Java多线程学习笔记(六) 长乐未央篇
突然发现我多线程系列的题目快用光了: 初遇、相识、甚欢、久处不厌、长乐无极、长乐未央。算算自己多线程相关的文章有:
- 《当我们说起多线程与高并发时》
- 《Java多线程学习笔记(一) 初遇篇》
- 《Java多线程学习笔记(二) 相识篇》
- 《Java多线程学习笔记(三) 甚欢篇》
- 《Java多线程学习笔记(四) 久处不厌》
- 《Java多线程学习笔记(五) 长乐无极》
- 《 ThreadLocal学习笔记》
今天应该是多线程学习笔记的收官篇,到本篇JDK内多线程的基本概念,使用应该大致都过了一遍,其实仔细算算还有并发集合、并行流还没介绍。
并发集合我着重会放在其实现上,也就是上面文章介绍的一些基本类的原理,因为并发集合和普通集合使用起来没有多大区别,这也是下个系列的文章了,也就是源码系列的文章,去年十月份开了个头《当我们说起看源码时,我们是在看什么》,是时候该去填这个坑了,并行流还是放在Stream系列的文章中。这些文章目前大概都在掘金和思否,不大统一,有时间会将三个平台文章统一以下。如果你在公众号已经发现上面这些文章,那已经大致迁移完成了。
Fork Join模式简介
本篇的主角是ForkJoin,作者是Doug Lea的作品,在看ForkJoinPool的时候心血来潮想看一下其他并发类的作者,然后发现以下这些不包括未发现的
- CountDownLatch
- CyclicBarrier
- Semaphore
- ThreadPoolExecutor
- Future
- Callable
- ConcurrentHashMap
- CopyOnWriteArrayList
似乎JDK里面并发的类库就由这个老爷子一手打造,在我翻阅这位老爷子的作品的时候,还发现自己又漏掉的类:Phaser, 所以还会有一个拾遗篇,下一篇多线程的系列会将Phaser的补充回来。话说回来我们接着来介绍ForkJoin。在IDEA中用ForkJoin来全局搜索, 结果如下:
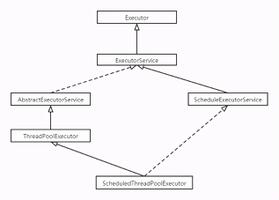
我们首先来看ForkJoinPool的继承类图:
我们这里可以看到ForkJoinPool和ThreadPoolExecutor在同一个级别,ThreadPoolExecutor是线程池,这个我们熟,所以我们可以推测一下ForkJoinPool是另一种类型的线程池。那这种ForkJoinPool和ThreadPoolExecutor有什么区别呢? 带着这个疑问,我们接着来看ForkJoinPool的注释, 注意由于ForkJoinPool和ThreadPoolExecutor都属于ExecutorService的子类,所以ForkJoinPool的注释不会说ThreadPoolExecutor是其他类型的线程池(Thread Pool, 而是说另一种形式的ExecutorService)。
An ExecutorService for running ForkJoinTasks. A ForkJoinPool provides the entry point for submissions from non-ForkJoinTask clients, as well as management and monitoring operations.
A ForkJoinPool differs from other kinds of ExecutorService mainly by virtue of employing work-stealing: all threads in the pool attempt to find and execute tasks submitted to the pool and/or created by other active tasks (eventually blocking waiting for work if none exist). This enables efficient processing when most tasks spawn other subtasks (as do most ForkJoinTasks), as well as when many small tasks are submitted to the pool from external clients. Especially when setting asyncMode to true in constructors, ForkJoinPools may also be appropriate for use with event-style tasks that are never joined. All worker threads are initialized with Thread.isDaemon set true.ForkJoinPool这个异步执行服务(或译为这个ExecutorService执行一些ForkJoinTasks)执行的是ForkJoinTask(Fork: 分叉、岔开两条分支, Join是合并),所以ForkJoinTask可以理解为分割合并任务,也能执行一些不属于这种类型的任务、管理监控操作。
ForkJoinPool主要不同于其他类型的ExecutorService的在于采取了工作-窃取算法: 该线程池中的所有线程都会尝试去寻找和执行被提交给该线程的任务和其他还未完成的任务(如果没有任务,所有的线程将会处于阻塞等待状态)。这种处理方式对于一些可以将大任务切割成子任务处理和和其他客户端向该线程池提交小任务的任务类型来说效率会很高(也就是ForkJoin任务),ForkJoinPool也可能比较适合于事件驱动型任务,这些任务永远不需要合并结果。所有的工作线程在初始化的时候会被设置为守护线程。
工作窃取算法简介
在介绍工作窃取算法之前,我们先来回忆ThreadPoolExecutor的工作模式, 客户端在向线程池提交任务的时候,线程池会首先判断当前的工作线程是否小于核心线程数,如果小于核心线程数,会继续向线程中添加工作线程,如果不小于核心线程数,则会将任务放置于任务队列中,如果队列已经满了,则判断当前的工作线程是否大于最大线程数,如果大于等于最大线程数,就会触发拒绝策略。
// ThreadPoolExecutor的execute方法 public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get(); //ctl可以简单的理解为线程的状态量
// workerCountOf 用于计算工作线程的数量
if (workerCountOf(c) < corePoolSize) {
// addWorker 用于的第二个参数用于指定添加的是否是核心线程
if (addWorker(command, true))
return;
c = ctl.get();
}
// 如果线程处于运行状态且向任务队列添加任务失败,则尝试添加非核心线程
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 添加失败则触发拒绝策略
else if (!addWorker(command, false))
reject(command);
}
在ThreadPoolExecutor中获得任务队列中的任务通过直接调用阻塞队列的poll和take方法来获取,但是为了避免多线程消费问题,阻塞队列在获取的时候是通过加锁来处理的:
public E poll(long timeout, TimeUnit unit) throws InterruptedException { long nanos = unit.toNanos(timeout);
// 我们的老朋友ReentrantLock
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0) {
if (nanos <= 0L)
return null;
nanos = notEmpty.awaitNanos(nanos);
}
return dequeue();
} finally {
lock.unlock();
}
}
如果可以的话,我们希望是线程在从任务队列中获取任务的时候的等待时间尽可能的短的,那我们就需要准备多个队列,为每个线程准备一个队列,这样一个消费者处理完自己队列的任务的时候可以从其他工作线程对应的队列“窃取”任务进行处理,这样就不会导致工作线程闲置,并能减轻其他消费者线程的负担。这也就是工作窃取算法的思想。那工作窃取算法就一点毛病都没有?如果是这样的话,ThreadPoolExecutor似乎在ForkJoinPool出来之后就应该早早的被打上@Deprecated。 到现在也没有,那么ForkJoinPool就必然有他的适应场景。应该不只是我一个人有这个疑问,我在StackOverFlow找到了我想要的答案:
- ThreadPoolExecutor vs ForkJoinPool: stealing subtasks
Assume that I have created ThreadPoolExecutor with 10 threads and 3000 Callable tasks have been submitted. How these threads share the load of execution of sub tasks?
And How ForkJoin pool behaves differently for same use case?
假设ThreadPoolExecutor有10个线程,向ThreadPoolExecutor提交了3000个任务,这些线程将怎样协同执行这些任务?
ForkJoinPool在同样的情况下有什么不同?
答案1:如果你向线程池提交了3000个任务,这些任务也不能再拆分成子任务,ForkJoinPool和ThreadPoolExecutor的行为没有什么明显不同: 10个线程一次执行10个任务,直到这些任务被执行完成。ForkJoinPool的适用场景为你有一些任务,但是这些任务可以分解为一些小任务。另一个回答也是从消费任务的时候造成线程饥饿的现象出发的。
我这里的体会是切割任务的粒度,当我们需要将一些计算任务并行化的时候,我们就会求助于线程池,转而向线程池中提交任务:
通常情况下我们希望任务的粒度尽可能的小,这样我们就可以提交给线程池的时候就可以加大并发粒度,假设一个任务可以明显是没有划分好粒度过大,而我们的线程池的核心线程是10个,提交给线程池的时候就只有这一个任务,那么线程池的工作线程就只有一个,又假设这个任务又可以被拆分成五个独立的子任务, 我们姑且命名为A、B、C、D、E、F。F的执行时间最长,那么该任务的最终时间可能就是A+B+C+D+E+F的执行时间,那如果我们将其切割成五个独立的子任务,那么该任务的最终执行时间就是最长的那个任务的执行时间。这种情况是开发者可以明确的知道任务的最小粒度,向ThreadPoolExecutor执行。但是有的时候对于某些任务我们可能无法手动切割粒度,我们希望让给一个粒度让程序按照此粒度去分割,然后去执行, 最后合并结果,这也就是ForkJoinPool的优势计算场景。
切割为任务为Fork:
合并任务结果为Join:
这就是所谓的ForkJoin是也,其实我们也可以只用Fork。跟这个有点类似的就是归并排序:
归并排序过程是不是有点类似于我们跟上面讲的ForkJoin很是相像? 我们接下来通过例子来感受一下ForkJoin模式。
然后用起来
ForkJoinPool有四个构造函数:
1. ForkJoinPool() 2. ForkJoinPool(int parallelism)
3.ForkJoinPool(int parallelism,ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler, boolean asyncMode)
4.ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, int mode, String workerNamePrefix)
5. ForkJoinPool(int parallelism, ForkJoinWorkerThreadFactory factory, UncaughtExceptionHandler handler, boolean asyncMode, int corePoolSize,
int maximumPoolSize,
int minimumRunnable,
Predicate<? super ForkJoinPool> saturate,
long keepAliveTime,
TimeUnit unit) // 自JDK9 引入
1.2.3 本质上都是调用4.我们重点来讲下4.
- parallelism 并行粒度, 也就是设置该线程池的线程数。
使用无参构造, 为Runtime.getRuntime().availableProcessors()的返回值,此方法返回的是逻辑核心而非物理核心。我的电脑是八核十六核心,所以得到的数字为16
- factory 线程工程, 在添加工作线程的时候调用此方法添加工作线程
- handler 异常处理者, 工作线程遇到了问题该如何处理。
- asyncMode 用于控制消费方式
if true, establishes local first-in-first-out scheduling mode for forked tasks that are never joined. This mode may be more appropriate than default locally stack-based mode in applications in which worker threads only process event-style asynchronous tasks. For default value, use false.
如果为真为Fork任务采取先进先出的调度方式,这些任何永远不会合并。这种调度模式更适合一些基于本地栈的应用,这些工作线程处理的是事件驱动的异步任务。默认为false。
- workerNamePrefix: 用于控制工作线程的名称
接下来我们来看怎么向ForkJoinPool提交任务,我们看到了一个新的参数类型: ForkJoinTask。我们先一个例子来介绍ForkJoin.
public class FibonacciForkJoinTask extends RecursiveTask<Integer> { private final int n;
public FibonacciForkJoinTask(int n) {
this.n = n;
}
@Override
protected Integer compute() {
if (n <= 1){
return n;
}
FibonacciForkJoinTask f1 = new FibonacciForkJoinTask(n - 1);
f1.fork(); // 分解f1
FibonacciForkJoinTask f2 = new FibonacciForkJoinTask(n - 2);
f2.fork(); // 分解f2
return f1.join() + f2.join(); // 合并f1和f2的计算结果
}
}
public class ForkJoinDemo01 {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> forkJoinTaskResult = forkJoinPool.submit(new FibonacciForkJoinTask(4));
System.out.println(forkJoinTaskResult.get());
}
}
ForkJoinTask及其子类概述
ForkJoinTask是提交给ForkJoinPool任务的基类,这是一个抽象类。RecursiveTask和RecursiveAction见名知义,用于递归切割任务粒度,区别在于RecursiveTask有返回值,RecursiveAction无返回值。RecursiveTask、RecursiveAction1.7推出,CountedCompleter有一个钩子函数 onCompletion(CountedCompleter<?> caller),所有任务完成会触发此方法。上面的用Fork/Join计算斐波那契数列只是为了演示用法,单线程跑的也很快,也有更快的算法。并行流默认使用的也是ForkJoinPool, 推荐使用commonPool来使用ForkJoinPool.
总结一下
我们对事物的认知是一个逐步清晰的过程,本篇就当作ForkJoin的入门文章吧,还努力的挣扎了一下想看懂调用fork方法做了什么,最后还是放弃了。不是所有的场景ForkJoin都能胜任,如果我们能比较好的控制任务粒度,那么其实ForkJoinPool和ThreadPoolExecutor的执行速度没有什么区别,你也可以只fork不Join。
参考资料
- 《Java多线程编程实战指南》第2版 黄文海著
- ThreadPoolExecutor vs ForkJoinPool: stealing subtasks https://stackoverflow.com/que...
- ForkJoin实际中应用 https://juejin.cn/post/698395...
- Stack-based 的虚拟机有什么常用的优化策略? -来自知乎
以上是 Java多线程学习笔记(六) 长乐未央篇 的全部内容, 来源链接: utcz.com/z/267428.html