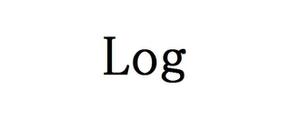O(log N)== O(1)-为什么不呢?
每当我考虑算法/数据结构时,我都倾向于用常量替换log(N)部分。哦,我知道log(N)有所不同-但是在实际应用中这有关系吗?
log(infinity)<100,出于所有实际目的。
我真的对不存在这种情况的真实示例感到好奇。
澄清:
- 我了解O(f(N))
- 我对现实世界中的示例感到好奇,在这些示例中, 行为比实际表现的 更重要。
- 如果log(N)可以用常量替换,它仍然可以用O(N log N)中的常量替换。
这个问题是出于(a)娱乐和(b)收集我在(再次)遇到有关设计性能的争议时要使用的论点。
回答:
我认为这是一种务实的方法。O(logN)永远不会超过64。在实践中,每当项变得比O(logN)小时,您就必须进行测量以查看常数因子是否胜出。也可以看看
引用其他答案的意见:
[Big-Oh]“分析”仅对至少为O(N)的因素起作用。对于任何较小的因素,大欧姆分析都是无用的,您必须进行测量。
和
“使用O(logN),输入大小确实很重要。” 这是问题的全部。当然很重要… 从理论上讲 。OP提出的问题是, 在实践
中有关系吗?我认为答案是否定的,没有,也永远不会是,logN增长如此之快以至于总是被固定时间算法击败的数据集。即使对于我们子孙后代可以想象的最大的实用数据集,logN算法也有可能击败恒定时间算法-
您必须始终进行测量。
编辑
好话:
http://www.infoq.com/presentations/Value-Identity-State-Rich-
Hickey
大约过了一半,Rich讨论了Clojure的哈希尝试,显然是O(logN),但是对数的底数很大,因此即使包含40亿个值,特里树的深度也最多为6。在这里,“
6”仍然是O(logN)值,但是它是一个非常小的值,因此选择丢弃这个令人敬畏的数据结构是因为“我真的需要O(1)”是一件愚蠢的事情。这从实用主义者的角度强调了这个问题的大多数其他答案是完全
错误 的,而实用主义者希望他们的算法“快速运行”并“很好地扩展”,而不论“理论”说什么。
编辑
也可以看看
http://queue.acm.org/detail.cfm?id=1814327
这说
如果O(log2(n))操作导致页面错误和磁盘操作缓慢,那么O(log2(n))算法有什么用?对于最相关的数据集,避免页面错误的O(n)甚至O(n ^
2)算法将在其周围运行圆圈。
(但请阅读本文以了解具体情况)。
以上是 O(log N)== O(1)-为什么不呢? 的全部内容, 来源链接: utcz.com/qa/407905.html