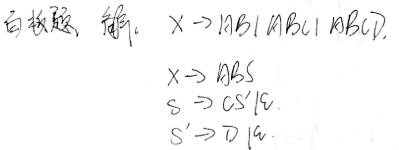【JS】浏览器原理--编译流程初探
Browser Introduction
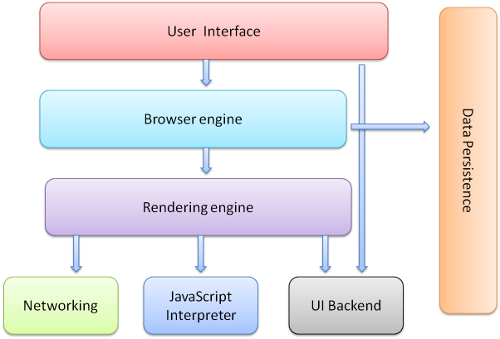
浏览器基础架构
浏览器主要组成部分
渲染引擎的基本工作流
Parsing & DOM tree construction
解析流程
编译流程
HTML解析遵循的原则:
DOM Document Object Model
我们看一个例子
被解析为
解析算法流
标记算法

DOM树构造算法
当解析器创建好时,Document 对象也创建好了
在树的构建阶段,会改变包含 Document 根节点的 DOM 树,还会添加元素到 DOM 树。每个被分词器释放的节点都将被树构建器加工
对于每个标记,规范会定义与它相对应的 DOM 元素,并且为该元素创建这个 DOM 元素
除了将元素添加到 DOM 树中外,还会将元素添加到一个开放元素的堆中。这个堆用于修正嵌套错误和未关闭的元素。
构建算法是通过状态机的形式表示的。这些状态叫作"嵌入模式"。
解析结束的操作
浏览器容错
浏览器容错机制







CSS解析器

解析JS
网络模型是同步的【同步 async defer】
预解析
当有样式在加载和解析时,Firefox 会阻塞所有的脚本。
Webkit 仅会阻塞这些试图获取特定的样式属性,这些属性可能会受未加载的样式影响,的脚本。
Render tree construction
渲染引擎的基本工作流
webkit主流程
Gecko主流程
渲染树 由可视元素组成,
这些元素按将要展示的顺序排列。它是文档的视觉呈现。
渲染树的目的是保证内容有序绘制。
一个渲染器知道如何布局和绘制自身及其子类。
Firefox 把渲染树中的元素叫作 "帧"(frames)。
Webkit 把这些元素叫作 "渲染器"(renderer)或 "渲染对象"(render object)。
webkit盒模型

Render树的构建
渲染树和与之对应的 DOM 树,Viewport 是初始的包含块。
在 Webkit中,Viewport 是 RenderView 对象。
Webkit 中,分解样式和创建渲染器的过程叫作 "附着"(attachment)。每个 DOM 节点都有一个 attach 方法。"附着" 是同步的,节点插入到 DOM 树中会调用新节点的 attach 方法。
Firefox 中,构建过程表现为为 DOM 的更新注册一个监听器(listener),然后将帧的创建委派给 “帧构建器”,构建器会分解样式,创建帧。
样式计算
构建渲染树需要计算每个渲染对象的可视属性。通过计算每个元素的样式属性来完成
样式计算带来了一些难题
1、样式数据的结构庞大,包含了许多的样式属性,可能会引起内存问题。
2、如果没有优化,那么为每个元素查找匹配规则会导致性能问题。为每个元素查找匹配遍历整个规则表是一项繁重的任务。
选择器可以有复杂的结构,这会导致匹配过程会从看上去有希望的路径开始匹配,而实际上却是无效的,然后再去尝试新的匹配路径。3、应用规则涉及非常复杂的级联规则,这些规则定义了规则的层次结构。
共享样式数据(Sharing style data)
Webkit 节点引用样式对象(渲染样式 RenderStyle)。这些对象在某些情况下,可以被节点共享。这些节点是兄弟节点以及:
1、这些元素必须在相同的鼠标状态下(比如,不能一个是 :hover 状态,其他的不是)
2、元素不应该有 ID
3、标签名称应该能匹配
4、class 属性应该能匹配
5、映射属性集必须完全相同
6、link 状态必须匹配
7、focus 状态必须匹配
8、元素不能受到属性选择器的影响,影响被定义为可匹配到使用了元素中的任何属性的属性选择器。
9、元素不能存在行内样式属性
10、不能使用兄弟选择器。WebCore 遇到兄弟选择器时会抛出一个全局开关,为整个文档关闭样式共享。这些选择器包括:+ 选择器,:first-child 和 :last-child 等。
Firefox 规则树(Firefox rule tree)
为了更简单的样式计算,Firefox 提供了两种树
规则树和样式上下文树。
Webkit 也有样式对象,但是他们不是储存在类似于样式上下文树的树中,它只有 DOM 节点指向相应的样式。
渐进的过程:
Webkit 使用一个标志来标记顶层样式表是否加载完成(包括 @imports)。
当使用样式时,发现样式没有完全加载完成,将会使用占位符,并且在文档中进行标记,当样式加载完成时,会重新进行计算。
Layout & Painting
Layout
渲染器创建完成并被添加到渲染树时,它没有位置(position)和 大小(size)。
计算这些值的过程叫作 布局(layout)和 回流(reflow)
HTML 使用基于流的布局模型,从左到右、从上到下。
但也有例外——比如 tables,就需要多次计算(3.5)
坐标系统和根框架相关,使用上侧和左侧坐标。
布局是一个递归的过程。从根渲染器开始,与 HTML 文档的元素相对应。布局会在其中一些或所有框架层级中持续递归,为每个渲染器计算几何信息。
根渲染器的位置是 0,0,它的大小是视口大小——浏览器窗口的可视部分。
所有的渲染器都有一个 layout(布局) 和 reflow(回流) 方法,每个渲染器都会调用那些需要布局的子渲染器的 layout 方法。
脏值系统
为了避免为每个小的变动都进行一次完整的布局,浏览器使用了脏值系统。
一个渲染器改变或添加了之后会标记自己及其子代为“dirty”——需要布局。
有两种标志——“dirty”和“children are dirty”。后者意味着虽然渲染器本身没问题,但是它至少有一个需要布局的子代。
布局过程
布局通常有下面几种模式:
父渲染器决定自己的宽度
父渲染器遍历子渲染器,然后
放置子渲染器(设置它的x和y)
如有需要,调用子渲染器的layout(布局)方法——它们是脏的或者我们在全局布局中,或者其他某些原因——这会计算子渲染器的高度。
父渲染器使用子渲染器的高度、外边距、内边距的累加高度来设置自己的高度——父渲染器的父渲染器也会使用这个高度。
设置脏值为false。
在一个渲染器在布局过程中发现需要折行,它会停下来,通知父渲染器它需要折行。父渲染器就会创建额外的渲染器,然后调用这些渲染器的layout方法。
Painting
在绘制阶段,会遍历渲染器树,调用渲染器的 paint 方法,在屏幕上排列内容。绘制使用 UI 基础组件
CSS2 规定了绘制程序的顺序。这实际上就是元素在层叠上下文(stacking context)中如何层叠的顺序。
一个块级渲染器的层叠顺序如下:
background color(背景颜色)
background image(背景图片)
border(边)
children(子级)
outline(轮廓)
以上是 【JS】浏览器原理--编译流程初探 的全部内容, 来源链接: utcz.com/a/91089.html