【Java】HashMap
数据结构
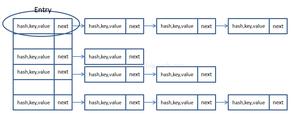
HashMap的数据结构是数组+链表。数组中存储的是Entry对象,数组中的每一个Entry元素,又是一个链表的头节点。
线程安全
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
put操作时会判断是否出现hash碰撞,假设两个线程A、B都在进行put操作,并且hash函数计算出的插入下标是相同的,当线程A执行完判断是否出现hash碰撞后由于时间片耗尽导致被挂起,而线程B得到时间片后在该下标处插入了元素,完成了正常的插入,然后线程A获得时间片,由于之前已经进行了hash碰撞的判断,所有此时不会再进行判断,而是直接进行插入,这就导致了线程B插入的数据被线程A覆盖了,从而线程不安全。
线程安全的HashMap
线程安全的有HashTable还有Collections.synchronizedMap,两种集合保证线程安全的方案都是整个集合加锁。保证线程安全的情况下也降低了效率。
ConcurrentHashMap在保证线程安全的情况下提高运行效率。
ConcurrentHashMap数据结构
ConcurrentHashMap的基本结构是Segment数组,每一个Segment是一个独立的HashMap,当我们在操作数据时,会对每个独立的Segment加锁,并不影响其他的Segment读取操作。
Get方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.再次通过hash值,定位到Segment当中数组的具体位置。
Put方法:
1.为输入的Key做Hash运算,得到hash值。
2.通过hash值,定位到对应的Segment对象
3.获取可重入锁
4.再次通过hash值,定位到Segment当中数组的具体位置。
5.插入或覆盖HashEntry对象。
6.释放锁。
JDK1.8的实现已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用Synchronized和CAS来操作,整个看起来就像是优化过且线程安全的HashMap,虽然在JDK1.8中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本.
JDK1.8版本的ConcurrentHashMap的数据结构已经接近HashMap,相对而言,ConcurrentHashMap只是增加了同步的操作来控制并发,从JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树,相对而言,总结如下思考
- JDK1.8的实现降低锁的粒度,JDK1.7版本锁的粒度是基于Segment的,包含多个HashEntry,而JDK1.8锁的粒度就是HashEntry(首节点)
- JDK1.8版本的数据结构变得更加简单,使得操作也更加清晰流畅,因为已经使用synchronized来进行同步,所以不需要分段锁的概念,也就不需要Segment这种数据结构了,由于粒度的降低,实现的复杂度也增加了
- JDK1.8使用红黑树来优化链表,基于长度很长的链表的遍历是一个很漫长的过程,而红黑树的遍历效率是很快的,代替一定阈值的链表,这样形成一个最佳拍档
- JDK1.8为什么使用内置锁synchronized来代替重入锁ReentrantLock,我觉得有以下几点
1.因为粒度降低了,在相对而言的低粒度加锁方式,synchronized并不比ReentrantLock差,在粗粒度加锁中ReentrantLock可能通过Condition来控制各个低粒度的边界,更加的灵活,而在低粒度中,Condition的优势就没有了
2.JVM的开发团队从来都没有放弃synchronized,而且基于JVM的synchronized优化空间更大,使用内嵌的关键字比使用API更加自然
3.在大量的数据操作下,对于JVM的内存压力,基于API的ReentrantLock会开销更多的内存,虽然不是瓶颈,但是也是一个选择依据。
以上是 【Java】HashMap 的全部内容, 来源链接: utcz.com/a/94695.html