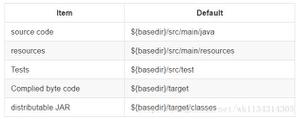
Pandas Dataframe:根据其地理坐标(经度和纬度)联接范围内的项目
我得到了一个数据框,其中包含经度和纬度的位置。想像一下城市。
df = pd.DataFrame([{'city':"Berlin", 'lat':52.5243700, 'lng':13.4105300}, {'city':"Potsdam", 'lat':52.3988600, 'lng':13.0656600},
{'city':"Hamburg", 'lat':53.5753200, 'lng':10.0153400}]);
现在,我正在尝试使所有城市都围绕另一个半径。假设距柏林500公里,距汉堡500公里的所有城市,等等。我将通过复制原始数据帧并将其与距离函数结合在一起来实现此目的。
中间结果如下所示:
Berlin --> PotsdamBerlin --> Hamburg
Potsdam --> Berlin
Potsdam --> Hamburg
Hamburg --> Potsdam
Hamburg --> Berlin
分组(减少)后的最终结果应该是这样的。 如果值列表包含城市的所有列,那将很酷。
Berlin --> [Potsdam, Hamburg]Potsdam --> [Berlin, Hamburg]
Hamburg --> [Berlin, Potsdam]
或者只是一个城市周围500公里内的城市数。
Berlin --> 2Potsdam --> 2
Hamburg --> 2
由于我是Python的新手,所以请您从任何起点入手。我对Haversine距离很熟悉。但不确定Scipy或Pandas中是否有有用的距离/空间方法。
该问题的初衷来自两个Sigma Connect租赁列表Kaggle竞赛。想法是使那些列表在另一个列表周围100m。其中a)表示密度,因此是受欢迎的区域,b)如果地址是比较的,则可以找出是否有交叉路口并因此有嘈杂的区域。因此,由于您不仅需要比较距离,还需要比较地址和其他元数据,因此您不需要完整的项与项之间的关系。
我没有将解决方案上载到Kaggle。我只想学习。
回答:
您可以使用:
from math import radians, cos, sin, asin, sqrtdef haversine(lon1, lat1, lon2, lat2):
lon1, lat1, lon2, lat2 = map(radians, [lon1, lat1, lon2, lat2])
# haversine formula
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat/2)**2 + cos(lat1) * cos(lat2) * sin(dlon/2)**2
c = 2 * asin(sqrt(a))
r = 6371 # Radius of earth in kilometers. Use 3956 for miles
return c * r
首先需要交叉与加入merge,删除一行,在相同的价值观city_x,并city_y通过boolean
indexing:
df['tmp'] = 1df = pd.merge(df,df,on='tmp')
df = df[df.city_x != df.city_y]
print (df)
city_x lat_x lng_x tmp city_y lat_y lng_y
1 Berlin 52.52437 13.41053 1 Potsdam 52.39886 13.06566
2 Berlin 52.52437 13.41053 1 Hamburg 53.57532 10.01534
3 Potsdam 52.39886 13.06566 1 Berlin 52.52437 13.41053
5 Potsdam 52.39886 13.06566 1 Hamburg 53.57532 10.01534
6 Hamburg 53.57532 10.01534 1 Berlin 52.52437 13.41053
7 Hamburg 53.57532 10.01534 1 Potsdam 52.39886 13.06566
然后应用Haversine函数:
df['dist'] = df.apply(lambda row: haversine(row['lng_x'], row['lat_x'],
row['lng_y'],
row['lat_y']), axis=1)
滤镜距离:
df = df[df.dist < 500]print (df)
city_x lat_x lng_x tmp city_y lat_y lng_y dist
1 Berlin 52.52437 13.41053 1 Potsdam 52.39886 13.06566 27.215704
2 Berlin 52.52437 13.41053 1 Hamburg 53.57532 10.01534 255.223782
3 Potsdam 52.39886 13.06566 1 Berlin 52.52437 13.41053 27.215704
5 Potsdam 52.39886 13.06566 1 Hamburg 53.57532 10.01534 242.464120
6 Hamburg 53.57532 10.01534 1 Berlin 52.52437 13.41053 255.223782
7 Hamburg 53.57532 10.01534 1 Potsdam 52.39886 13.06566 242.464120
而在去年创造list或获得size有groupby:
df1 = df.groupby('city_x')['city_y'].apply(list)print (df1)
city_x
Berlin [Potsdam, Hamburg]
Hamburg [Berlin, Potsdam]
Potsdam [Berlin, Hamburg]
Name: city_y, dtype: object
df2 = df.groupby('city_x')['city_y'].size()
print (df2)
city_x
Berlin 2
Hamburg 2
Potsdam 2
dtype: int64
也可以使用numpy haversine
solution:
def haversine_np(lon1, lat1, lon2, lat2): """
Calculate the great circle distance between two points
on the earth (specified in decimal degrees)
All args must be of equal length.
"""
lon1, lat1, lon2, lat2 = map(np.radians, [lon1, lat1, lon2, lat2])
dlon = lon2 - lon1
dlat = lat2 - lat1
a = np.sin(dlat/2.0)**2 + np.cos(lat1) * np.cos(lat2) * np.sin(dlon/2.0)**2
c = 2 * np.arcsin(np.sqrt(a))
km = 6367 * c
return km
df['tmp'] = 1
df = pd.merge(df,df,on='tmp')
df = df[df.city_x != df.city_y]
#print (df)
df['dist'] = haversine_np(df['lng_x'],df['lat_x'],df['lng_y'],df['lat_y'])
city_x lat_x lng_x tmp city_y lat_y lng_y dist
1 Berlin 52.52437 13.41053 1 Potsdam 52.39886 13.06566 27.198616
2 Berlin 52.52437 13.41053 1 Hamburg 53.57532 10.01534 255.063541
3 Potsdam 52.39886 13.06566 1 Berlin 52.52437 13.41053 27.198616
5 Potsdam 52.39886 13.06566 1 Hamburg 53.57532 10.01534 242.311890
6 Hamburg 53.57532 10.01534 1 Berlin 52.52437 13.41053 255.063541
7 Hamburg 53.57532 10.01534 1 Potsdam 52.39886 13.06566 242.311890
以上是 Pandas Dataframe:根据其地理坐标(经度和纬度)联接范围内的项目 的全部内容, 来源链接: utcz.com/qa/398339.html