使用 loadTextEx载入csv格式文件时报错:中文列名不存在
导入列名为中文的tick数据时,发生以下错误,求各位前辈指点
dbDate = database("", VALUE, 2011.01.01..2020.12.31)
dbSymbol=database("", HASH, [DATE,10])
db = database("dfs://level2_2", COMPO, [dbDate, dbSymbol])
dataDir="D:/data/jsydata_unrar/tick/20130107/"
def importTxtFiles(dataDir, db){
dataFiles = exec filename from files(dataDir)for(f in dataFiles){
loadTextEx(db, `quotes,`证券代码`时间, dataDir + f)
}
}
importTxtFiles(dataDir, db);
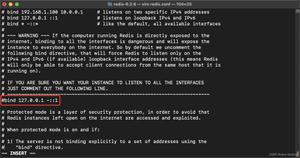
importTxtFiles(dataDir, db) => importTxtFiles: loadTextEx(db, "quotes", ["证券代码","时间"], dataDir + f) => The partition column [证券代码] doesn't exist.
以下是csv文件字段名:
回答
这个应该是csv文件的编码不是utf8造成的,DolphinDB支持utf8,可以在GUI中执行
extractTextSchema(fileName)确认一下是否显示乱码。若显示乱码,csv就不是utf8。
若只是列名不是utf8,可以按下面例子转换:
schema1=extractTextSchema(fileName)update schema1 set name=convertEncode(name,"gbk","utf-8")
t1=ploadText(fileName,,schema1)
若值也有中文,可以参考下面教程6.1节进行转换:
https://gitee.com/dolphindb/T...
以上是 使用 loadTextEx载入csv格式文件时报错:中文列名不存在 的全部内容, 来源链接: utcz.com/a/69630.html