回归分析中R方和调整R方的区别
作者|ANIRUDDHA BHANDARI
编译|VK
来源|Analytics Vidhya
概述
- 理解R方和调整R方的概念
- 了解R方和调整R方之间的关键区别
介绍
当我开始我的数据科学之旅时,我探索的第一个算法是线性回归。
在理解了线性回归的概念和算法的工作原理之后,我非常兴奋地使用它并在问题陈述中做出预测。我相信你们大多数人也会这么做的。但是一旦我们建立了模型,下一步是什么呢?
接下来是棘手的部分。一旦我们建立了模型,下一步就是评估它的性能。毋庸置疑,模型评价是一项关键性的任务,它凸显了模型的不足。
选择最合适的评价指标是一个关键的任务。而且,我遇到了两个重要的指标:除了MAE/MSE/RMSE,有R方和调整R方。这两者有什么区别?我应该用哪一个?
R方和调整R方是两个评估指标,对于任何一个数据科学的追求者来说,这两个指标可能会让他们感到困惑。
它们对评估回归问题都非常重要,我们将深入了解和比较它们。它们各有利弊,我们将在本文中详细讨论。
目录
- 残差平方和
- 了解R方统计量
- 关于R方统计量的问题
- 调整R方统计量
残差平方和
为了清楚地理解这些概念,我们将讨论一个简单的回归问题。在这里,我们试图根据“花在学习上的时间”来预测“获得的分数”。学习时间是我们的自变量,考试成绩是我们的因变量或目标变量。
我们可以绘制一个简单的回归图来可视化这些数据。
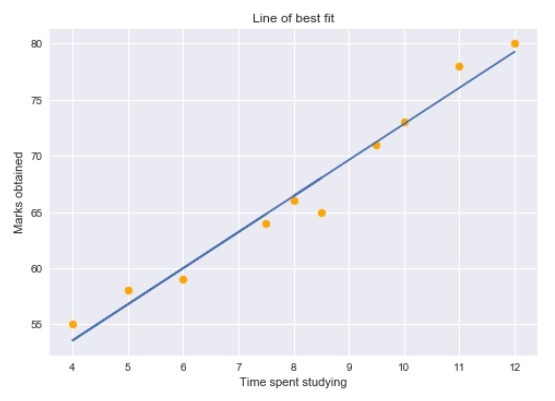
黄点代表数据点,蓝线是我们预测的回归线。如你所见,我们的回归模型并不能完美地预测所有的数据点。
那么我们如何利用这些数据来评估回归线的预测呢?我们可以从确定数据点的残差开始。
![]()
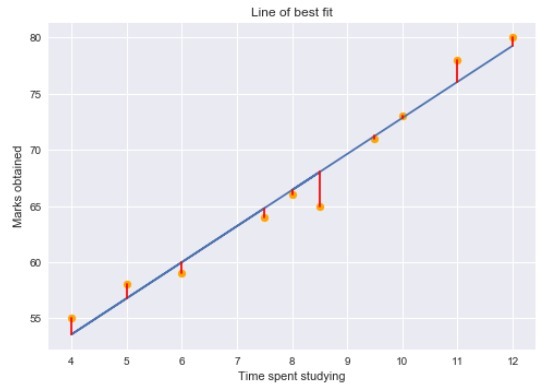
残差图告诉我们回归模型是否适合数据。残差的平方实际上是回归模型优化的目标函数。
利用残差值,我们可以确定残差的平方和,也称为残差平方和或RSS。。
![]()
RSS值越低,模型预测值越好。或者我们可以这样说——如果回归线使RSS值最小化,那么回归线就是最佳拟合线。
但这其中有一个缺陷——RSS是一个尺度变量统计。由于RSS是实际值和预测值的平方差之和,因此该值取决于目标变量的大小。
例子:
假设你的目标变量是销售产品所产生的收入。残差取决于目标的大小。如果收入大小以“1百卢比”为单位计算的话(即目标可能是1、2、3等),那么我们可能会得到0.54左右的RSS(假设)。
但是如果收入目标变量以“卢比”为单位(即目标值为100、200、300等),那么我们可能会得到一个更大的RSS,即5400。即使数据没有变化,RSS的值也会随着目标的大小而变化。这使得很难判断什么是好的RSS值。
那么,我们能想出一个更好的尺度不变的统计量吗?这就是R方出现的地方。
R方统计量
这可能看起来有点复杂,所以让我在这里把它分解。为了确定模型解释的目标变化比例,我们需要首先确定以下内容-
平方和(TSS)
![]()
TSS或总平方和给出了Y的总变化量。我们可以看到它与Y的方差非常相似。虽然方差是实际值和数据点之间差的平方和的平均值,TSS是平方和的总和。
既然我们知道了目标变量的总变化量,我们如何确定模型解释的这种变化的比例?我们回到RSS。
残差平方和(RSS)
正如我们前面讨论的,RSS给出了实际点到回归线距离的总平方。残差,我们可以说是回归线没有捕捉到的距离。
因此,RSS作为一个整体给了我们目标变量中没有被我们的模型解释的变化。
R方
现在,如果TSS给出Y的总变化量,RSS给出不被X解释的Y的变化量,那么TSS-RSS给出了Y的变化,并且这部分变化是由我们的模型解释的!我们可以简单地再除以TSS,得到由模型解释的Y中的变化比例。这是我们的R方统计量!
因此,R方给出了目标变量的可变性程度,由模型或自变量解释。如果该值为0.7,则意味着自变量解释了目标变量中70%的变化。
R方始终介于0和1之间。R方越高,说明模型解释的变化越多,反之亦然。
如果RSS值很低,这意味着回归线非常接近实际点。这意味着自变量解释了目标变量的大部分变化。在这种情况下,我们会有一个非常高的R方值。
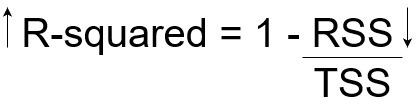
相反,如果RSS值非常高,则意味着回归线远离实际点。因此,自变量无法解释目标变量中的大部分变量。这会给我们一个很低的R方值。
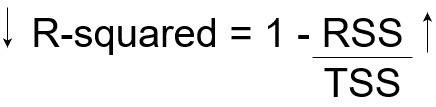
所以,这就解释了为什么R方值给出了目标变量的变化量。
关于R方统计量的问题
R方统计并不完美。事实上,它有一个主要缺陷。不管我们在回归模型中添加多少变量,它的值永远不会减少。
也就是说,即使我们在数据中添加冗余变量,R方的值也不会减少。它要么保持不变,要么随着新的自变量的增加而增加。
这显然没有意义,因为有些自变量在确定目标变量时可能没有用处。调整R方处理了这个问题。
调整R方统计量
调整R方考虑了用于预测目标变量的自变量数量。在这样做的时候,我们可以确定在模型中添加新的变量是否会增加模型的拟合度。
让我们看看调整R方的公式,以便更好地理解它的工作原理。
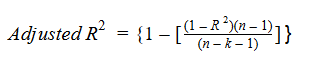
在这里,
- n表示数据集中的数据点数量
- k表示自变量的个数
- R代表模型确定的R方值
因此,如果R方在增加一个新的自变量时没有显著增加,那么调整R方值实际上会减少。
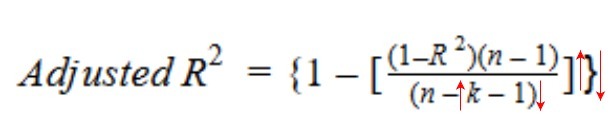
另一方面,如果增加新的自变量,我们看到R方值显著增加,那么调整R方值也会增加。
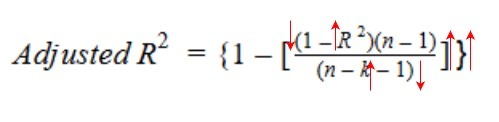
如果我们在模型中加入一个随机自变量,我们可以看到R方值和调整R方值之间的差异。

如你所见,添加随机独立变量无助于解释目标变量的变化。我们的R方值保持不变。因此,给我们一个错误的指示,这个变量可能有助于预测输出。然而,调整R方值下降,表明这个新变量实际上没有捕捉到目标变量的趋势。
显然,当回归模型中存在多个变量时,最好使用调整R方。这将使我们能够比较具有不同数量独立变量的模型。
结尾
在这篇文章中,我们研究了R方统计值是什么,它在哪里不稳定。我们还研究了调整R方。
希望这能让你更好地理解事情。现在,你可以谨慎地确定哪些自变量有助于预测回归问题的输出。
原文链接:https://www.analyticsvidhya.c...
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
以上是 回归分析中R方和调整R方的区别 的全部内容, 来源链接: utcz.com/a/48824.html