Spider 基于 RabbitMQ 中间件的爬虫的 Ruby 实现
设计思路
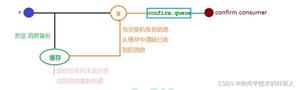
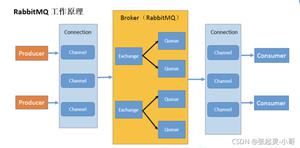
爬虫(典型的生产者 – 消费者模型)在我的理念里由以下几部分组成:
- Fetcher 抓取器:
- Fetcher 这里的实现是对 HttpClient 的封装
- Fetcher 拿到 Response 之后会判定是否需要写入队列 – 然后被消费者消费
- Scheduler 调度器
- Middleware 中间键
衍生开来:
- 多线程抓取器 – Fetcher 跑在线程里面
- 分析器 – 解析抓取的内容
怎样安装
gem install spider -s https://github.com/w-zengtao/rb-spider
依赖于
Redis
配置文件
config.yml
默认配置如下
redis:url: 127.0.0.1
port: 6379
db: 0
rabbitmq:
vhost: "/"
username: guest
password: guest
host: 127.0.0.1
如何使用
如我们在设计思路里面所讲,我们的程序的入口应该在 Scheduler 模块
源码里面的一些技巧
- Ruby的 单例模式
- Ruby的 线程池 – 也就是CPU资源池
- 利用轮询设计的 定时器
项目地址:https://github.com/w-zengtao/rb-spider
以上是 Spider 基于 RabbitMQ 中间件的爬虫的 Ruby 实现 的全部内容, 来源链接: utcz.com/z/264649.html