如何在Pandas DataFrame中获取第二大行值的列名
我有一个非常简单的问题-我想-但似乎我无法解决这个问题。我是Python和Pandas的初学者。我在论坛上进行了搜索,但没有得到符合我需要的(最新)答案。
我有一个这样的数据框:
df = pd.DataFrame({'A': [1.1, 2.7, 5.3], 'B': [2, 10, 9], 'C': [3.3, 5.4, 1.5], 'D': [4, 7, 15]}, index = ['a1', 'a2', 'a3'])这使:
A B C D a1 1.1 2 3.3 4
a2 2.7 10 5.4 7
a3 5.3 9 1.5 15
我编写了一个简单的函数,该函数返回每一行的第二个最大值
def get_second_best(x): return sorted(x)[-2]
df['value'] = df.apply(lambda row: get_second_best(row), axis=1)
这使:
A B C D valuea1 1.1 2 3.3 4 3.3
a2 2.7 10 5.4 7 7.0
a3 5.3 9 1.5 15 9.0
但是我找不到如何在“值”列中显示列名,而不是值…我正在考虑布尔索引(将“值”列的值与每一行进行比较),但是我还没有t想出了怎么做。
更清楚地说,我希望它是:
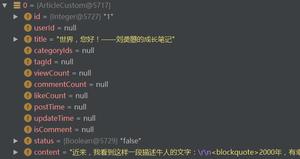
A B C D valuea1 1.1 2 3.3 4 C
a2 2.7 10 5.4 7 D
a3 5.3 9 1.5 15 B
任何帮助(和解释)表示赞赏!
回答:
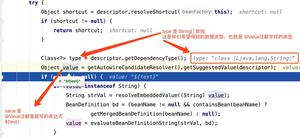
一种方法是使用来选择每一行中的两个最大元素,Series.nlargest并使用来找到对应于最小元素的列Series.idxmin:
In [45]: df['value'] = df.T.apply(lambda x: x.nlargest(2).idxmin())In [46]: df
Out[46]:
A B C D value
a1 1.1 2 3.3 4 C
a2 2.7 10 5.4 7 D
a3 5.3 9 1.5 15 B
值得注意的是捡Series.idxmin了DataFrame.idxmin可以有所作为的性能代价:
df = pd.DataFrame(np.random.normal(size=(100, 4)), columns=['A', 'B', 'C', 'D'])%timeit df.T.apply(lambda x: x.nlargest(2).idxmin()) # 39.8 ms ± 2.66 ms
%timeit df.T.apply(lambda x: x.nlargest(2)).idxmin() # 53.6 ms ± 362 µs
编辑:添加到@jpp的答案,如果性能很重要,则可以通过使用Numba,像编写C一样编写代码并将其编译来大大提高速度:
from numba import njit, prange@njit
def arg_second_largest(arr):
args = np.empty(len(arr), dtype=np.int_)
for k in range(len(arr)):
a = arr[k]
second = np.NINF
arg_second = 0
first = np.NINF
arg_first = 0
for i in range(len(a)):
x = a[i]
if x >= first:
second = first
first = x
arg_second = arg_first
arg_first = i
elif x >= second:
second = x
arg_second = i
args[k] = arg_second
return args
让我们比较形状分别为(1000, 4)和的两组数据的不同解决方案(1000, 1000):
df = pd.DataFrame(np.random.normal(size=(1000, 4)))%timeit df.T.apply(lambda x: x.nlargest(2).idxmin()) # 429 ms ± 5.1 ms
%timeit df.columns[df.values.argsort(1)[:, -2]] # 94.7 µs ± 2.15 µs
%timeit df.columns[np.argpartition(df.values, -2)[:,-2]] # 101 µs ± 1.07 µs
%timeit df.columns[arg_second_largest(df.values)] # 74.1 µs ± 775 ns
df = pd.DataFrame(np.random.normal(size=(1000, 1000)))
%timeit df.T.apply(lambda x: x.nlargest(2).idxmin()) # 1.8 s ± 49.7 ms
%timeit df.columns[df.values.argsort(1)[:, -2]] # 52.1 ms ± 1.44 ms
%timeit df.columns[np.argpartition(df.values, -2)[:,-2]] # 14.6 ms ± 145 µs
%timeit df.columns[arg_second_largest(df.values)] # 1.11 ms ± 22.6 µs
在最后一种情况下,通过使用@njit(parallel=True)并替换为外环,我可以挤出更多一点并将基准降低到852 µs for k inprange(len(arr))。
以上是 如何在Pandas DataFrame中获取第二大行值的列名 的全部内容, 来源链接: utcz.com/qa/430893.html