CNN Features off-the-shelf: an Astounding Baseline for Recognition 解读
0 摘要
最近的结果表明,卷积神经网络提取的通用描述符非常强大。本文添加了许多证据,证明确实如此。我们针对不同识别任务进行了一系列实验,这些实验使用了OverFeat网络,经过训练后可以在 ILSVRC13 上进行图像分类。我们使用从 OverFeat 网络提取的特征作为通用图像表示来处理图像分类,场景识别,细粒度识别,属性检测和图像检索等多种识别任务。令人惊讶的是,与各种数据集上所有视觉分类任务中的最先进系统相比,我们得出了几乎一致的优异结果。结果表明,从卷积网深度学习获得的特征应该是大多数视觉识别任务的主要选择。
1 介绍
你认为深度学习解决计算机视觉的问题奏效吗?
这个问题很可能是在你们小组的咖啡厅里提出的。对此,有人用它取得了的成功,有人提出怀疑。你可能有点沮丧地想,“需要GPU编程技巧和大量的标记数据来训练我自己的网络,可惜我没有这个时间”。最新提出的OverFeat网络开源后,我们可以进行一些实验了。我们想知道,是否不需要专门为特定的任务训练一个深度网络,而是从一个已有的深度网络中提取特征(这个特征是在ImageNet数据集上仔细训练并用于图像分类)可以用于多种视觉任务。我们现在陈述我们的讨论和一些发现,因为作为计算机视觉研究人员,您可能有同样的问题
老师:首先有其他人调查过这个问题?
学生:ZFNet等认为通用特征可以从大型 CNN 中提取,它们提供了一些证据来支持这种说法。 但他们只考虑了少量的视觉识别任务。 更彻底地研究这些CNN特征有多强大是很有趣的。那么我们应该如何开始?
老师:我们可以尝试的最简单的方法是从 OverFeat 网络中提取图像特征向量,并将其与简单的线性分类器组合起来。 图像作为输入,特征向量是来自网络最后一层的响应。 你们认为的哪一个视觉任务可以有效地应用这个方法?
学生:当然是图像分类。许多视觉小组已经在 Pascal VOC 数据集上取得了重大突破,相比传统的方法提升了性能。微调网络对于提升性能是必要的吗?我将在Pascal VOC数据集上进行尝试,然后在MIT场景识别数据集上遇到一点困难。
解答:OverFeat 是一个很好的网络,甚至不需要经过微调。(3.2节叙述)
老师:OverFeat 特征可以很好地解决一些问题,这些问题恰好就是我们训练他们要达到的目的。
ImageNet 或多或少是 Pascal VOC 的父集。有没有 OverFeat 特征不能解决的问题呢?
学生:我知道的是关于细粒度的分类。 这里我们想区分一个类别的不同子类,比如不同种类的花。 你认为通用的OverFeat特性是否具有足够的代表性能力来提取非常相似的类之间潜在的细微差别?
解答:它在标准的鸟和花数据库上运行得非常好。 它最简单的形式并没有打败最新的表现最好的方法,但它是一个更加干净的解决方案,有很大的改进余地。
实际上,采用一组简单的数据增强技术(仍然与线性SVM结合)可以胜过性能最佳的方法。令人印象深刻!(3.4节叙述)
老师:下一个挑战属性检测? 让我们来看看OverFeat特征是否对人物和对象的语义属性进行了编码。
学生:你是否认为从人的边界框中提取的全局CNN特征可以处理H3D数据集中存在的遮挡? 所有最好的方法都是在分类和训练之前进行某种部件对齐。
解答:令人惊讶的是, 它们在对象属性数据集上也工作得非常好。 也许这些OverFeat特征确实可以编码属性信息?(3.5节叙述)
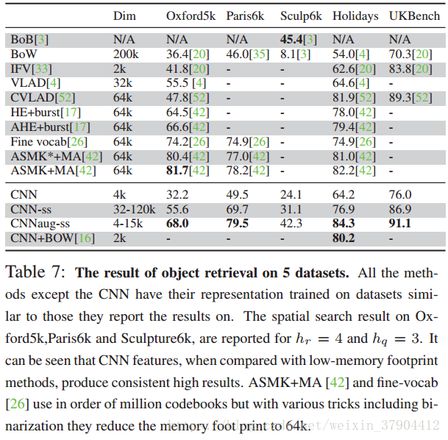
老师:我们可以进一步推动其他领域吗? 与更成熟的计算机视觉系统相比,OverFeat特征会有什么难以解决的问题吗? 也许是实例检索。 这项任务促使了SIFT和VLAD描述符的发展以及后来迅速采用的视觉词袋方法。 这些高度优化的特征向量和中等水平的特征是否会胜过通用特征?
学生:如果我们开始比较包含3D几何约束的方法,我不认为CNN特征会有机会。 让我们专注于描述符的表现吧。新派的描述符是否击败了旧派的描述符?
解答:非常正确。 忽略3D几何约束的系统,CNN特征非常具有竞争力(第4节)。 此外,与标准实例检索特征处理(即PCA,白化)相比,它在所有检索基准上表现出优越的性能。
老师:SIFT和HOG描述符十年前产生了巨大的性能提升,现在深度卷积特征在识别领域提供了类似的突破。 无论如何,如果您为识别任务开发任何新算法,则必须将其与通用深度特征+简单分类器的强基线进行比较。
2 背景和大纲
本文,我们使用公开的CNN网络OverFeat。该网络的结构遵循AlexNet的结构。卷积层每个包含96到1024个大小为3×3到7×7的卷积核。ReLU作为非线性激活。大小为3×3和5×5的最大池化用于不同层以增加对类内变形的鲁棒
性。我们使用OverFeat网络的“大”版本。它需要输入尺寸为221×221的彩色图像。OverFeat针对ImageNet ILSVRC2013的图像分类任务进行了训练,并在2013年挑战的分类任务获得了非常有竞争力的结果。
ILSVRC13包含120万个图像,手动标记1000个类别。
我们列举了一系列针对不同识别任务进行的实验的结果。这些任务和数据集的选择所执行的任务和OverFeat网络解决的图像分类任务不一样。
第三节介绍视觉分类任务,第四节介绍视觉实例检索任务。所使用的CNN特征仅使用ImageNet数据进行训练,线性分类器使用特定于任务的数据集图像进行训练。 最后,我们必须指出,如果有足够的计算资源,为特定任务/数据集优化CNN特征可能会进一步提升系统的性能。
3 视觉分类
3.1 方法
对于所有的实验,除非另有说明,我们使用网络的第一个完全连接层响应(第22层)作为特征向量。
最大池化层和 ReLU 在 OverFeat 中被视为一个单独的层,与 AlexNet 不同。对于所有的实验,我们将整个图像(或裁剪的子窗口)的大小调整为221×221。 最后输出了一个4096维的向量。 我们有两个设置:
- 对于所有实验,特征向量被进一步使用 L2 正则化进行归一化。 我们使用4096维特征向量与支持向量机(SVM)结合来解决不同的分类任务(CNN-SVM)
- 我们进一步对训练集进行数据增强。通过裁剪和旋转图像。在结果中记为:CNNaug + SVM
对于训练数据集 (xi,yi)
{(x_i,y_i)},线性SVM公式如下:
minimizew12||w||2+C∑imax(1−yiwTxi,0)(1)
{minimize}_w \quad \frac{1}{2}||w||^2+C\sum_imax(1-y_iw^Tx_i,0) \quad \quad (1)3.2 图像分类
首先,我们采用CNN特征来解决物体和场景的图像分类问题。
系统应该为图像分配(可能多个)语义标签。与物体检测相反,物体图像分类不需要定位对象。 CNN特征已针对ILSVRC的物体图像分类任务进行了优化。
在这个实验中,我们选择了两种不同的图像分类数据集,物体和室内场景,其图像分布与ILSVRC数据集的图像分布不同。
3.2.1 数据集
使用的两个识别数据集:Pascal VOC 2007用于物体分类;MIT-67 用于室内场景识别。
Pascal VOC 2007 包含20个类别的10000个图像,包括动物,手工制品和自然物。 物体不居中,一般情况下VOC中的物体外观比ILSVRC更具挑战性。 实验中没有用到Pascal VOC的图像边界框。
MIT-67 indoor scenes
MIT场景数据集有6720个室内场景类的图像。
该数据集包括不同类型的商店(例如面包店,杂货店),住宅房间(如苗圃房,卧室),公共场所(如公共汽车,图书馆,监狱牢房),休闲场所(如自助餐,快餐,酒吧,movietheater)和 工作场所(如办公室,手术室,电视演播室)。
与室外场景数据集相比,不同室内场景中存在的物体的相似性使MIT indoor 识别特别困难。
3.2.2 Pascal VOC物体分类结果
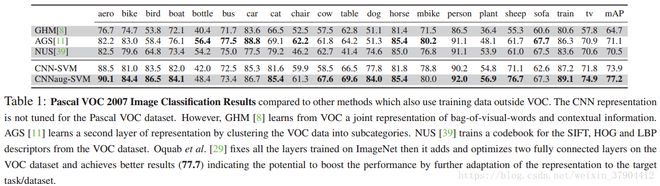
表1展示了用于物体图像分类的OverFeat CNN特征的结果。采用mAP标准进行度量。
由于OverFeat原始的特征已针对相同任务(ILSVRC)进行了训练,因此我们预计结果会相对较高。 其他的方法使用PascalVOC2007进行训练,OverFeat CNN在ILSVRC上训练(不在Pascal VOC2007上微调)。结果中看到,OverFeat CNN特征在mAP方面比以前的所有方法都有大幅度的提高。
不同的层。
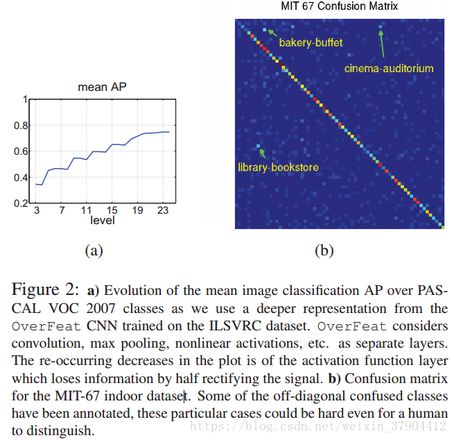
直观地说,我们可以推断,越深的层学习的权重对训练的任务变得越具体。 我们可以想象每个问题的最佳表示在于网络的中间层。
为了进一步研究这一点,我们使用每个网络层的输出为所有类训练了一个线性SVM。 结果如图2a所示。 除了最后的两层全连接层,性能都会提高。
3.2.3 MIT 67 场景分类结果
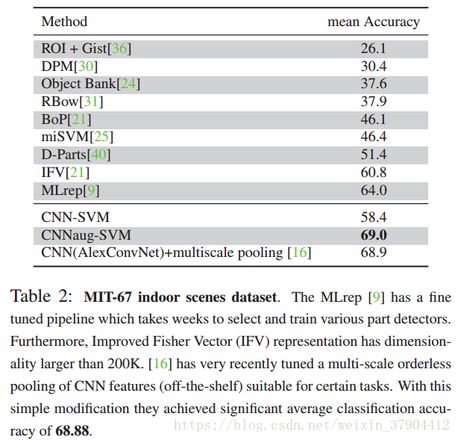
表2展示了MIT室内数据集上不同方法的结果。
使用不同类别的平均分类准确度(混淆矩阵对角线的平均值)来衡量的性能。 使用线性支持向量机的CNN显着优于大多数方法。
非CNN的方法主要受益于各种复杂的设计。
CNN-SVM分类器在67个MIT类的混淆矩阵中,有一个强对角线。可以看到,在这些例子中,即使是人类区分两个标签也是具有挑战性的,特别是对于特写镜头的场景。
3.3 物体检测
不幸的是,我们还没有进行使用CNN特征进行物体检测任务的实验。
但值得一提的是,RCNN实现了46.2的mAP,其已经超过了现有技术的约10%。 这证明CNN的特征对于视觉识别任务的强大能力。
最后,通过进一步微调PASCAL VOC 2007数据集,他们实现了53.1的结果。
3.4 细粒度分类
细粒度识别近来变得流行,因为其在商业和编目应用上展现出巨大潜力。
细粒度识别是特别有意义的,因为它涉及识别相同物体的不同子类,例如不同的鸟类,狗的品种,花类型等。已经有许多细粒度标记的新数据集帮助该领域迅速发展,例如牛津花 ,加州理工大学的鸟类,狗的品种,烹饪活动,猫狗。子类之间差异的细微之处需要更详细的特征表示。
3.4.1 数据集
使用的两个细粒度数据集:CUB 200-2011 和 102 flowers
加州理工学院的UCSD鸟类(CUB)200-2011数据集 它包含了200个鸟类子类的11,788幅图像。 5994图像用于训练,5794用于评估。 数据集中的许多物种表现出非常微妙的差异,有时甚至人类也难以区分。
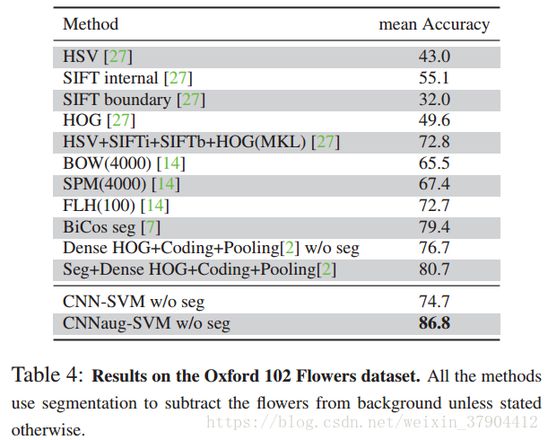
牛津102花数据集 它包含102个类别。 每个类别包含40到258个图像。 花朵出现在不同的尺度,姿势和照明条件。 此外,数据集提供了所有图像的分割。
3.4.2 结果
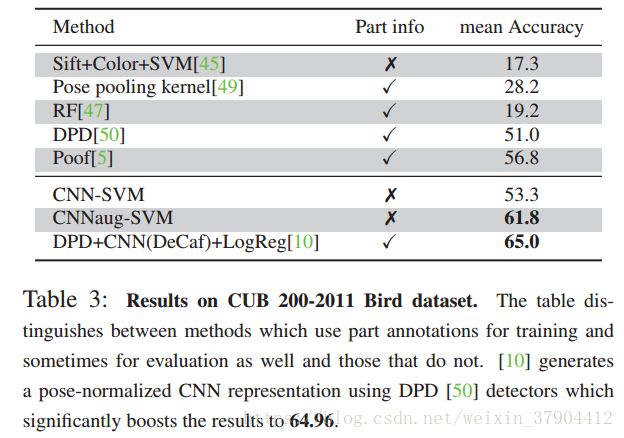
表3展示了CNN-SVM与在CUB200-2011数据集上表现最好的方法相比较的结果。 表4显示了CNN-SVM与在牛津花数据集上表现最好的方法相比较的结果。 可以看出CNN-SVM也优于其他方法。
3.5 属性检测
计算机视觉中的属性被定义为不同的实例/类别共享的一些语义或抽象的特征。
3.5.1 数据集
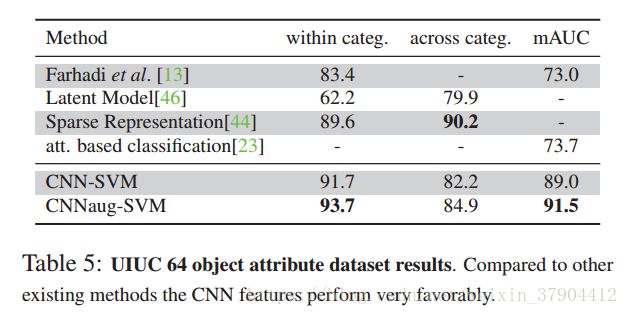
我们使用两个数据集来进行属性检测。 第一个数据集是UIUC 64物体属性数据集。
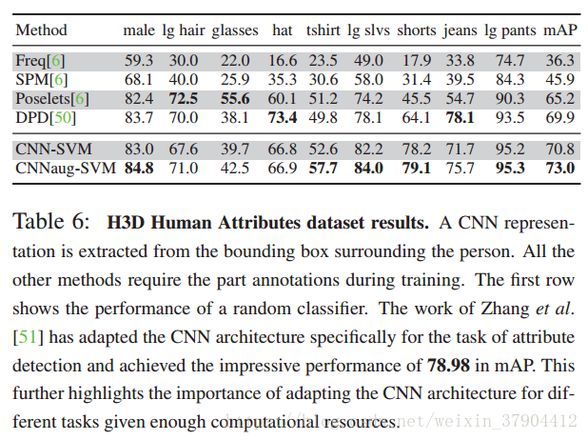
在这个数据集中有三类属性:形状(例如是二维的),部位(如有头部),材质(例如毛茸茸的)。 第二个数据集是H3D数据集,它定义了来自PascalVOC 2007的人员图像子集的9个属性。
3.5.2 结果
4 实例检索
5 结论
在这项工作中,我们使用 OverFeat CNN 特征向量结合一个简单的分类器来解决不同的识别任务。 CNN模型最初是在ILSVRC 2013数据集中对图像分类任务进行了训练。
CNN 提取的特征向量,表明它将成为更先进方法的强有力竞争者。
对于各种识别任务和不同的数据集观察到相同的趋势,这强调了学习的CN表示具备的有效性和一般性。
因此,CNN 通过深度学习获得的特征应该是大多数视觉识别任务的主要选择。
以上是 CNN Features off-the-shelf: an Astounding Baseline for Recognition 解读 的全部内容, 来源链接: utcz.com/z/264665.html