2步过滤出来类名进行处理,符合条件的类名会解析出一个 AnnotatedGenericBeanDefinition- 根据这个类名找到
.class文件,通过 ASM(Java 字节码操作和分析框架)获取这个类的所有信息,生成metadataReader对象。这个对象其中包含 ClassMetadata 类元信息和 AnnotationMetadata 注解元信息,也就是说根据.class文件就获取到了这个类的元信息,而不是在 JVM 运行时通过 Class 对象进行操作,提高性能 - 根据所有的过滤器判断这个类是否符合条件(例如必须标注 @Component 注解或其派生注解)
- 如果符合条件,则创建一个 AnnotatedGenericBeanDefinition 对象
- 再次判断这个类是否符合条件(不是内部类并且是一个具体类),具体类:不是接口也不是抽象类,如果是抽象类则需要带有 @Lookup 注解
- 符合条件,则添加至
candidates集合
- 根据这个类名找到
返回
candidates集合
该过程不会去扫描到所有的 .class 文件,而是从 META-INF/spring.components 文件中读取,知道了类名称也就知道了 .class 文件的路径,然后可以通过 ASM 进行操作了。Spring 5.0 开始新增的一个 @Indexed 注解(新特性),目的为了提高性能。
总结
本文面向注解(@Component 注解或其派生注解)定义的 Bean,Spring 是如何将他们解析成 BeanDefinition(Bean 的“前身”)并注册的,大致过程如下:
- ClassPathBeanDefinitionScanner 会去扫描到包路径下所有的 .class 文件
- 通过 ASM(Java 字节码操作和分析框架)获取 .class 对应类的所有元信息
- 根据元信息判断是否符合条件(带有
@Component 注解或其派生注解),符合条件则根据这个类的元信息生成一个 BeanDefinition 进行注册
关于上面的第 1 步性能损耗不少,Spring 5.0 开始新增的一个 @Indexed 注解(新特性),@Indexed 派生注解(例如 @Component)或 @Indexed 注解的类可以定义在 META-INF/spring.components 文件中,Spring 会直接从文件中读取,找到符合条件的类名称,也就找到了 .class 文件。这样一来对于上面第 1 步来说在性能上得到了提升,目前还没见到这种方式,毕竟 还要再文件中定义类名,感觉太复杂了,启动过程慢就慢点????
到这里,对于通过 面向资源(XML、Properties)、面向注解 两种定义 Bean 的方式,Spring 将定义的信息转换成 BeanDefinition(Bean 的“前身”)的过程差不多都分析了。我们接下来研究一下 Bean 的生命周期,BeanDefinition 是如何变成 Bean 的。
本文你是否还有疑惑,@Bean 注解定义的 Bean 怎么没有解析成 BeanDefinition 呢?别急,在后续的文章会进行分析
本文内容总结:BeanDefinition 的解析过程(面向注解),类图,ClassPathBeanDefinitionScanner,ClassPathScanningCandidateComponentProvider,总结,
原文链接:https://www.cnblogs.com/lifullmoon/p/14451788.html
以上是 死磕Spring之IoC篇 - BeanDefinition 的解析过程(面向注解) 的全部内容, 来源链接: utcz.com/z/296415.html