【Java】Java并发编程-根源:为什么转账后,余额总是对不上?
你开发了一套转账系统,转账的流程没问题,通过了内部测试,上线后看起来也没问题。
然而,过了一段时间,用户居然可以无视余额,直接提现。眼看就要失业了,问题究竟出在哪里呢?
经过一番检查,你发现每次出事的时候,用户都同时发起了好几笔订单,导致了并发问题。
什么是并发问题
并发,就是在很短的时间内,有很多个请求同时发到了服务器上。这时候,你如果没有处理好,就出现了并发 Bug。
并发 Bug 非常奇葩,常常会导致意想不到的情况。更让人抓狂的是,这些 Bug 经常莫名其妙地出现,又莫名其妙地消失,你很难重现和追踪。
比如说,在用户提现前,你明明做了余额校验,平时没问题,但访问量一大,这个功能就忽然失效,用户余额不够,却成功提现了。
遇到这种情况,你要想找到其中的 Bug,只能一行一行地检查代码。所以,快速、精准发现并发问题,这是优秀程序员的基本功,而要做到这点,你必须深入了解并发 Bug 的源头。
并发 Bug 是计算机追求高性能的代价。
程序的运行离不开 CPU、内存、IO设备,但这么多年无论技术怎么迭代,始终有一个核心矛盾:这三者的速度差距。
CPU 的速度最快,内存的速度次之,IO设备的速度最慢。它们之间的速度差距,只能说是离谱。
打个比方,CPU 是天上一天,内存是地上一年,而 IO设备就是地上一万年。一条数据,从 IO设备传到内存要一万年,内存再传到 CPU 要一年,而 CPU 只要处理一天。这一来一回,光 IO设备就花去 2 万年。
所以,你怎么提高 CPU 性能都没用,程序的整体性能取决于最慢的操作—读写 IO设备。
那怎么平衡这三者的速度差异呢?
各路大神们是从这几个方面入手的,分别是:计算机体系结构、操作系统、编译程序。
在计算机体系结构上,增加 CPU 缓存,平衡 CPU 和内存的速度差距。
在操作系统上,增加了线程,分时复用 CPU,平衡 CPU 和 IO 设备的速度差距。
在编译程序上,优化指令的执行顺序,提高程序性能。
然而,天下没有免费的午餐,并发问题的根源就在这些优化上。
缓存带来的可见性问题
所谓可见性,就是一个线程对共享变量的修改,另外一个线程能够立刻看到。
为了平衡 CPU 和内存的速度差异,在计算机体系结构上,大神们做了创新—增加 CPU 缓存。但随着 CPU 从单核走向多核,可见性问题就出现了。
单核 CPU 是不会有可见性问题的。因为 CPU 只有 1 个,缓存也只有 1 个,所有线程都运行在这一个 CPU 上面,整个结构非常简单。
一个线程无论怎么读写数据,对其它线程都是可见的,对结果都没有影响。

然而,在多核时代,每颗 CPU 都有自己的缓存,数据就没法保持一致了。
当两个线程运行在不同的 CPU 上时,这两个线程就在操作自己 CPU 上的缓存,对其它线程是不可见的。
你可以看下面这幅图,变量 V 加载到两颗 CPU 上,线程 A 在操作 CPU-1 上的缓存,而线程 B 在操作 CPU-2 上的缓存。它们都不知道对方做了什么,变量 V 怎么算都不对。

我们来看一个具体的例子。
public class Withdraw {private long balance = 15000;
/**
* 提现
* @param amount 提现金额
* @return
*/
private void withdraw(int amount) {
/** 校验 **/
// 非法金额
if (amount <= 0) {
return;
}
// 余额不足
if (balance < amount) {
return;
}
/** 提现操作 **/
// 减余额
balance = balance - amount;
// 省略无数代码...
}
/*************** 测试函数 ****************/
private void withdraw10k() {
for (int i = 0; i < 10000; i++) {
this.withdraw(1);
}
}
private static long mockWithdraw() throws InterruptedException {
// 创建账户
final Withdraw account = new Withdraw();
// 模拟提现,发起 1 万笔订单,每次提现 1 块钱
Thread th1 = new Thread(() -> {
account.withdraw10k();
});
Thread th2 = new Thread(() -> {
account.withdraw10k();
});
// 启动两个线程
th1.start();
th2.start();
// 等待两个线程执行结束
th1.join();
th2.join();
return account.balance;
}
public static void main(String[] args) throws InterruptedException {
long balance = mockWithdraw();
System.out.println("账户余额:" + balance + " 元");
}
}
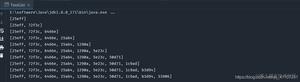
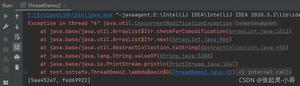
第一次执行结果-账户余额:823 元
第二次执行结果-账户余额:2274 元
第三次执行结果-账户余额:1525 元
用户有一万五千块钱,现在发起了两万笔提现订单,每笔订单一块钱。照理说,如果钱用完,就不能提现了,余额应该是 0 。但连着执行三次,每次的余额都不一样。换句话说,用户无视余额,超额提现。
其实,你想想看,如果线程一和线程二同时启动,都把 balance = 15000 读到缓存里,在执行完 balance = 15000 - 1 后,它们都把 balance = 14999 写到了内存。如果多运行几次,余额肯定越来越离谱。
因此,并发编程的第一道坎,就是保证CPU缓存的可见性。
线程切换带来的原子性问题
所谓原子性,就是所有操作要么不间断地全部被执行,要么一个也没有执行。
为了平衡 CPU 和 IO 设备的速度差距,操作系统不断迭代,出现了多线程技术。然而,多线程技术也有副作用,就是原子性问题。所以,我们要想搞清楚原子性问题,必须先了解多线程技术。
在多线程出现前,计算机是怎么运作的呢?
你想象一下这个场景,你只有一台电脑,现在想边敲代码,边听音乐,该怎么办呢?答案是,没得办。你要不就敲代码,要不就听音乐,两者只能二选一。
可是,多线程技术的出现,让 CPU 能分时复用,从此改变一切。
这是怎么做到的呢?
操作系统允许线程只运行一段时间。比如说,某个线程获得了 50 毫秒的“时间片”,那这个线程就能执行 50 毫秒。过了 50 毫秒后,操作系统做“线程切换”,这个线程休眠,换另外一个线程执行。
你可以看下面这幅图,加深一下理解。

这带来了两个好处。
第一,CPU 的利用效率大幅提高。简单来说,CPU 可以全年无休地工作了。
比如,一个线程要进行 IO 操作,读硬盘的电影什么的,那这个线程就进入“休眠状态”,让出 CPU 的使用权,另一个线程运行。等电影读到内存后,操作系统再把这个线程从休眠中唤醒,让另一个线程休眠。
第二,IO 的利用效率大幅提高,这要从两个地方说起。
首先,线程在休眠的时候,利用空闲时间读写 IO。比如,一个线程没有得到 CPU 的使用权,那可以利用空闲时间,去做 IO 操作,像是读文件什么的。
然后,IO 操作增加了排队机制。一个线程在读文件,另一个线程也要读文件,那读文件的操作就会排队。比如,一个线程读完文件后,发现有排队的任务,就立即启动下一个读操作。
这套组合拳下来,IO 的利用效率也上来了。
毫不夸张的说,多线程技术是一块里程碑,是操作系统历史上不可磨灭的一笔。
然而,这一切都是有代价的。
并发程序的实现离不开多线程,自然也会用到线程切换,但线程切换正是很多诡异 Bug 的源头。
这是为什么呢?
因为我们用的是高级编程语言。在高级编程语言里,一条语句往往会被拆成多个 CPU 指令。比如,Java 中自增运算 count++,就至少被拆成了 3 个 CPU 指令:
- 读取内存,把 count 加载到 CPU;
- CPU 执行 count+1 操作;
- 把结果写入内存;
在这个过程中,任何一个 CPU 指令执行完后,都有可能发生线程切换。换句话说,在高级语言里,一条语句不一定能被正确执行。
举个例子,假设 count = 0,有 2 个线程执行 count++,结果应该是 count = 2。在我们的想象中,count++ 是这样的,就像下面这副图一样。

然而,CPU 的原子操作只是 CPU 指令级别的,而不是编程语言的操作符。一旦发生线程切换,最后的结果就是 count = 1。实际上,count++ 是这样的。

在这个例子,count++ 没有保证原子性。原因在于,一条编程语句被拆成多个 CPU 指令,如果发生线程切换,原子性就被破坏了。
所以,在高级语言层面,怎么控制线程切换,从而保证操作的原子性?这是并发编程的第二道坎。
编译优化带来的有序性问题
所谓有序性,就是程序按代码的先后顺序运行。
为了提高程序性能,编程语言有时会改变代码的先后顺序。这很容易理解,有些代码更加重要,很多地方都要用到,但这些代码偏偏写在最后,其它地方想用就得一直等着,程序的性能肯定好不了。
所以,编译器会改变代码的先后顺序,优先执行更重要的代码。比如说,一段代码原本是这样的。
int count1 = 1;int count2 = 2;
但编译器可能觉得这段代码的效率太低,得做编译优化。结果,代码就变成了这个样子:
int count2 = 2;int count1 = 1;
然而,这也是有代价的。程序如果按照代码的先后顺序执行,的确是慢了点,可起码不会出错。但经过了编译优化,可能会出现一些意想不到的 Bug,这就是有序性问题。
最经典的例子就是通过双重检查,来创建单例对象。你在工作中,为了保证 ID 是唯一的,会用到一个唯一的 ID 生成器,而这个生成器往往是单例对象。
public class IdGen {private static IdGen instance;
static IdGen getInstance() {
if (instance == null) {
synchronized (IdGen.class) {
if (instance == null) {
instance = new IdGen();
}
}
}
return instance;
}
}
你仔细看 getInstance() 方法,好像没什么问题。一个线程获取 instance 对象时,先在 6 行代码做第一重检查,判断 instance 是不是空。如果是空,7 行代码就加锁,禁止其它线程进来,执行初始化。
这时侯,就算有其它线程同时进来,也没关系。因为 7 行代码加了锁,只有拿到锁的线程才能进来,而且等其它线程拿到锁进来,还得再经过 8 行代码的第二重检查,判断 instance 是不是空。
整个过程看上去没什么,可一旦出现编译优化,问题就来了。你留意第 9 行代码的 new 操作,如果没有做编译优化,那么应该是这样的:
- 分配一块内存 M;
- 在内存 M 上初始化 IdGen 对象;
- 把 M 的地址赋值给 instance 变量;
但编译优化以后,就变成这样了:
- 分配一块内存 M;
- 把 M 的地址赋值给 instance 变量;
- 在内存 M 上初始化 IdGen 对象;
经过这一番优化后,一旦同时进来两个线程,就有可能出现空指针异常。

因此,怎么控制编译优化,让程序能正确运行?这是并发编程的第三道坎。
写在最后
并发编程是优秀程序员的标志,而要做到这点,你得深刻理解:并发 Bug 是计算机追求高性能的代价。
为了提高性能,计算机界的大神们做了各种优化,但却破坏了程序的可见性、原子性、有序性。CPU 缓存带来了可见性问题,线程切换带来了原子性问题,编译优化带来了有序性问题。
对于这些问题,大神们再也搞不定了,我们只能自己想办法解决了。
以上是 【Java】Java并发编程-根源:为什么转账后,余额总是对不上? 的全部内容, 来源链接: utcz.com/a/94162.html