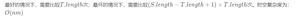【正则表达式教程】零长度匹配
正则表达式匹配" title="正则表达式匹配">正则表达式匹配">零长度正则表达式匹配
我们看到锚点,单词边界和Lookaround 是在某个位置进行匹配,而不是匹配某个字符。这意味着当正则表达式仅由一个或多个锚点,单词边界或Lookaround组成时,可能会导致长度为零的匹配。实际情况中,这可能是我们所乐见的。
如果使用^\d*$来测试用户是否输入数字,那么产生的结果可能不是我们想要的结果。如果我们输入一个空字符串,该正则表达式也认为是有效的输入。让我们看看为什么。
空字符串中只有一个“character”位置:字符串后的空白。正则表达式中的第一个标记是^。它与字符串后的void的前一个位置匹配。下一个标记是\d*。星号使得\d成为可选的。正则表达式引擎尝试将\d与字符串后的空白匹配。那失败了。但是,由于星号*的作用,对于\d这次匹配失败引擎是无所谓的。引擎继续下一个正则表达式令牌,但是不会移动字符串中的位置。因此,引擎到达$ ,并且字符串之后为void。这能匹配。此时,整个正则表达式已匹配空字符串,并且引擎报告成功。
解决方案是使用适当的量词,正则表达式^\d+$可以满足要求,至少输入一位数字。如果我们能确保我们的正则表达式不会有零长度匹配,当然除了特殊的情况,如:匹配每行的开头或结尾。那么我们对于下面的内容我们就可以免掉了。也省的我们头疼。
跳过零长度匹配
并非所有正则都支持零长度匹配。Delphi XE5和更低版本中的TRegEx类始终跳过零长度匹配。TPerlRegEx在XE5和更低版本中也默认情况下也可以,但是允许我们通过State属性来更改它。在Delphi XE6和更高版本中,TRegEx永远不会跳过零长度匹配,而TPerlRegEx默认情况下不会跳过零长度匹配,但仍允许我们通过设置State属性来跳过它们。默认情况下,PCRE查找零长度匹配项,但如果设置了PCRE_NOTEMPTY,则可以跳过它们。
在进行零长度匹配后前进字符串中的位置
如果正则表达式可以在字符串的任何位置找到零长度匹配项,那么它都会匹配。正则表达式\d*匹配零个或多个数字。如果目标字符串不包含任何数字,则此正则表达式会在字符串的每个位置找到一个零长度的匹配项。它在字符串abc找到4个匹配项,在三个字母中的每个字母之前找到一个,在字符串的末尾找到一个。
当正则表达式可以在任何位置找到零长度匹配以及某些非零长度匹配时,事情就变得比较麻烦了。假设我们有正则表达式\d*|x和目标字符串x1,并且我们选的这个正则表达式引擎允许零长度匹配。遍历所有匹配项时,我们会获得哪些匹配项和多少个匹配项?答案取决于零长度匹配后正则表达式引擎如何前进。无论哪种方式,都是很麻烦的。
首次匹配尝试是在字符串的开头。\d不能匹配x 。但是*使\d为可选,所以没匹配成功也没关系。第一种选择是在字符串的开头找到零长度的匹配项。直到这里,所有允许零长度匹配的正则表达式引擎都执行相同的操作。
现在,正则表达式引擎才开始认识到事情真的比较麻烦。我们要求它遍历整个字符串以查找所有不重叠的正则表达式匹配项。第一个匹配项在字符串的开头(第一个匹配项尝试开始)处结束。正则表达式引擎需要一种避免陷入无限循环的方法,该循环永远在字符串的开头找到相同的零长度匹配。
大多数正则表达式引擎使用的最简单的解决方案是,如果前一次匹配的长度为零,则在上一次匹配结束后的字符的后面位置开始下一次匹配尝试。在这种情况下,第二次匹配尝试从字符串中x和1之间的位置开始。\d匹配1 。到达字符串的末尾。量词*满足一次重复。返回1作为整体匹配。
Perl使用的另一种解决方案是始终在上一次匹配结束时开始下一次匹配尝试,无论它是否为零长度。如果它是零长度,则引擎会注意到这一点,因为它不允许在同一位置进行零长度匹配。因此,Perl也在字符串的开头开始第二次匹配尝试。第一种选择再次找到零长度匹配。但这不是有效的匹配项,因此引擎会通过正则表达式回溯。\d*被迫放弃其零长度匹配。现在尝试使用正则表达式中的第二个选择项。x匹配x ,找到第二个匹配项。第三次匹配尝试从字符串中x后面的位置开始。找到第一个备选匹配项1和第三个匹配项。
但是正则表达式引擎尚未完成。匹配x之后,它会从字符串的末尾开始再进行一次匹配尝试。在这里\d*也会找到零长度的匹配项。因此,根据零长度匹配后引擎的前进方式,它会找到三到四个匹配项。
一个例外是JGsoft引擎。就像大多数引擎一样,JGsoft引擎在零长度匹配之后前进一个字符。但是,它还有一个额外的规则,即在上一个匹配结束的位置跳过零长度匹配,因此我们永远都不能在进行了一个非零长度的匹配之后进行零长度匹配。在我们的示例中,JGsoft引擎仅找到两个匹配项:字符串开头的零长度匹配项和1 。
PCRE 8.00和更高版本以及PCRE2通过回溯处理零长度匹配(如Perl)。它们不再像过去的PCRE 7.9那样在零长度匹配之后前进一个字符。
R和PHP中的regexp函数也是基于PCRE的,因此它们避免了像PCRE这样的回溯而陷入零长度匹配。但是,在R中进行搜索和替换的gsub()函数也会在先前的非零长度匹配结束的位置跳过零长度匹配,就像Python 3.6和先前版本中的gsub()一样。R中的其他正则表达式函数以及PHP中的所有函数都允许零长度匹配与非零长度匹配直接相邻,就像PCRE本身一样。
程序员注意
正则表达式(例如$ )本身可以在字符串末尾找到零长度的匹配项。如果要查询引擎的字符位置,则在编程语言中,如果字符串索引是从零开始的,它将返回字符串的长度;如果字符串索引是从1开始的,则它将返回字符串的长度+1。如果我们向引擎查询匹配的长度,它将返回零。
需要注意的是String [Regex.MatchPosition]可能会导致访问冲突或分段错误,因为MatchPosition可以指向字符串后的空白。如果字符串中的最后一个字符是换行符,则在多行模式下使用^和^$也可能发生这种情况。
本文转载自:迹忆客(https://www.jiyik.com)
以上是 【正则表达式教程】零长度匹配 的全部内容, 来源链接: utcz.com/z/290354.html
![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)