Memcached中的分布式思想
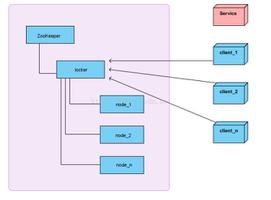
Memcached号称是高性能的分布式缓存系统。说到分布式,Memcached是值得我们来分析分析的。它的分布式机制和一般的分布式服务系统是不同的,分布式服务系统各节点之间是有通信的,目的是为了保证数据的一致性。但是对于Memcached来说,各个节点之间是没有通信的,也就是说Memcached的集群是一组单点服务,各节点之间是不通信的。而其所有的和分布式有关的地方都是在客户端实现的。关于这一点在Memcached的github一篇文章中《A Story of Caching》是有体现的,有兴趣的可以去看一看这篇文章,通过这篇文章可以对Memcached有一个清晰的认识。
下面我们先通过一个案例来验证一下我们上面的说法。
例一
有两台Memcached服务。我们使用php来向Memcached中添加数据。
代码一
$MEMCACHE_SERVERS = array("192.168.5.111", //memcached1
"192.168.5.102" //memcached2
);
$memcache = new Memcache();
foreach($MEMCACHE_SERVERS as $server){
$memcache->addServer ( $server ); //将两个台服务器地址都添加进连接池
}
$memcache->set("onmpw", 5);
$memcache->set("jiyi", 4);
上面php代码执行以后,按照分布式系统原理来说应该两台服务器中都有key为onmpw和jiyi的数据,但是事实是这样吗,我们可以分别登录到两台服务上进行查看。
Connect 5.111# telnet 192.168.5.111 11211
Trying 192.168.5.111...
Connected to 192.168.5.111 (192.168.5.111).
Escape character is '^]'.
get jiyi
VALUE jiyi 768 1
4
END
get onmpw //在5.111上并没有onmpw这条数据
END
Connect 5.102
Trying 192.168.5.102...
Connected to 192.168.5.102 (192.168.5.102).
Escape character is '^]'.
get onmpw
VALUE onmpw 768 1
5
END
get jiyi //在5.102上同样是没有jiyi这条数据
END
由此可见在Memcached的服务端并不去同步集群中的数据。
那数据又是怎么将不同的键值对分发到不同的节点上去的呢,这就是客户端所要实现的分布式了。在这里会涉及到一种算法——hash算法。这里面涉及到两种hash算法:一种是取余数计算分散,一种是一致性hash算法(Consistent Hashing)。一致性hash算法在 Consistent Hashing算法入门及php实现 这篇文章中有比较系统的表述。而对于取余数方式的表述却有欠详细,所以在这里对此做一个稍详细的表述,以弥补那篇文章的不足。
一般的hash算法——根据余数计算分散
首先是根据集群服务的节点数创建一个哈希表,然后根据键名计算出键名的整数哈希值,用该哈希值对节点数取余,最后根据余数在哈希表中取出节点。
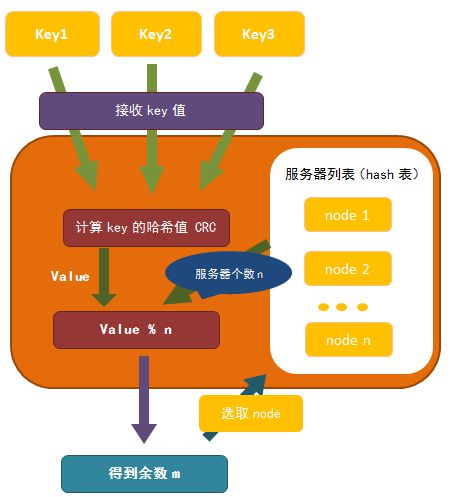
其中在计算key的哈希值的时候使用的是CRC(循环冗余校验)。下面使用php简化的代码来进行说明
代码二
$nodes = array('node1','node2','node3'); //nodes代表服务器节点$keys = array('onmpw', 'jiyi', 'onmpw_key', 'jiyi_key', 'www','www_key'); //这是key值
foreach( $keys as $key) {
$crc = crc32($key); // CRC値
$mod = $crc % ( count($nodes) );
$server = $nodes[ $mod ]; // 根据余数选择服务器
printf("%s => %s\n", $key, $server);
}
首先求得key的crc值,然后和node的个数取余数。上面代码的执行结果如下
onmpw => node2
jiyi => node2
onmpw_key => node1
jiyi_key => node2
www => node1
www_key => node3
根据上面的结果,我们看到onmpw、jiyi和jiyi_key分散到node2,onmpw_key和www分散到node1,www分散到node3。
php客户端分布式实现
在php实现的Memcache的客户端是支持余数分散这种算法的。下面我们来看一下其源码中涉及该算法的部分。这里使用的php-memcache版本为memcache-3.0.6
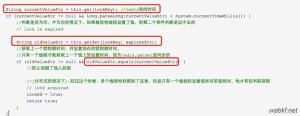
mmc_t *mmc_standard_find_server(void *s, const char *key, unsigned int key_len TSRMLS_DC) {mmc_standard_state_t *state = s;
if (state->num_servers > 1) {
/* "new-style" hash */
//计算key值的哈希值
unsigned int hash = (mmc_hash(state->hash, key, key_len) >> 16) & 0x7fff;
//用得到的哈希值对节点数取余
return state->buckets[(hash ? hash : 1) % state->num_buckets];
}
return state->buckets[0];
}
我们看到,计算hash值的方式是使用mmc_hash()函数得到一个值,然后将该值向右移动16位,最后再和0x7fff做‘与’运算。
这里我们在看mmc_hash()是如何计算key的值的。
#define mmc_hash(hash, key, key_len) ((hash)->finish((hash)->combine((hash)->init(), (key), (key_len))))
太坑了,这算神马函数?各位先不要着急,这里无非是一个宏定义,可以简单的认为mmc_hash(hash, key, key_len)其实就是一个值,这个值是什么呢?是由((hash)->finish((hash)->combine((hash)->init(), (key), (key_len))))来得到的。其实主要的部分还是finish()、combine()和init()函数。我们来看这三个函数的实现。
上面三个函数由以下结构体定义
typedef struct mmc_hash_function {mmc_hash_function_init init;
mmc_hash_function_combine combine;
mmc_hash_function_finish finish;
} mmc_hash_function_t;
同时对于mmc_hash_function_t做了如下的映射
extern mmc_hash_function_t mmc_hash_crc32;
也就是说这些函数的实现是在mmc_hash_crc32中实现的。继续追寻,发现下面的代码
mmc_hash_function_t mmc_hash_crc32 = {mmc_hash_crc32_init,
mmc_hash_crc32_combine,
mmc_hash_crc32_finish
};
追根寻底,其实init()、combine()和finish()函数分别对应mmc_hash_crc32_init()、mmc_hash_crc32_combine()和mmc_hash_crc32_finish()。下面看这些函数的实现
static unsigned int mmc_hash_crc32_init() { return ~0; }static unsigned int mmc_hash_crc32_finish(unsigned int seed) { return ~seed; }
static unsigned int mmc_hash_crc32_combine(unsigned int seed, const void *key, unsigned int key_len)
{
const char *p = (const char *)key, *end = p + key_len;
while (p < end) {
CRC32(seed, *(p++));
}
return seed;
}
在上面的代码中我们是不是看到了熟悉的身影。底层的实现也是用的crc32函数(该函数在php源码的ext/standard/crc32.h中有定义,有兴趣的可以去研究一下)。顺便多说一句,在mmc_hash_crc32_init()函数中返回的值是~0,它的值为-1。而’~’表示是按位取反。在定义函数的返回值的类型时是unsigned(无符号)的。所以-1的二进制表示为11111111111111111111111111111111(总共32位)。
我们看到,使用余数计算的实现方法很简单,而且其数据也是比较分散的。但是这种方式也是有很大的缺陷的,当我们需要横向扩展节点的时候,缓存重组的代价也是非常大的。下面我们修改代码二,在nodes中添加node4。
代码三
$nodes = array('node1','node2','node3','node4'); //nodes代表服务器节点$keys = array('onmpw', 'jiyi', 'onmpw_key', 'jiyi_key', 'www','www_key'); //这是key值
foreach( $keys as $key) {
$crc = crc32($key); // CRC値
$mod = $crc % ( count($nodes) );
$server = $nodes[ $mod ]; // 根据余数选择服务器
printf("%s => %s\n", $key, $server);
}
再次运行代码发现其结果如下
onmpw => node4
jiyi => node4
onmpw_key => node3
jiyi_key => node3
www => node2
www_key => node3
我们看上面的结果,发现只有www_key命中了。像这种情况在添加节点的时候命中率降低,当添加Memcached服务器的时候缓存效率会瞬间降低,这时候负载会集中到数据库的服务器上面,从而有可能导致数据库由于瞬间压力过大而无法提供正常的服务。
所以说,还需要一种新的方式来解决集群横向扩展的问题。因此随着该问题的出现,新的分布式方法也诞生了——一致性Hash算法(Consistent Hashing)。
Consistent Hashing
一致性hash算法和一般的hash算法一样,都是对集群中的节点建立一个字典。因为该算法在Consistent Hashing算法入门及php实现 这篇文章中有详细的描述,并且有简单的php代码的实现,所以本章不再对Consistent Hashing有过多的赘述。
和一般的hash算法不同的是该方式相对来说在有节点添加或减少的时候能最大限度的减少数据的移动。也就是说命中率会有相当大的提高。那它是怎么来实现的呢?
首先求出memcached服务器(节点)的哈希值, 并将其配置到0~1的圆上。 然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。 如果超过1仍然找不到服务器,就会保存到第一台memcached服务器上。
具体在PHP-Memcache客户端中的实现代码的核心部分如下
void mmc_consistent_add_server(void *s, mmc_t *mmc, unsigned int weight){
mmc_consistent_state_t *state = s;
int i, key_len, points = weight * MMC_CONSISTENT_POINTS;
unsigned int seed = state->hash->init(), hash;
/* buffer for "host:port-i\0" */
char *key = emalloc(strlen(mmc->host) + MAX_LENGTH_OF_LONG * 2 + 3);
key_len = sprintf(key, "%s:%d-", mmc->host, mmc->tcp.port);
seed = state->hash->combine(seed, key, key_len);
/* add weight * MMC_CONSISTENT_POINTS number of points for this server */
/* 申请保存所有节点及其各自的虚拟节点的空间 */
state->points = erealloc(state->points, sizeof(*state->points) * (state->num_points + points));
for (i=0; i<points; i++) {
key_len = sprintf(key, "%d", i);
// 对每个节点及虚拟节点计算hash值
hash = state->hash->finish(state->hash->combine(seed, key, key_len));
// 保存个虚拟节点的hash值和该节点的信息
state->points[state->num_points + i].server = mmc;
state->points[state->num_points + i].point = hash;
}
state->num_points += points;
state->num_servers++;
state->buckets_populated = 0;
efree(key);
}
上面的代码是对服务节点的分散,使每个节点及其各自的虚拟节点随机的均匀分布在圆上。
mmc_t *mmc_consistent_find_server(void *s, const char *key, unsigned int key_len TSRMLS_DC){
mmc_consistent_state_t *state = s;
if (state->num_servers > 1) {
unsigned int hash;
if (!state->buckets_populated) {
mmc_consistent_populate_buckets(state);
}
//计算key的hash值
hash = mmc_hash(state->hash, key, key_len);
return state->buckets[hash % MMC_CONSISTENT_BUCKETS];
}
//没有找到相应的服务节点,则返回第一个节点
return state->points[0].server;
}
这段核心代码是在存储一个键值对的时候根据该键值对的key去寻找要存储的服务节点。同样的,是对key值进行hash计算,然后根据计算出的hash值,该key肯定也会分布在圆的某个位置上,然后从该位置开始顺时针查找将要遇到的第一个服务节点。如果一直到末尾都没有遇到服务节点,则直接返回第一个服务节点。这也就是 return state->points[0].server的意义所在。
总结:以上两种方式都在PHP-Memcache客户端中已经实现。还是那句话,对于Memcached的分布式思想都是在客户端中体现的。不同的客户端实现的方式可能有所不同,但是相信基本思想都是一样的。 同时也欢迎大家能给出不同的意见。
本文转载自:迹忆客(https://www.jiyik.com)
以上是 Memcached中的分布式思想 的全部内容, 来源链接: utcz.com/z/290141.html