
如何在Pycharm中制作自己的爬虫代码模板
写作背景
最近本菜鸡有几个网站想要爬,每个爬虫的代码不一样,但 有某种联系,可以抽出一部分通用的代码制成模板,减少代码工作量,于是就有了这篇文章。
如果觉得我这篇文章写的好的话,能不能给我 点个赞 ,评论 、收藏 一条龙(☆▽☆)。如果要点个 关注 的话也不是不可以。
如果 有什么问题,还 请各位大佬提出,不胜感激。
爬虫代码
我的爬虫代码都是使用的 自己 写的 多线程。
因为我的代码能力很差,所以如果代码有哪里让各位大佬倍感不适,请及时在评论区 指出,谢谢各位大佬。
我的代码如下:
#!/usr/bin/python3
# -*- coding=utf-8 -*-
# @Author : lhys
# @FileName: proxy_tool.py
import requests
import threading
timeout = 300
lock = threading.Lock()
# 请求头用自己的
headers = {
'': ''
}
class MyProxy:
def __init__(self, proxy_api='', proxy_server='', max_use=5000, try_count=5):
if not (proxy_api or proxy_server):
raise TypeError('Proxy_api and proxy_server cannot be empty at the same time.')
self.proxies = None if not proxy_server else {
'http': proxy_server,
'https': proxy_server
}
# 代理API
self.proxy_api = proxy_api
# 代理 IP 最大使用次数
self.max_use = max_use
# 测试代理 IP 次数,超过次数即认为代理 IP 不可用
self.try_count = try_count
# 是否爬虫请求出错,如果出错,直接更换 IP
self.flag = 0
# 代理 IP 剩余生存时间
self.proxy_ttl = 0
# 各种锁
self.lock = threading.Lock()
self.ttl_lock = threading.Lock()
self.flag_lock = threading.Lock()
def set_flag(self):
self.flag_lock.acquire()
self.flag = 1
self.flag_lock.release()
def get_flag(self):
self.flag_lock.acquire()
flag = self.flag
self.flag_lock.release()
return flag
def decrease_ttl(self):
self.ttl_lock.acquire()
self.proxy_ttl -= 1
self.ttl_lock.release()
def get_ttl(self):
self.ttl_lock.acquire()
ttl = self.proxy_ttl
self.ttl_lock.release()
return ttl
def set_ttl(self):
self.ttl_lock.acquire()
self.proxy_ttl = self.max_use
self.ttl_lock.release()
def get_proxy(self):
self.lock.acquire()
proxy = self.proxies
self.lock.release()
return proxy
def set_proxy(self):
if self.proxy_ttl > 0 and self.flag == 0:
return
old = self.proxies
if self.flag == 1:
for try_count in range(self.try_count):
try:
requests.get('https://www.baidu.com', headers=headers, proxies=old, timeout=timeout)
print(f'Test proxy {old} successfully.')
return
except requests.exceptions.ProxyError or requests.exceptions.ConnectionError or requests.exceptions.ConnectTimeout:
print(f'Test proxy {old} failed.')
break
except Exception as e:
print(e)
if not self.proxy_api:
raise ValueError('代理 IP 不可用,且代理 IP API未设置。')
while True:
res = requests.get(self.proxy_api)
# 这一部分按照自己的代理 IP 文档来,仅供参考
try:
if res.json()["ERRORCODE"] == "0":
ip, port = res.json()["RESULT"][0]['ip'], res.json()["RESULT"][0]['port']
self.lock.acquire()
self.proxies = {
'http': 'http://%s:%s' % (ip, port),
'https': 'http://%s:%s' % (ip, port)
}
print(f'Set proxy: {ip}:{port}.')
self.flag = 0
self.lock.release()
self.set_ttl()
return
else:
print(f'Set proxy failed.')
except Exception as e:
print(e)
Proxy = MyProxy()
def request_by_proxy(url, use_proxy=True):
while True:
try:
# 使用代理
if use_proxy:
proxy_ttl = Proxy.get_ttl()
print(proxy_ttl)
# 如果 超过最大使用次数 或者 请求出现错误,重新设置 IP
if proxy_ttl <= 0 or Proxy.get_flag():
Proxy.set_proxy()
print(Proxy.get_ttl())
proxy = Proxy.get_proxy()
lock.acquire()
res = requests.get(url, headers=headers, proxies=proxy, timeout=timeout)
lock.release()
Proxy.decrease_ttl()
return res
else:
res = requests.get(url, headers=headers, timeout=timeout)
return res
except requests.exceptions.ProxyError as pe:
if use_proxy:
lock.release()
print(f'Proxy {Proxy.proxies} is not available, reason: {pe}.')
Proxy.set_flag()
except requests.exceptions.Timeout as t:
if use_proxy:
lock.release()
print(f'Time out, reason: {t}.')
Proxy.set_flag()
except Exception as e:
if use_proxy:
lock.release()
print(e)
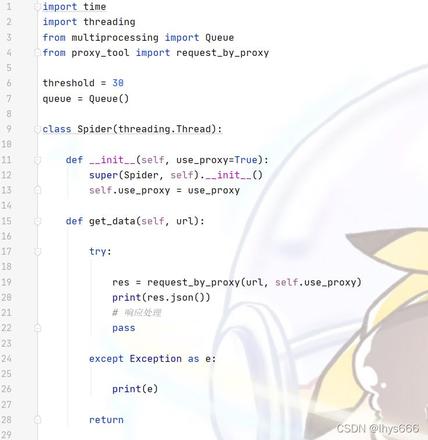
#!/usr/bin/python3
# -*- coding=utf-8 -*-
# @Author : lhys
# @FileName: spider.py
import time
import threading
from multiprocessing import Queue
from proxy_tool import request_by_proxy
threshold = 30
queue = Queue()
class Spider(threading.Thread):
def __init__(self, use_proxy=True):
super(Spider, self).__init__()
self.use_proxy = use_proxy
def get_data(self, url):
try:
res = request_by_proxy(url, self.use_proxy)
# 响应处理
pass
except Exception as e:
print(e)
return
def run(self):
while True:
# 如果队列空了,等待一会儿。
# 过了指定的时间后,如果队列出现数据,就继续爬
# 如果队列还是空的,停止线程
if queue.empty():
time.sleep(threshold)
if not queue.empty():
url = queue.get()
self.get_data(url)
time.sleep(threshold)
else:
print('Queue is empty.')
return
在 Pycharm 中设置代码模板
打开 File -> settings -> Editor -> Live Templates,点击 Python,如下图所示:
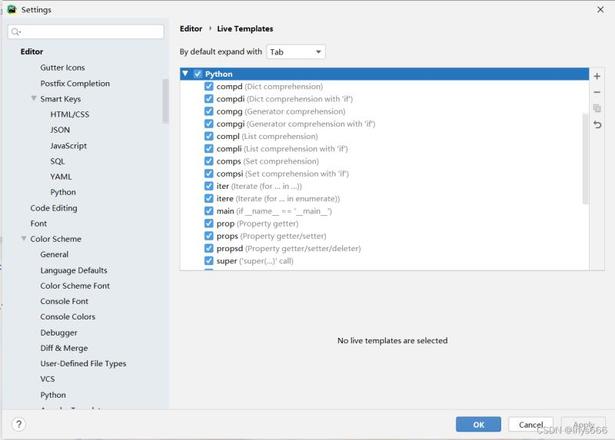
可以看到,已经有一些自动补全的模板了,以 TCP_Client 为例,如下图所示:
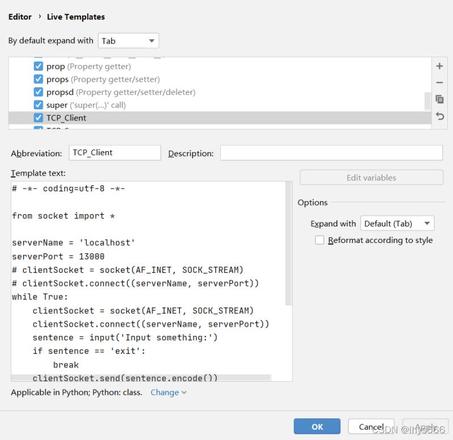
可以看到 Pycharm 有提示。

使用 TCP_Client。

如果我们要制作自己的代码模板,就点击 + ,如下图所示:
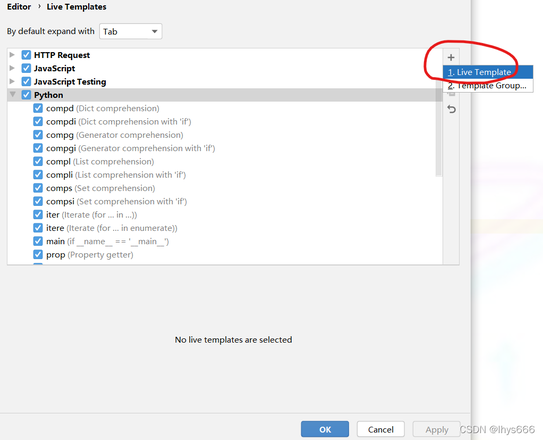
点击 Live Template 。(第二个是 创建模板组,目前我们不需要,直接在 Python 模板组下创建就好了)。
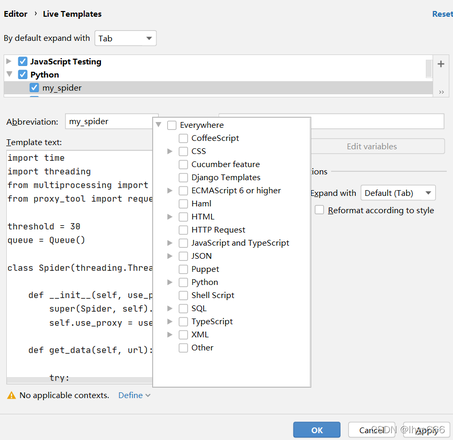
其中:
- Abbreviation 译为 缩写,就是 自动补全框中出现的名字 。
- Description 译为 描述,就是 对这个代码模板进行描述,可空。
- Template text 译为 模板文本,就是 要设置的模板代码。
然后在下方 define 处选择在哪个模板组中定义,可 根据自己需求或喜好选择模板组 ,我这里选择 Python ,点击 ok 。
测试一下:

成功完成任务!!!
到此这篇关于如何在Pycharm中制作自己的爬虫代码模板的文章就介绍到这了,更多相关Pycharm制作爬虫代码模板内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 如何在Pycharm中制作自己的爬虫代码模板 的全部内容, 来源链接: utcz.com/z/256953.html




