Pandas-在多列上使用`.rolling()`
考虑一只DataFrame看起来像下面的熊猫
A B C0 0.63 1.12 1.73
1 2.20 -2.16 -0.13
2 0.97 -0.68 1.09
3 -0.78 -1.22 0.96
4 -0.06 -0.02 2.18
我想使用该函数.rolling()执行以下计算t = 0,1,2:
- 选择从行
t到t+2 - 从所有列中获取这3行中包含的9个值。称这套
S - 计算的第75个百分位数
S(或有关的其他汇总统计数据S)
例如,对于t = 1S =
{2.2,-2.16,-0.13,0.97,-0.68,1.09,-0.78,-1.22,0.96},第75个百分位数是0.97。
我找不到与之配合使用的方法.rolling(),因为它显然需要将每一列分开。我现在依靠for循环,但这确实很慢。
您对更有效的方法有何建议?
回答:
一种解决方案是对stack数据进行处理,然后将窗口大小乘以列数,然后将结果乘以列数。另外,由于要使用前向窗口,因此请颠倒堆叠的顺序DataFrame
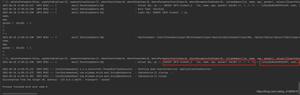
wsize = 3cols = len(df.columns)
df.stack(dropna=False)[::-1].rolling(window=wsize*cols).quantile(0.75)[cols-1::cols].reset_index(-1, drop=True).sort_index()
输出:
0 1.121 0.97
2 0.97
3 NaN
4 NaN
dtype: float64
在多列和小窗口的情况下:
import pandas as pdimport numpy as np
wsize = 3
df2 = pd.concat([df.shift(-x) for x in range(wsize)], 1)
s_quant = df2.quantile(0.75, 1)
# Only necessary if you need to enforce sufficient data.
s_quant[df2.isnull().any(1)] = np.NaN
输出: s_quant
0 1.121 0.97
2 0.97
3 NaN
4 NaN
Name: 0.75, dtype: float64
以上是 Pandas-在多列上使用`.rolling()` 的全部内容, 来源链接: utcz.com/qa/421896.html