python3 分布式爬虫
转载与https://www.jianshu.com/p/ec3dfaec3c9b?utm_source=tuicool&utm_medium=referral
背景
部门(东方IC、图虫)业务驱动,需要搜集大量图片资源,做数据分析,以及正版图片维权。前期主要用node做爬虫(业务比较简单,对node比较熟悉)。随着业务需求的变化,大规模爬虫遇到各种问题。python爬虫具有先天优势,社区资源比较齐全,各种框架也完美支持。爬虫性能也得到极大提升。本次分享从基础知识入手,涉及python 的两大爬虫框架pyspider、scrapy,并基于scrapy、scrapy-redis 做了分布式爬虫的介绍(直接粘贴的ppt截图)会涉及 redis、mongodb等相关知识。
对于反防盗链(自动登录、自动注册... 以及常见策略)、代理、爬虫快照、对象资源入TOS 未做过多介绍。这个双月我们正在做爬虫平台的可视化,可配置化,流程化。
一、前沿
1.1 爬虫是什么?
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
1.2 为什么是Python?
简单易学:简单到没有学习过任何编程语言的人稍微看下资料就能编写出爬虫 解释型编程语言:编写完后可以直接执行,无须编译
代码重用性高:可以直接把包含某个功能的模块带入其它程序中使用
跨平台性:几乎所有的python程序都可以不加修改的运行在不同的操作系统
二、基础知识
2.1 Robots协议
Robots 协议也被称作爬虫协议、机器人协议,它的全名叫做网络爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。它通常是一个叫做 robots.txt 的文本文件,放在网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检查下这个站点根目录下是否存在 robots.txt 文件,如果存在,搜索爬虫会根据其中定义的爬取范围来爬取。如果没有找到这个文件,那么搜索爬虫便会访问所有可直接访问的页面。
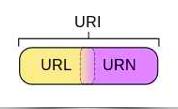
2.2 URL 的含义
概念:
URL(协议(服务方式) + IP地址(包括端口号) + 具体地址),即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。互联网上的每个文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它。爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据。
相关:
URI = Universal Resource Identifier 统一资源标志符
URL = Universal Resource Locator 统一资源定位符
URN = Universal Resource Name 统一资源名称
image
2.3 浏览网页的过程
在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.baidu.com/ ,我们会看到几张的图片以及百度搜索框,这个过程其实就是用户输入网址之后,经过 DNS 服务器,找到服务器主机,向服务器发出一个请求,服务器经过解析之后,发送给用户的浏览器 HTML、JS、CSS 等文件,浏览器解析出来,用户便可以看到形形色色的图片了,其实就是一次http请求的过程
2.4 代理基本原理
2.4.1基本原理
在本机和服务器之间搭建了一个桥,此时本机不是直接向 Web 服务器发起请求,而是向代理服务器发出请求,这个过程 Web 服务器识别出的真实的 IP 就不再是我们本机的 IP 了,就成功实现了 IP 伪装,这就是代理的基本原理
2.4.2代理的作用
1、突破自身 IP 访问限制,访问一些平时不能访问的站点
2、访问一些单位或团体内部资源
3、隐藏真实 IP
2.4.3爬虫代理
在爬取过程中可能遇到同一个 IP 访问过于频繁的问题,网站就会让我们输入验证码或登录或者直接封锁 IP,这样会给爬取带来极大的不便。让服务器误以为是代理服务器的在请求自己。这样在爬取过程中通过不断更换代理,就不会被封锁,可以达到很好的爬取效果
2.4.4代理分类
FTP 代理服务器、主要用于访问 FTP 服务器
HTTP 代理服务器,主要用于访问网页
SSL/TLS 代理,主要用于访问加密网站
2.4.5常见代理设置
免费代理
付费代理
image
三、爬虫入门

image
3.1 常用爬虫lib
请求库:requests、selenium(自动化测试工具)+ChromeDrive(chrome 驱动器)、PhantomJS(无界面浏览器)
解析库: LXML(html、xml、Xpath方式)、BeautifulSoup(html、xml)、PyQuery(支持css选择器)、Tesserocr(光学字符识别,验证码)
数据库: mongo、mysql、redis
存储库: pymysql、pymongo、redispy、RedisDump(Redis 数据导入导出的工具)
web库: Flask(轻量级的 Web 服务程序)、Django
其它工具: Charles(网络抓包工具)
3.2 一个入门栗子

image

image
3.3 复杂一点的栗子
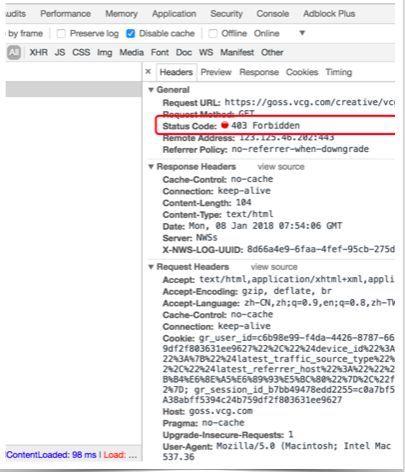
问题:“防盗链”
防盗链,服务器会识别 headers 中的 referer 是不是它自己,如果不是,有的服务器不会响应,所以我们还可以在 headers 中加入 referer等信息
反“防盗链”
1、完全模拟浏览器的工作
2、构造cookie信息
3、设置header信息
4、Proxy 代理设置
其它策略
Timeout设置
3.4 动态渲染页面抓取
Splash 是一个 JavaScript 渲染服务,是一个带有 HTTP API 的轻量级浏览器,同时它对接了 Python 中的 Twisted 和 QT 库,利用它我们同样可以实现动态渲染页面的抓取。
异步方式处理多个网页渲染过程
获取渲染后的页面的源代码或截图
通过关闭图片渲染或者使用 Adblock 规则来加快页面渲染速度
可执行特定的 JavaScript 脚本
可通过 Lua 脚本来控制页面渲染过程
获取渲染的详细过程并通过 HAR(HTTP Archive)格式呈现
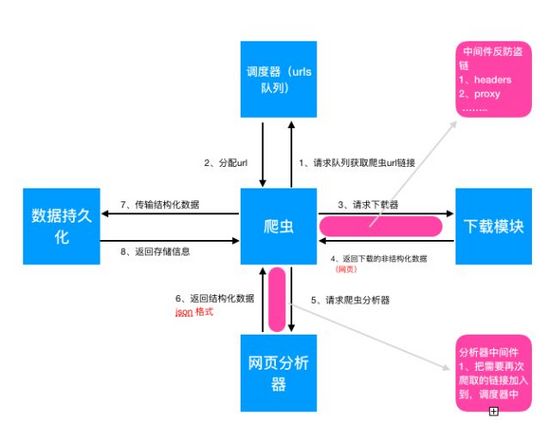
3.5 爬虫完整流程
image
四、爬虫框架
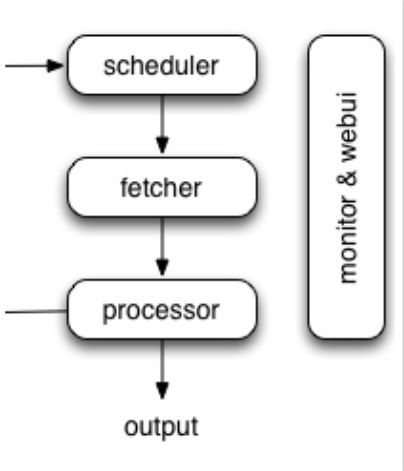
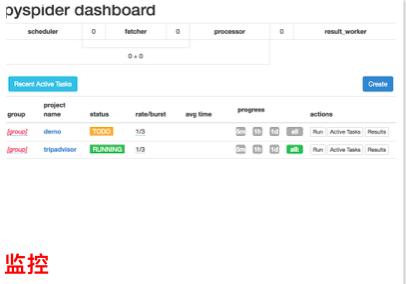
4.1 PySpider简介
一个国人编写的强大的网络爬虫系统并带有强大的WebUI。采用Python语言编写,分布式架构,支持多种数据库后端,强大的WebUI支持脚本编辑器,任务监视器,项目管理器以及结果查看器
image
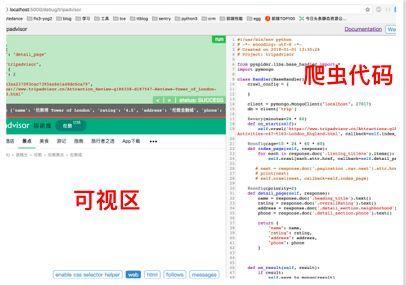
4.2 PySpider特性
1、python 脚本控制,可以用任何你喜欢的html解析包(内置 pyquery)
2、WEB 界面编写调试脚本,起停脚本,监控执行状态,查看活动历史,获取结果产出
3、数据存储支持MySQL, MongoDB, Redis, SQLite, Elasticsearch; PostgreSQL 及 SQLAlchemy
4、队列服务支持RabbitMQ, Beanstalk, Redis 和 Kombu
5、支持抓取 JavaScript 的页面
6、组件可替换,支持单机/分布式部署,支持 Docker 部署
7、强大的调度控制,支持超时重爬及优先级设置
8、支持python2&3

image
image
image
4.3 Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。

image
4.4 Scrapy运行流程
1、调度器(Scheduler)从待下载链接中取出一个链接(URL)
2、调度器启动采集模块Spiders模块
3、采集模块把URL传给下载器(Downloader),下载器把资源下载下来
4、提取目标数据,抽取出目标对象(Item),则交给实体管道(item pipeline)进行进一步的处理;比如存入数据库、文本
5、若是解析出的是链接(URL),则把URL插入到待爬取队列当中
五、scrapy框架
5.1 Scrapy基本使用
创建项目:scrapy startproject tutorial
创建spider:scrapy genspider quotes quotes.toscrapy.com
运行项目:scrapy crawl dmoz
交互调试:scrapy shell quotes.toscrape.com
保存数据(多种格式):scrapy crawl quotes -o quoqes.json

image
5.2 scrapy全局指令
startproject:创建项目
genspider:创建爬虫
settings:获取Scrapy的设定
runspider:在未创建项目的情况下,运行一个编写在Python文件中的spider
shell:以给定的URL(如果给出)或者空(没有给出URL)启动Scrapy shell
fetch:使用Scrapy下载器(downloader)下载给定的URL,并将获取到的内容送到标准输出
view:在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现
Version:输出Scrapy版本
5.3 scrapy项目指令
crawl:使用spider进行爬取
check:检查项目是否有错
list: 列出当前项目中所有可用的spider,每行输出一个spider
edit:仅仅是提供一个快捷方式。开发者可以自由选择其他工具或者IDE来编写调试spiderparse
parse:获取给定的URL并使用相应的spider分析处理
bench:运行benchmark测试
5.4 scrapy选择器
BeautifulSoup 是在程序员间非常流行的网页分析库,它基于HTML代码的结构来构造一个Python对象, 对不良标记的处理也非常合理,但它有一个缺点:慢。
lxml 是一个基于 ElementTree (不是Python标准库的一部分)的python化的XML解析库(也可以解析HTML)。
Scrapy提取数据有自己的一套机制。它们被称作选择器(seletors),因为他们通过特定的 XPath 或者 CSS 表达式来“选择” HTML文件中的某个部分。
XPath 是一门用来在XML文件中选择节点的语言,也可以用在HTML上。
CSS 是一门将HTML文档样式化的语言。选择器由它定义,并与特定的HTML元素的样式相关连。
Scrapy选择器构建于 lxml 库之上,这意味着它们在速度和解析准确性上非常相似。

image
5.5 spiders
Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用 startrequests() 来获取的。 startrequests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request 。
在回调函数内分析返回的(网页)内容,返回 Item 对象、dict、 Request 或者一个包括三者的可迭代容器。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。
在回调函数内,您可以使用 选择器(Selectors) (您也可以使用BeautifulSoup, lxml 或者您想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline 处理)或使用 Feed exports 存入到文件中。
属性
name: 定义spider名字的字符串(string)
allowed_domains: 包含了 spider 允许爬取的域名(domain)列表(list)
start_urls: URL列表。当没有制定特定的URL时,spider将从该列表中开始进行爬取
custom_settings: 该设置是一个dict.当启动spider时,该设置将会覆盖项目级的设置. 由于设置必须在初始化(instantiation)前被更新,所以该属性 必须定义为class属性
crawler: 该属性在初始化class后,由类方法 from_crawler() 设置, 并且链接了本spider实例对应的 Crawler 对象
settings: crawler 的配置管理器,扩展(extensions)和中间件(middlewares)使用它用来访问 Scrapy 的配置
logger: self.logger.info('日志:%s', response.status)
方法
from_crawler: 如果存在,则调用此类方法以从 Crawler 创建 pipeline 实例。它必须返回一个新的pipeline实例。 Crawler 对象提供对所有 Scrapy 核心组件(如settings 和 signals)的访问; 它是 pipeline 访问它们并将其功能挂钩到Scrapy中的一种方法
start_requests: 该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个Request
make_requests_from_url: 该方法接受一个URL并返回用于爬取的 Request 对象
parse: 当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法
log: 使用 scrapy.log.msg() 方法记录(log)message
closed: 当spider关闭时,该函数被调用
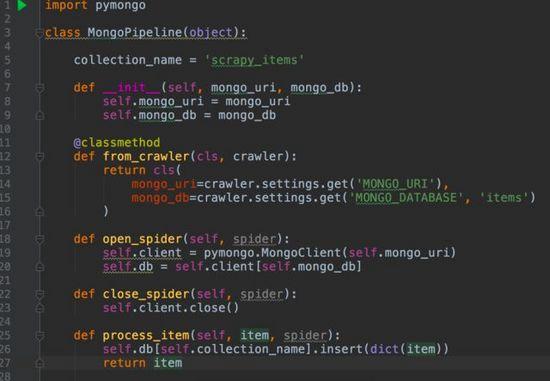
5.6 Item Pipeline
当 Item 在 Spider 中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
1、清理HTML数据
2、验证爬取的数据(检查item包含某些字段)
3、查重(并丢弃)
4、将爬取结果保存到数据库中
方法
process_item(self, item, spider): 每个item pipeline组件都需要调用该方法,这个方法必须返回一个具有数据的dict,或是 Item (或任何继承类)对象, 或是抛出 DropItem 异常,被丢弃的item将不会被之后的pipeline组件所处理。
open_spider: 当spider被开启时,这个方法被调用。
close_spider: 当spider被关闭时,这个方法被调用
from_crawler: 获取setting 配置信息
例子:数据持久化到mongo
image
5.7 Downloader Middleware
下载器中间件是介于 Scrapy 的 request/response 处理的钩子框架。 是用于全局修改Scrapy request 和 response 的一个轻量、底层的系统。
激活
要激活下载器中间件组件,将其加入到DOWNLOADER_MIDDLEWARES 设置中。 该设置是一个字典(dict),键为中间件类的路径,值为其中间件的顺序(order)。
方法
1、process_request(request, spider): 当每个request通过下载中间件时,该方法被调用
2、processresponse(request, response, spider): processrequest() 必须返回以下之一: 返回一个 Response 对象、 返回一个 Request 对象或raise一个 IgnoreRequest 异常。如果其返回一个 Response (可以与传入的response相同,也可以是全新的对象), 该response会被在链中的其他中间件的 process_response() 方法处理。
3、processexception(request, exception, spider): 当下载处理器(download handler)或 processrequest() (下载中间件)抛出异常(包括 IgnoreRequest 异常)时, Scrapy调用 process_exception()
例子:添加代理

image
六、scrapy 搭建项目
6.1 爬虫思路

image
6.2 实际项目分析
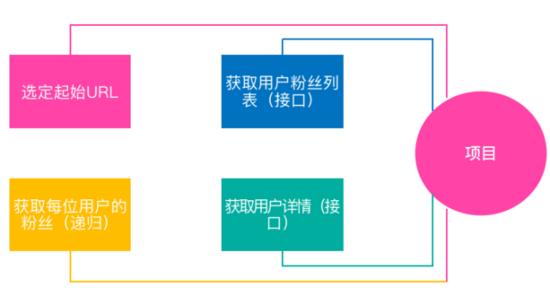
image
起始页

image
项目结构

image
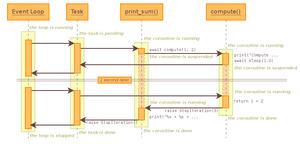
七、分布式爬虫
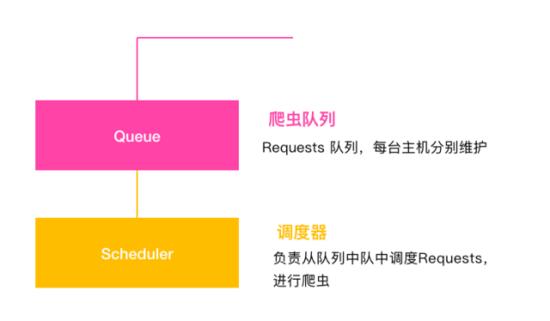
7.1 单主机爬虫架构
本机维护一个爬虫队列,scheduler 进行调度
Q:多台主机协作的关键是什么?
A:共享爬虫队列

image
单主机爬虫架构
image
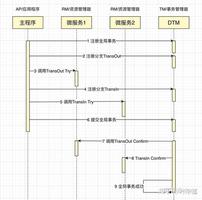
7.2 分布式爬虫架构

image
分布式爬虫架构

image
7.3 问题
Q1:队列怎么选?
A1: Redis队列
Redis 非关系型数据库,key-value形式存储,结构灵活
是内存中的数据结构存储系统,处理速度快,性能好
提供队列、集合等多种存储结构,方便队列维护
Q2:怎么去重?
A2:Redis集合
Redis 提供集合数据结构,在redis集合中存储每个request的指纹
在向redis集合中存储request指纹的时候,先验证指纹是否存在?
[如果存在]:则不添加request到队列
[不存在]:则将request加入队列,并将指纹加入集合
Q3:怎样防止中断?
A3:启动判断
在每台从机 scrapy 启动时 都会首先判断当前 redis reqeust队列是否为空
[不为空]:从队列中取得下一个 request ,进行执行爬虫
[空]:重新开始爬取,第一台从机执行爬取向队列中添加request
Q4:怎样实现该架构?
A4:Scrapy-Redis
scrapy是Python的一个非常好用的爬虫框架,功能非常强大,但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求的并发数),这时候分布式爬虫的优势就显现出来,人多力量大。而scrapy-Redis就是结合了分布式数据库redis,重写了scrapy一些比较关键的代码(scrapy的调度器、队列等组件),将scrapy变成一个可以在多个主机上同时运行的分布式爬虫。
github地址: https://github.com/rmax/scrapy-redis
7.4 源码解读
阅读源码前:需要了解 scrapy 的运行原理,否则并没什么用。
scrapy-redis 工程的主体还是 redis 和 scrapy 两个库,将两个库的核心功能结合,实现分布式。

image
1 connection.py
负责根据setting中配置实例化redis连接。被dupefilter和scheduler调用,总之涉及到redis存取的都要使用到这个模块

image
2 dupefilter.py
通过继承 BaseDupeFilter 重写他的方法,实现了基于redis的 request 判重。scrapy-redis使用 redis的一个 set 中插入 fingerprint(不同spider的key不同)
spider名字+DupeFilter的key就是为了在不同主机上的不同爬虫实例,只要属于同一种spider,就会访问到同一个set,而这个set就是他们的url判重池 。
DupeFilter 判重会在 scheduler 类中用到,每一个request在进入调度之前都要进行判重,如果重复就不需要参加调度,直接舍弃就好了

image
3 picklecompat.py
loads 和 dumps 两个函数,其实就是实现了一个 serializer,因为 redis 数据库不能存储复杂对象(value部分只能是字符串,字符串列表,字符串集合和hash,key部分只能是字符串),所以存储前需要先序列化成文本才行
这个 serializer 主要用于 scheduler 存 reuqest 对象。
为什么不用json格式?(item pipeline 的串行化默认用的就是 json)
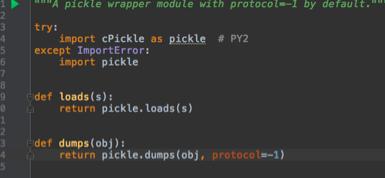
image
4 pipelines.py
pipeline 文件实现了一个 item pipieline 类,和 scrapy 的 item pipeline 是同一个对象,从settings中获取我们配置的REDISITEMSKEY作为key,把item串行化之后存入redis数据库对应的value中(这个value是list,我们的每个item是这个list中的一个结点),这个pipeline把提取出的item存起来,主要是为了方便我们延后处理数据。

image
5 queue.py
这里实现了三种方式的 Queue
SpiderQueue(队列):先进先出
SpiderStack(栈):先进后出
SpiderPriorityQueue(优先级队列)
这些容器类都会作为scheduler调度request的容器,scheduler在每个主机上都会实例化一个,并且和spider一一对应,所以分布式运行时会有一个spider的多个实例和一个scheduler的多个实例存在于不同的主机上,但是,因为scheduler都是用相同的容器,而这些容器都连接同一个redis服务器,又都使用spider名加queue来作为key读写数据,所以不同主机上的不同爬虫实例公用一个request调度池,实现了分布式爬虫之间的统一调度。

image
6 scheduler.py
重写了scheduler类,代替scrapy.core.scheduler 的原有调度器,对原有调度器的逻辑没有很大的改变,主要是使用了redis作为数据存储的媒介,以达到各个爬虫之间的统一调度。scheduler负责调度各个spider的request请求,scheduler初始化时,通过settings文件读取queue和dupefilters的类型,配置queue和dupefilters使用的key。每当一个request要被调度时,enqueuerequest被调用,scheduler使用dupefilters来判断这个url是否重复,如果不重复,就添加到queue的容器中(可以在settings中配置)。当调度完成时,nextrequest被调用,scheduler就通过queue容器的接口,取出一个request,把他发送给相应的spider,让spider进行爬取工作。
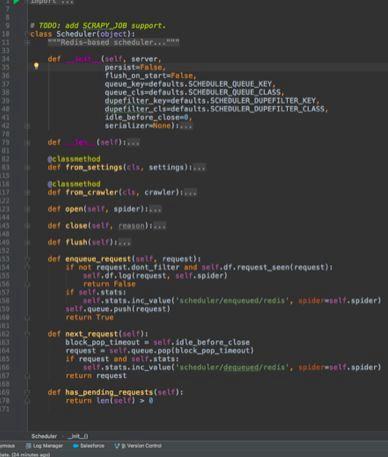
image
7 spider.py
设计的这个spider从redis中读取要爬的url,然后执行爬取,若爬取过程中返回更多的url,那么继续进行直至所有的request完成。之后继续从redis中读取url,循环这个过程。
分析:在这个spider中通过connect signals.spideridle信号实现对crawler状态的监视。当idle时,返回新的makerequestsfromurl(url)给引擎,进而交给调度器调度。

python 学习交流群:125240963

以上是 python3 分布式爬虫 的全部内容, 来源链接: utcz.com/a/52284.html