【Java】浅谈 jdk 中的 Stream 流使用及原理
jdk7 升级到 jdk8 后新增了一项非常实用的功能,Stream 流,在实际开发中有着大量的运用。相信不少同学也对 Stream 流非常熟悉,那为什么 Stream 流如此受欢迎,它的出现到底解决了哪些问题,我们一起来探讨一下。
Stream 流为什么会出现
在 Stream 流出现以前,如果我们想对一个集合进行迭代,可能会使用 forEach 或者 for in 循环,如果在迭代过程中还需要进行一些判断,可能会需要多个循环,如下所示:
List<Integer> list = new ArrayList<>(Arrays.asList(3,5,2,9,1,6,8,7));//从原先 list 中获取所有大于 5 的元素,排序,遍历
List<Integer> newList = new ArrayList<>();
for (Integer i : list) {
if(i > 5){
newList.add(i);
}
}
Collections.sort(newList);
newList.forEach(System.out::println);
复制代码
上述代码可能是不使用 Stream 流的常规写法,算上遍历总共使用了三次循环,而相同的功能用 Stream 流实现则如下所示:
List<Integer> list = new ArrayList<>(Arrays.asList(3,5,2,9,1,6,8,7));list.stream().filter(integer -> integer>5).sorted().forEach(System.out::println);
复制代码
相同的功能,用 Stream 流加 lambda 表达式实现代码量大大减少(实际上循环次数也会有一定幅度减少),而且所做的操作越多,用 Stream 流的优势就越明显。因此 Stream 流的出现主要是为了简化迭代的操作,提高迭代效率。
回顾 Stream 流的基本使用
Stream 流提供了非常强大的功能,我们先回顾一下 Stream 流中的常用 API。
创建流
Stream.of(1,2,3,4);Arrays.asList(1,2,3,4).stream();
//可以替代 for i 循环
IntStream.range(1,5);
//以下两种笔者暂时没用到过,可以生成长度无限的流
Stream.generate(Math::random);
Stream.iterate(1, item -> item + 1);
复制代码
流的操作
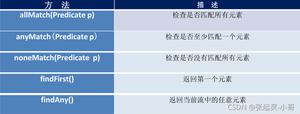
Stream 流提供了丰富的操作类型,如下图所示

简单解释一下表格中加粗字体的含义:
中间操作:从字面上看是流从开始到结束中间的一环,从操作结果上看是上一个流经过中间操作生成了下一个流,从代码上看实际上是生成了一个个 stage 和 sink节点,至于 sink 节点是什么,后面的篇幅会分析
结束操作:和中间操作相反,结束操作之后是流的最后一个环节,不再生成新的流,从代码上看是启动整个 sink 节点从头开始运行
有状态:简单理解就是需要获取流中所有数据之后才能进行的操作,比如
sort排序,肯定要获取了所有的元素之后才能排序无状态:不需要获取所有元素,只需要对单个元素进行的操作,比如
filter过滤,只针对每一个元素本身所做的操作短路:终结操作中只要有一个元素可以得到操作结果的数据,比如
findAnyMatch,只要有一个节点满足筛选条件就会返回 true非短路:需要遍历所有的节点才能得到预期结果,比如
forEach、max
常用操作
以下列举以下笔者日常开发中常用的流操作
- filter:
filter方法会接收一个 Predicate 函数,该函数用于判断元素是否被过滤,返回为 true 的元素继续流下下一个流 - collect:
collect方法可以指定一个用于接收流元素的容器,常用的是Collectors.toList(),Collectors.toSet() - forEach:
forEach方法,类似 for 循环,简单实用,用于遍历 - sorted:
sorted方法用于排序,可以传入自定义的比较器,和集合的比较器相同,不传则按照元素本身比较大小 - map:
map方法用于将上一个流中的元素映射成下一个流,如 userStream.map(User::getName) (伪代码)可以将 user 流映射成 user 名称流,非常实用 - findAny:
findAny方法用于从流中找到任意一个元素,可以理解成判断经过中间操作之后流中还有没有元素了
Stream流原理探究
回顾了神奇的 Stream 流之后,我们比较好奇流内部是怎么实现的,这就少不了去探究 jdk 的源码了,源码分析向来是一项繁琐复杂的过程,因为诸如 jdk 源码这种高度工程化的代码使用了大量的设计模式和高度的接口封装,我们就以上述代码为例简单探究一下流的实现原理。
首先看一下类的继承关系图:

- BaseStream 规定了流的基本接口
- Stream中定义了 map、filter、flatmap 等用户关注的常用操作
- BaseStream Stream IntStream LongStream DoubleStream 组建了 Java 的流体系根基
- PipelineHelper 主要用于 Stream 执行过程中相关结构的构建 ReferencePipeline 和 AbstractPipeline
AbstractPipeline 是流水线的核心抽象类,用于构建和管理流水线。它的实现类就是流水线的节点
- Head、StatelessOp、StatefulOp 为 ReferencePipeline 中的内部类,[Int | Long | Double]Pipeline 内部也都是定义了这三个内部类
以 ReferencePipeline 为例,从继承图上看,ReferencePipeline 中的 Head、StatelessOp、StatefulOp 内部类都继承了 ReferencePipeline ,而ReferencePipeline 本身又继承了 AbstractPipeline,所以无论是 Head 还是 StatelessOp、StatefulOp 本质上都是一个 AbstractPipeline,与 netty 中的 pipeline 不同,这里的这里的每一个 pipeline 都是一个节点。因此 AbstractPipeline 是非常重要的一个类,点开该类如下所示,其中有比较重要的几个属性:sourceStage(源阶段),previousStage(上游 Stage,前一阶段),nextStage(下游 Stage,下一阶段)。
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
//指向 Head 节点
@SuppressWarnings("rawtypes")
private final AbstractPipeline sourceStage;
//上游 Stage
@SuppressWarnings("rawtypes")
private final AbstractPipeline previousStage;
protected final int sourceOrOpFlags;
//下游 Stage
@SuppressWarnings("rawtypes")
private AbstractPipeline nextStage;
//定义的抽象方法,子类实现,返回一个 Sink 对象
abstract Sink<E_IN> opWrapSink(int flags, Sink<E_OUT> sink);
...
}
复制代码
源码中,以 Stage 来描述每个阶段,而且是典型的双向链表结构。因此 Stream 流过程可以用下图描述

为了证明上图的正确性,我们点开源码逐步分析
list.stream().filter(integer -> integer>5).sorted().forEach(System.out::println);复制代码
1. 生成 Head 对象
第一步是 stream 方法,最终调用到下面的代码,可以看出,调用完 stream 方法后本质上生成了一个 Head 对象
public final class StreamSupport {public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
//生成 Head
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
}
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
// 上游 Stage,Head 上游为 null
this.previousStage = null;
// 源分裂器,可以理解成高级版本的迭代器
this.sourceSpliterator = source;
// Head 指针,指向自己
this.sourceStage = this;
//是否是中间操作的标志
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;
// The following is an optimization of:
//源以及所有操作的组合源的操作标志,包括此管道对象表示的操作。在评估管道准备时有效。
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
//此管道对象与流源(如果是顺序)之间的中间操作数,Head 的 depth 为 0
this.depth = 0;
//如果管道是并行的,则为真,否则管道是顺序的;仅对源阶段有效.
this.parallel = parallel;
}
}
复制代码
2. 生成 filter 对应的操作对象
第二步是 filter 方法,最终调用如下,创建了一个无状态的操作对象 StatelessOp,创建对象时会将 Head (this) 对象传入,构建双向链表关系,同时也会记录 sourceStage (Head) 。至此,上图的指向关系已经明了。
@Overridepublic final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
//这里的 this 是 Head 对象 ,最终会被当前 StatelessOp 对象作为 previousStage 记录,同时也会将 Head 对象的 nextStage 指向 StatelessOp
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
//过滤的实现
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
//将 Head 的 nextStage 指针指向当前对象,即封装了 filter 的 StatelessOp 对象
previousStage.nextStage = this;
//将 StatelessOp 对象的 previousStage 指向 Head
this.previousStage = previousStage;
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
//将 StatelessOp 对象的 sourceStage 指向 Head
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
复制代码
这里出现了 Sink 接口和 Sink 接口的实现类 ChainedReference ,Sink 接口是用来联系当前流和下一个流的协议接口,每个 AbstractPipeline 的具体子类都要实现 opWrapSink 方法返回一个 Sink 实例。
interface Sink<T> extends Consumer<T> {//开始方法,可以通知下游做些相关准备
default void begin(long size) {}
//结束方法,告诉下游已经完成所有元素的迭代操作
default void end() {}
//是否是短路操作
default boolean cancellationRequested() {
return false;
}
//...
//Sink 接口的默认实现类
static abstract class ChainedReference<T, E_OUT> implements Sink<T> {
//此处的 downstream 意指下游的处理 sink
protected final Sink<? super E_OUT> downstream;
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
@Override
//默认直接调用下游的 begin 方法
public void begin(long size) {
downstream.begin(size);
}
@Override
//默认直接调用下游的 end 方法
public void end() {
downstream.end();
}
@Override
//返回是否短路
public boolean cancellationRequested() {
return downstream.cancellationRequested();
}
}
}
复制代码
3. 生成 sorted 对应的对象
第三步的 sorted 方法,sorted 返回的是 OfRef 类的一个实例,类似 filter ,同样也实现了 opWrapSink 方法,不过因为 sorted 方法实现的是排序功能,所以这里会确定比较器 comparator,最后由比较器实现排序逻辑。
private static final class OfRef<T> extends ReferencePipeline.StatefulOp<T, T> {OfRef(AbstractPipeline<?, T, ?> upstream) {
//类似 filter 方法,确定上下游 stage 关系
super(upstream, StreamShape.REFERENCE,
StreamOpFlag.IS_ORDERED | StreamOpFlag.IS_SORTED);
this.isNaturalSort = true;
@SuppressWarnings("unchecked")
//默认比较器
Comparator<? super T> comp = (Comparator<? super T>) Comparator.naturalOrder();
this.comparator = comp;
}
//...
@Override
public Sink<T> opWrapSink(int flags, Sink<T> sink) {
Objects.requireNonNull(sink);
if (StreamOpFlag.SORTED.isKnown(flags) && isNaturalSort)
return sink;
else if (StreamOpFlag.SIZED.isKnown(flags))
return new SizedRefSortingSink<>(sink, comparator);
else
//返回的是 RefSortingSink 实例
return new RefSortingSink<>(sink, comparator);
}
//...
}
private static final class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList<T> list;
RefSortingSink(Sink<? super T> sink, Comparator<? super T> comparator) {
super(sink, comparator);
}
@Override
//开始操作,初始化一个 list,用于接收上游流过来的元素,进行排序
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
}
@Override
//实际的排序操作
public void end() {
list.sort(comparator);
downstream.begin(list.size());
//终结操作不是短路操作,遍历
if (!cancellationWasRequested) {
list.forEach(downstream::accept);
}
//终结操作是短路操作,找到满足的元素
else {
for (T t : list) {
if (downstream.cancellationRequested()) break;
downstream.accept(t);
}
}
//结束
downstream.end();
list = null;
}
@Override
//添加元素到初始化好的 list 中
public void accept(T t) {
list.add(t);
}
}
复制代码
4. 拨动齿轮
至此为止,我们已经构建好了双向链表的操作,每个操作都被保存到一个个 StatelessOp 或者 StatefulOp 对象中,但在之前的操作中,我们封装好的 Sink 对象并没有实际调用,这也是为什么 Stream 流如果不进行终结操作之前的中间操作都不会触发的原因,万事俱备,只欠东风。东风就是终结操作,点开本例中的 forEach 方法。
@Overridepublic void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
return new ForEachOp.OfRef<>(action, ordered);
}
OfRef(Consumer<? super T> consumer, boolean ordered) {
super(ordered);// 父类ForEachOp,参数表述遍历是否有序,前面传入的false
this.consumer = consumer;
}
复制代码
此 ForEachOps 是用户创建 TerminalOp 实例的工厂类。TerminalOp 是终止操作最顶层的一个接口。TerminalOp 接口的实现类有 ForEachOp, ReduceOp, FindOp, MatchOp。ForEachOps.makeRef 方法返回了一个封装了 forEach 操作的 ForEachOp 对象。
//ForEachOp 实现了 TerminalSink,本质上也是 Sinkstatic abstract class ForEachOp<T>
implements TerminalOp<T, Void>, TerminalSink<T, Void> {
private final boolean ordered;
protected ForEachOp(boolean ordered) {
this.ordered = ordered;
}
// TerminalOp
@Override
public int getOpFlags() {
return ordered ? 0 : StreamOpFlag.NOT_ORDERED;
}
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
return helper.wrapAndCopyInto(this, spliterator).get();
}
//...
}
复制代码
有了 ForEachOp 对象,我们回到 evaluate 方法,拨动齿轮的最后一环。此处我们用的是串行流,最后会走到 terminalOp.evaluateSequential 方法中
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
//串行流,此处的 this 就是 sorted 方法返回的 StatefulOp 对象
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
@Override
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
//调用 StatefulOp 对象的 wrapAndCopyInto 方法,从之前的继承关系图可以知道 AbstractPipeline 是 PipelineHelper 的子类
//此处的 this 是 forEachOp
return helper.wrapAndCopyInto(this, spliterator).get();
}
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
// 将 ForEachOp 对象也封装成 sink,ForEachOp
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
//封装 sink 操作,找到 Head 的下一个节点,此处是 filter 生成的 StatelessOp 节点
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
//遍历将 Stage 包装成 Sink
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
复制代码
最后我们看一下 copyInto 方法, forEach 是非短路操作
@Overridefinal <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
//非短路操作
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
//调用之前包装的 Sink 的 begin 方法,进行前置通知
wrappedSink.begin(spliterator.getExactSizeIfKnown());
//spliterator 数据源进行迭代
spliterator 数据源进行迭代.forEachRemaining(wrappedSink);
//调用之前包装的 Sink end 方法,进行后置通知
wrappedSink.end();
}
//短路操作在执行遍历的时候会调用 Sink 封装的 cancellationRequested 方法,如果返回出就不会进行后面的操作
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
@SuppressWarnings("unchecked")
@Override
// Sink 接口继承了 Consumer 接口
public void forEachRemaining(Consumer<? super T> action) {
Object[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
if ((a = array).length >= (hi = fence) &&
//index 从 0 开始, hi 是集合长度
(i = index) >= 0 && i < (index = hi)) {
//循环调用 accept 方法
do { action.accept((T)a[i]); } while (++i < hi);
}
}
复制代码
至此,水落石出。
用面向对象的思维去理解 Stream 流
类比实际生活,我们可以将 Stream 流比作水流,中间操作则是相当于水流过程中的蓄水池,Sink则是每个蓄水池的操作者,终结操作则是下达指令的指挥官。此例中的操作可如下图:

总结
Stream 流为开发人员提供了遍历的迭代操作,在 js 等其他语言也存在类似的迭代操作,熟练掌握 Stream 流会有效提高开发效率。本文中对 Stream 流的使用和原理进行了最简单的剖析,更高级功能并未涉及,如并行化流会应用到多线程。由于笔者目前还没涉及到并行化流的操作,所以文章中并未提及,有兴趣的同学可以自行研究。
从 Stream 流可以深切地体会到面向对象的思想,面向对象能让代码变得更加形象以及更富有生命力。资深面向对象语言的开发者开发的作品宛如艺术品,以Stream 流为例,其中用到的责任链编程非常经典,诸如 spring 框架中的过滤器链或是 netty 中的处理链都是用的该责任链编程。
参考: 《2020最新Java基础精讲视频教程和学习路线!》
链接:https://juejin.cn/post/691194...
以上是 【Java】浅谈 jdk 中的 Stream 流使用及原理 的全部内容, 来源链接: utcz.com/a/91665.html