【Java】超大份线程池,干杯,兄弟!陆
开篇闲扯
这应该是短时间内最后一篇原创多线程的文章了,不是因为别的,就是因为起名字有点词穷了,也不知道UC编辑部啥时候能有我一个位置。
其实这6篇文章仅仅是多线程的冰山一小角,不论是面试还是实际工作开发,这些都是不够的。还是要多看书本上的知识,看博客得到的知识点都是盲人摸象,不成体系,这是最可怕的。如果把多线程比作一块拼图的话,那么你看的每一篇(包括我的文章)博客都仅仅是这块拼图中的零散几片,需要很长时间才能得到这个完整的多线程拼图。而当你集齐了多线程拼图的时候又会发现,原来多线程也不过是整个Java生态里的一小块,而Java生态也仅仅是软件开发行业中的产业链之一。
读专业书籍的好处在于能够快速建立相关知识的体系,少走弯路,降低重复收集知识拼图的可能性。气氛烘托到这儿了,推荐几本多线程的书给大家吧。第一本《Java并发线程入门到精通》作者是张振华,属于入门到精通类书本。另一本则是Doug Lea参与编写的《Java并发编程实战》,这本书值得精读,读完你会觉得脚底生风,风生水起,起伏不定...还有就是我不是卖书的,如果你不想花(想)钱(白)买(嫖),可以公众号私信我,免费分享PDF,仅供学习交流昂,咱也免责一下。
扯多了,那么本篇主要内容就是线程池,包括SingleThreadPool、FixedThreadPool、ScheduledThreadPool、CacheThreadPool和WorkStealingThreadPool等不同水池子,其中前4中比较常见,最后一种是在1.8及以后新增的线程池。
线程池概述
在开发过程中,我们都知道使用多线程来提升系统的吞吐量,但是无限制的创建线程反而会给系统带来负担,内存分配不足,CPU超负荷等等,而且过多的线程也会导致频繁的线程切换,前面有写过:频繁的上下文切换会导致严重的性能损耗。
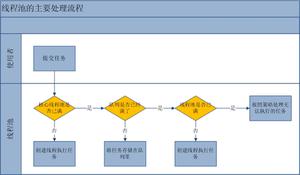
以我们常见的HotSport虚拟机为例,它的线程模型规定Java创建的线程是和计算机内核线程是一对一的,那么Java线程的创建与销毁就对应着内核线程的创建与销毁,而线程创建与销毁设计到内存空间申请、分配等动作,对资源的消耗可想而知。因此,线程池的出现就为让已知任务量的系统中保持着一定数量的工作线程,提升线程复用,控制线程数量,降低线程创建销毁的频率。下面用一张图展示线程池的工作原理:

四种拒绝策略
| 策略名 | 解释 |
|---|---|
| AbortPolicy | 丢弃任务并抛出RejectedExecutionException,默认该方式。 |
| DiscardPolicy | 丢弃任务,但是不抛出异常 |
| DiscardOldestPolicy | 丢弃workQueue中最前面的任务,然后重新尝试执行任务 |
| CallerRunsPolicy | 由调用线程自己处理该任务 |
五种线程池状态
| 状态名 | 解释 |
|---|---|
| running | 该状态的线程池能够接受新任务,并对新添加的任务进行处理 |
| shutdown | 该状态的线程池不再接受新任务,但是会把阻塞队列中的任务全部执行完 |
| stop | 该状态的线程池不再接收新任务,不处理阻塞队列的任务,并且中断正在处理的任务 |
| tidying | 当所有的任务已终止,ctl记录的"任务数量"为0,线程池会变为TIDYING状态 |
| terminated | 线程池彻底终止的状态 |
通过源码看一下线程池状态在代码中是如何体现的:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));//表示一个int型占用32位,减去3位表示29位
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
//将-1左移29位后变成111
private static final int RUNNING = -1 << COUNT_BITS;
//将0左移29位后是000
private static final int SHUTDOWN = 0 << COUNT_BITS;
//将0左移29位后是001
private static final int STOP = 1 << COUNT_BITS;
//将0左移29位后是010
private static final int TIDYING = 2 << COUNT_BITS;
//将0左移29位后是011
private static final int TERMINATED = 3 << COUNT_BITS;
通过源码看到,通过ctl的高3位记录了线程池的运行状态,而低29位则记录了线程池中的任务数量。
六个核心参数
| 参数名 | 参数说明 |
|---|---|
| corePoolSize(核心线程数) | 核心线程数量,线程池维护线程的最少数量 |
| workQueue(任务等待队列) | 保存等待执行任务的阻塞队列 |
| maximumPoolSize(线程池线程数最大值) | 线程池所允许的最大线程个数。当队列满了,且已创建的线程数小于maximumPoolSize,则线程池会创建新的线程来执行任务 |
| keepAliveTime(线程存活时间) | 当线程池中线程数大于核心线程数时,线程的空闲时间如果超过线程存活时间,那么这个线程就会被销毁,直到线程池中的线程数小于等于核心线程数 |
| threadFactory(线程工厂) | 用于创建新线程。threadFactory创建的线程也是采用new Thread()方式,threadFactory创建的线程名都具有统一的风格:pool-m-thread-n(m为线程池的编号,n为线程池内的线程编号)。 |
| handler(线程饱和策略) | 当线程池和队列都满了,再加入线程会执行此策略。 |
七种阻塞队列
| 队列名 | 数据结构 | 解释 |
|---|---|---|
| ArrayBlockingQueue | ArrayList | 由数组结构组成的有界阻塞队列 |
| LinkedBlockingQueue | LinkList | 由链表结构组成的无界阻塞队列 |
| PriorityBlockingQueue | heap | 支持优先级排序的无界阻塞队列 |
| DealyQueue | heap | 使用优先级队列实现的无界阻塞队列 |
| SynchronousQueue | 无 | 不存储元素的阻塞队列 |
| LinkedTransferQueue | heap | 由链表结构组成的无界阻塞队列 |
| LinkedBlockingDeque | heap | 由链表结构组成的双向阻塞队列 |
阻塞队列这块东西特别多,在并发包里的地位也很高,就这七个队列如果想写的很详细够写七篇文章的,这里就不仔细说了,因为我也还没研究他们的实现,暂时也只是略有了解....记在小本本上了,我会补上的。
五种常见线程池
SingleThreadPool
先看一下它的构造方法:
// 重点在阻塞队列上public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
把它上面的注释翻译过来就是“创建一个使用单个工作线程的执行器,同时它的队列是无界的。(但是请注意,如果这个单个线程在关闭之前的执行过程中意外终止,则在需要执行后续任务时,将替换一个新的线程。)任务被保证按顺序执行,并且在任何给定的时间内不会有多个任务处于活动状态”还特别强调了:Unlike the otherwise equivalent newFixedThreadPool(1),有兴趣可以研究一下源码,但其实没必要。
演示一下基本用法:
/*** FileName: SingleThreadPool
* Author: RollerRunning
* Date: 2020/12/14 7:35 PM
* Description: 但线程的线程池
*/
public class SingleThreadPool {
public static ExecutorService singleThreadExecutor;
static {
singleThreadExecutor = Executors.newSingleThreadExecutor();
}
public static void main(String[] args) {
for (int i = 0; i < 100; i++) {
final int temp = i;
singleThreadExecutor.execute(new Runnable() {
@Override
public void run() {
Thread.currentThread().setName(String.valueOf(temp));
System.out.println("线程 "+Thread.currentThread().getName()+" 开始执行...");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
singleThreadExecutor.shutdown();
System.out.println("===========Main Thread Over!=========");
}
}
大家可以尝试运行一下,能够看到所有线程都是顺序执行的,SingleThreadExecutor是一个单线程的线程池,如果当前线程意外终止,线程池会创建一个新线程继续执行任务,以保证任务能够完成。
不知道你们通过这个例子有没有发现问题,其实这么创建线程池,是有把服务搞死的风险,通过源码可以看到构造方法中用到的任务等待队列是LinkedBlockingQueue,理论上说它是一个无线队列,最大值为Integer.MAX_VALUE,就有OOM的风险。因此,在使用时,如果没有特殊需求,还是使用ThreadPoolExecutor进行创建线程池,可以自定义线程池的任意参数。
FixedThreadPool
先看一下它的构造方法:
// 指定线程数public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
// 执行线程数和线程工厂类
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
基础用法同上面的类似,只是初始化线程池用到的API不同
public class FixedThreadPool {public static ExecutorService fixedThreadPool;
static {
//初始化固定核心线程数的线程池
fixedThreadPool = Executors.newFixedThreadPool(5);
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 20; i++) {
final int temp = i;
fixedThreadPool.execute(new Runnable() {
@Override
public void run() {
Thread.currentThread().setName(String.valueOf(temp));
try {
System.out.println("线程 " + Thread.currentThread().getName() + " 开始...");
Thread.sleep(1000);
System.out.println("线程 " + Thread.currentThread().getName() + " 结束...");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
System.out.println("*********************");
fixedThreadPool.shutdown();
System.out.println("===========Main Thread Over!=========");
}
}
ScheduledThreadPool
创建一个周期线程池,支持定时周期性执行线程池中的任务。
上构造:
public ScheduledThreadPoolExecutor(int corePoolSize,ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
可以看出不同于其他线程池的点是使用了延迟工作队列,在源码中也增加了两个定时执行的方法:
public ScheduledFuture<?> scheduleAtFixedRate(Runnable command,long initialDelay,long period,TimeUnit unit) {}public ScheduledFuture<?> scheduleWithFixedDelay(Runnable command,long initialDelay,long delay,TimeUnit unit) {}
简单举个例子:
public class ScheduledThreadPool {public static ScheduledExecutorService scheduledThreadPool;
static {
//初始化固定核心线程数的线程池
scheduledThreadPool = Executors.newScheduledThreadPool(5);
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 5; i++) {
final int temp = i;
scheduledThreadPool.scheduleWithFixedDelay(new Runnable() {
@Override
public void run() {
Thread.currentThread().setName(String.valueOf(temp));
try {
System.out.println("线程 " + Thread.currentThread().getName() + " 每隔10秒执行一次...");
Thread.sleep(500);// 1
System.out.println("线程 " + Thread.currentThread().getName() + " 结束...");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, 3, 10, TimeUnit.SECONDS);
}
System.out.println("===========Main Thread Over!=========");
}
}
这里演示了一种用法,即:线程池启动3S以后开始执行任务,每隔10S将这5个任务都执行一遍。如果将代码 1 位置处的500ms改成11s呢?这时候设置的每隔10s周期性执行就会失效,可以复制到自己本地运行看看现象,因此使用这类线程池还是要注意每个任务的处理耗时,合理评估间隔时间。感兴趣的还可以自己尝试使用scheduleAtFixedRate()的方法以及其他的使用方式。
再分享一个小Tip:可以考虑多线程池嵌套使用,合理利用Executors下默认线程池的特性。
CacheThreadPool
带有缓存的线程池,如果线程池长度超过处理需要,线程池可以灵活回收空闲线程,若无可回收线程,就创建新线程。
构造方法:
public static ExecutorService newCachedThreadPool() {return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
//可自定义线程工厂类构造
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
通过构造器可以看出,可以自定义线程的工厂类,而且跟其他几个默认的线程池区别在于阻塞队列的不同,也有个同样致命的缺点:Integer.MAX_VALUE,存在OOM的风险。
简单示例:
public class CachedThreadPool {public static ExecutorService cachedThreadPool;
static {
//初始化带有缓存的线程池
cachedThreadPool = Executors.newCachedThreadPool();
}
public static void main(String[] args) throws Exception {
for (int i = 0; i < 5; i++) {
final int temp = i;
cachedThreadPool.execute(new Runnable() {
@Override
public void run() {
Thread.currentThread().setName(String.valueOf(temp));
try {
System.out.println("线程 " + Thread.currentThread().getName() + " 开始...");
Thread.sleep(2000);
System.out.println("线程 " + Thread.currentThread().getName() + " 结束...");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
System.out.println("===========Main Thread Over!=========");
}
}
到这里一共介绍了4种线程池的构造和基础用法,但是这些默认构造在极端情况下都存在风险,这种使用Executors返回的线程池对象风险如下:
1.FixedThreadPool和SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,导致OOM2.CachedThreadPool和ScheduledThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,导致 OOM。
还是那句话,没有特殊需求,就老老实实的按照阿里规约里的来写:
new ThreadPoolExecutor(“核心线程数”, “最大线程数”, “空闲线程存活时间”, “时间单位”, “阻塞队列类型”);所有的参数都可以自定义,不过也不能设计的太洒脱,还是要根据业务场景合理设置,那怎么叫合理呢?简单!分两个场景介绍:
1.CPU(计算)密集型
假设CPU核心数为N,那么一般可以将核心线程数设置为N+1个,可以充分利用CPU的资源,且降低了CPU单个核心的上下文切换的频率。至于为什么要比CPU多设置一个线程,是因为防止某个时间点线程意外终止,此时多设置的这个线程就可以顶上了。
上demo证明一下这个理论对不对,不对的话,我就去找一下Doug Lea先生,跟他battle一下
public class ThreadPoolTest {// 初始一个线程池
private static ThreadPoolExecutor threadPool;
//计算线程池运行总时长
private static Vector<Long> threadPoolRunTime;
//单个线程运行市场
private static Vector<Long> singleThreadRunTime;
static {
// 用于获取当前硬件设备的CPU核心数
int coreNum = Runtime.getRuntime().availableProcessors();
System.out.println("当前设备CPU核心数:" + coreNum);
// 这里是重点,通过修改核心线程数和最大线程数,来观察任务执行耗时变化,即可证明前面阐述的理论
threadPool = new ThreadPoolExecutor(coreNum + 1, coreNum + 1, 10, TimeUnit.SECONDS, new ArrayBlockingQueue<Runnable>(1000), new ThreadPoolExecutor.DiscardPolicy());
threadPoolRunTime = new Vector<Long>();
singleThreadRunTime = new Vector<Long>();
}
public static void main(String[] args) throws Exception {
List<Future<?>> futureTaskList = new ArrayList<Future<?>>();
//运行总次数可以不修改
int testNum = 100;
for (int i = 0; i < testNum; i++) {
//提交一个计算密集型任务,并计算单个任务总耗时
Future<?> future = threadPool.submit(new TestCPU(singleThreadRunTime, threadPoolRunTime));
//提交一个IO密集型任务,并计算单个任务总耗时
//Future<?> future = threadPool.submit(new TestIO(singleThreadRunTime, threadPoolRunTime));
futureTaskList.add(future);
}
for (Future<?> future : futureTaskList) {
//获取线程执行结果
future.get(testNum, TimeUnit.SECONDS);
}
System.out.println("运行总耗时: " + getTime(threadPoolRunTime) / threadPoolRunTime.size() + " ms");
System.out.println("单个线程平均耗时: " + getTime(singleThreadRunTime) / singleThreadRunTime.size() + " ms");
threadPool.shutdown();
}
public static Long getTime(Vector<Long> list) {
long time = 0;
for (int i = 0; i < list.size(); i++) {
time = list.get(i) + time;
}
return time;
}
}
/**
* FileName: TestCPU
* Author: RollerRunning
* Date: 2020/12/16 9:08 PM
* Description: 计算密集型任务
*/
public class TestCPU implements Runnable {
private static List<Long> threadPoolRunTime;
private static List<Long> singleThreadRunTime;
private long startTime = 0;
public TestCPU(List<Long> singleThreadRunTime, List<Long> threadPoolRunTime) {
startTime = System.currentTimeMillis();
this.singleThreadRunTime = singleThreadRunTime;
this.threadPoolRunTime = threadPoolRunTime;
}
@Override
public void run() {
long start = System.currentTimeMillis();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//统计1~100000之间素数的总数
countPrimes(1, 100000);
long endTime = System.currentTimeMillis();
long threadPoolTime = endTime - startTime;
long threadTime = endTime - start;
threadPoolRunTime.add(threadPoolTime);
singleThreadRunTime.add(threadTime);
System.out.println("当前线" + Thread.currentThread().getName() + "程耗时:" + (endTime - start) + " ms");
}
/**
* 判断是否为素数
*/
public boolean isPrime(final int num) {
if (num <= 1) {
return false;
}
for (int i = 2; i <= Math.sqrt(num); i++) {
if (num % i == 0) {
return false;
}
}
return true;
}
/**
* 计算素数
*/
public int countPrimes(final int startNum, final int endNum) {
int count = 0;
for (int i = startNum; i <= endNum; i++) {
if (isPrime(i)) {
count++;
}
}
return count;
}
}
可以复制到自己本地跑一下这个测试类,根据自己本地CPU核心数设置不同的线程池核心数,能够发现执行结果有很大的不同,而效率最高的时候,就是当线程池中线程数与CPU核心数差不多相等的时候,会有差异,但不会太大。
2.I/O密集型
这类程序,由于系统大多数时间都是在处理IO交互,在处理IO的时间段内,是不会占用CPU时间片的,因此CPU有能力处理更多的线程。假设W:线程等待IO资源的时间;C:线程运行时间;P:目标CPU使用率。N:CPU数量,那么相对最优线程池大小Core = N P (1 + W/C)
还是创建一个IO密集型的任务,然后批量提交到我们的线程池中做测试:
/*** FileName: TestIO
* Author: RollerRunning
* Date: 2020/12/16 9:39 PM
* Description: IO密集型任务
*/
public class TestIO implements Runnable {
private static List<Long> threadPoolRunTime;
private static List<Long> singleThreadRunTime;
private long startTime = 0;
public TestIO(Vector<Long> singleThreadRunTime, Vector<Long> threadPoolRunTime) {
startTime = System.currentTimeMillis();
this.singleThreadRunTime = singleThreadRunTime;
this.threadPoolRunTime = threadPoolRunTime;
}
@Override
public void run() {
long start = System.currentTimeMillis();
try {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 执行IO操作
readFile();
} catch (IOException e) {
e.printStackTrace();
}
long end = System.currentTimeMillis();
threadPoolRunTime.add(end - startTime);
singleThreadRunTime.add(end - start);
System.out.println("当前线程" + Thread.currentThread().getName() + "耗时:" + (end - start) + " ms");
}
/**
* IO操作,读取一个本地文件
*/
public void readFile() throws IOException {
//自己随便创建一个txt文件用来测试
File sourceFile = new File("/Users/RollerRunning/Documents/test/IO.txt");
BufferedReader input = new BufferedReader(new FileReader(sourceFile));
//按行读取
String line = null;
while ((line = input.readLine()) != null) {
System.out.println(line);
}
input.close();
}
}
还是百看不如一次自己运行,拷贝一下,自己运行感受一下。这些demo书里都能找到,也可以百度一下其他的博客写的一些测试案例,都大差不差。
WorkStealingThreadPool
还是先来看看这个线程池的构造方法:
public static ExecutorService newWorkStealingPool(int parallelism) {return new ForkJoinPool
(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
public static ExecutorService newWorkStealingPool() {
return new ForkJoinPool
(Runtime.getRuntime().availableProcessors(),
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null, true);
}
这个线程池是JDK1.8以后才新增的基于ForkJoinPool扩展来的,通过构造方法就能看出来,在它的内部是通过new ForkJoinPool()来实现的,而前面四种是通过new ThreadPoolExecutor()再搭配不同的阻塞队列实现的,更细节的东西就不多说了,不是一两篇能写完的。
那么这个新增的线程池有啥优点呢?优点就是它内部线程会steal work啊,小时候有个梗就是吃零食比谁吃得快,谁先吃完可以抢别人的吃,这个线程池也是这个思想,谁的任务执行完了,就可以去帮助其他线程执行任务了,不过这么说不够准确,先看一张图,然后再详细解释


图一是前四种线程池的一个大概的任务分配模型,而图二则是WorkStealingThreadPool线程池的任务分配模式,每一个线程都有一个自己的任务等待队列,也就是自己的零食,当自己的任务执行完了,允许从其他线程的任务队列中获取任务并协助执行。这样就可以提高线程的可用性,提升线程池整体效率。
最后来个简单的示例:
public class WorkStealThreadPool {public static ExecutorService workStealThreadPool;
static {
//初始化无锁线程池
workStealThreadPool = Executors.newWorkStealingPool();
}
public static void main(String[] args) throws Exception {
int core = Runtime.getRuntime().availableProcessors();
System.out.println("当前设备CPU核心数为:" + core);
for (int i = 0; i < 50; i++) {
FutureTask<?> futureTask = new FutureTask<>(new Callable<String>() {
@Override
public String call() {
try {
System.out.println("线程 " + Thread.currentThread().getName() + " 开始...");
Thread.sleep(1000);
System.out.println("线程 " + Thread.currentThread().getName() + " 结束...");
} catch (InterruptedException e) {
e.printStackTrace();
}
return "当前线程名称为:"+Thread.currentThread().getName();
}
});
workStealThreadPool.submit(new Thread(futureTask));
//System.out.println(futureTask.get());
}
System.out.println("===========Main Thread Over!=========");
}
}
点赞关注不迷路,再次感谢!
以上是 【Java】超大份线程池,干杯,兄弟!陆 的全部内容, 来源链接: utcz.com/a/87222.html