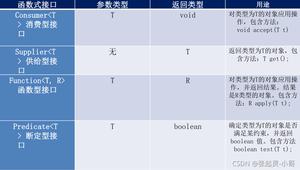
ES6使用正则表达式过滤数组
我正在尝试过滤包含一堆URL的数组。我需要返回仅包含“联系人”一词的网址。
例如,有一个链接 https://www.example.com/v1/contact-us/ca
这应该从过滤器中返回。
我尝试了这个:
const regex = new RegExp("/\bcontact\b", 'g' ) sites.links.filter((val) => {
console.log(regex.test(val.href))
})
当我知道有一个包含“联系人”一词的域时,它目前仅通过所有域发送回false。
回答:
首先,new RegExp('/\bcontact\b', 'g');它等于/\/@contact@/g哪里@是退格字符(ASCII
08)…显然不是您想要的
所以,你会做的new RegExp('/\\bcontact\\b', 'g');-这相当于/\/\bcontact\b/g
但是,\\b之后/是多余的
所以…到 /\/contact\b/g
string.match在这里使用regex.test被滥用。以下是说明
var sites = { links: [
{href: 'https://www.example.com/v1/contact-us/ca'},
{href: 'https://www.example.com/v1/contact-us/au'},
{href: 'https://www.example.com/v1/contact-us/us'},
{href: 'https://www.example.com/v1/dontcontact-us/us'}
]
};
const regex = new RegExp('/contact\\b', 'g');
const matchedSites = sites.links.filter(({href}) => href.match(regex));
console.log(matchedSites);
下一个问题是在regexp.testwith
g标志中多次使用ONE正则表达式。每次调用,它将目光从未来indexOf先前FOUND子,并在同一类型的字符串的连续调用,它基本上会返回true,false,true,false。
如果要使用regex.test,则不要重复使用相同的正则表达式,除非您知道这样做的后果或不使用g标志(此处不需要)
var sites = { links: [
{href: 'https://www.example.com/v1/contact-us/ca'},
{href: 'https://www.example.com/v1/contact-us/au'},
{href: 'https://www.example.com/v1/contact-us/us'},
{href: 'https://www.example.com/v1/dontcontact-us/us'}
]
};
const regex = new RegExp('/contact\\b', 'g');
const correctRegex = new RegExp('/contact\\b');
const matchedSitesFailed = sites.links.filter(({href}) => regex.test(href));
const matchedSitesSuccess = sites.links.filter(({href}) => new RegExp('/contact\\b', 'g').test(href));
const matchedSitesSuccess2 = sites.links.filter(({href}) => correctRegex.test(href));
console.log('failed returns:', matchedSitesFailed.length);
console.log('success returns:', matchedSitesSuccess.length);
console.log('success returns 2:', matchedSitesSuccess2.length);
以上是 ES6使用正则表达式过滤数组 的全部内容, 来源链接: utcz.com/qa/412311.html


![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)