“既生 ExecutorService, 何生 CompletionService?”
前言
在 我会手动创建线程,为什么要使用线程池? 中详细的介绍了 ExecutorService,可以将整块任务拆分做简单的并行处理;
在 不会用Java Future,我怀疑你泡茶没我快 中又详细的介绍了 Future 的使用,填补了 Runnable 不能获取线程执行结果的空缺
将二者结合起来使用看似要一招吃天下了(Java有并发,并发之大,一口吃不下), but ~~ 是我太天真

ExecutorService VS CompletionService
假设我们有 4 个任务(A, B, C, D)用来执行复杂的计算,每个任务的执行时间随着输入参数的不同而不同,如果将任务提交到 ExecutorService, 相信你已经可以“信手拈来”
ExecutorService executorService = Executors.newFixedThreadPool(4);List<Future> futures = new ArrayList<Future<Integer>>();
futures.add(executorService.submit(A));
futures.add(executorService.submit(B));
futures.add(executorService.submit(C));
futures.add(executorService.submit(D));
// 遍历 Future list,通过 get() 方法获取每个 future 结果
for (Future future:futures) {
Integer result = future.get();
// 其他业务逻辑
}
先直入主题,用 CompletionService 实现同样的场景
ExecutorService executorService = Executors.newFixedThreadPool(4);// ExecutorCompletionService 是 CompletionService 唯一实现类
CompletionService executorCompletionService= new ExecutorCompletionService<>(executorService );
List<Future> futures = new ArrayList<Future<Integer>>();
futures.add(executorCompletionService.submit(A));
futures.add(executorCompletionService.submit(B));
futures.add(executorCompletionService.submit(C));
futures.add(executorCompletionService.submit(D));
// 遍历 Future list,通过 get() 方法获取每个 future 结果
for (int i=0; i<futures.size(); i++) {
Integer result = executorCompletionService.take().get();
// 其他业务逻辑
}
两种方式在代码实现上几乎一毛一样,我们曾经说过 JDK 中不会重复造轮子,如果要造一个新轮子,必定是原有的轮子在某些场景的使用上有致命缺陷

既然新轮子出来了,二者到底有啥不同呢? 在 搞定 CompletableFuture,并发异步编程和编写串行程序还有什么区别? 文中,我们提到了 Future get() 方法的致命缺陷:
先来看第一种实现方式,假设任务 A 由于参数原因,执行时间相对任务 B,C,D 都要长很多,但是按照程序的执行顺序,程序在 get() 任务 A 的执行结果会阻塞在那里,导致任务 B,C,D 的后续任务没办法执行。又因为每个任务执行时间是不固定的,所以无论怎样调整将任务放到 List 的顺序,都不合适,这就是致命弊端
新轮子自然要解决这个问题,它的设计理念就是哪个任务先执行完成,get() 方法就会获取到相应的任务结果,这么做的好处是什么呢?来看个图你就瞬间理解了
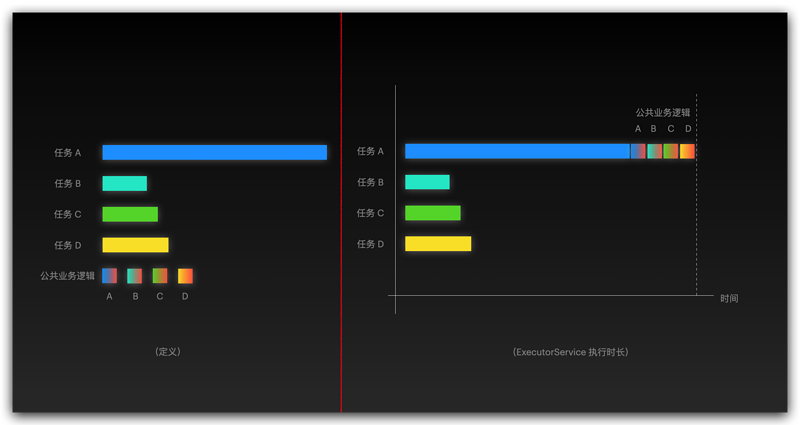
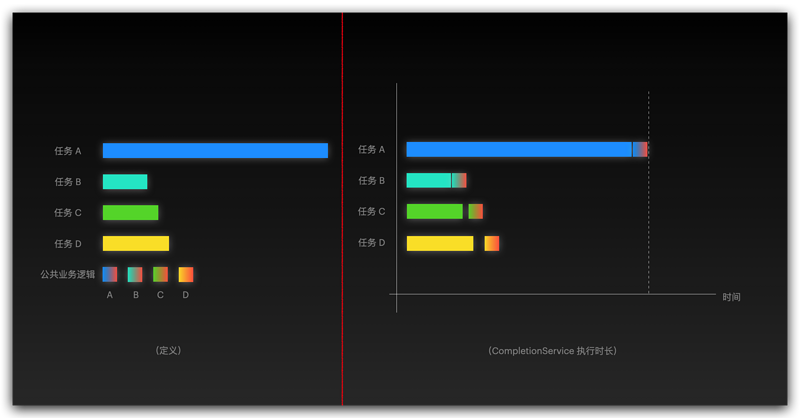
两张图一对比,执行时长高下立判了,在当今高并发的时代,这点时间差,在吞吐量上起到的效果可能不是一点半点了

远看CompletionService 轮廓
如果你使用过消息队列,你应该秒懂我要说什么了,CompletionService 实现原理很简单
用人话解释一下上面的抽象概念我只能再画一张图了
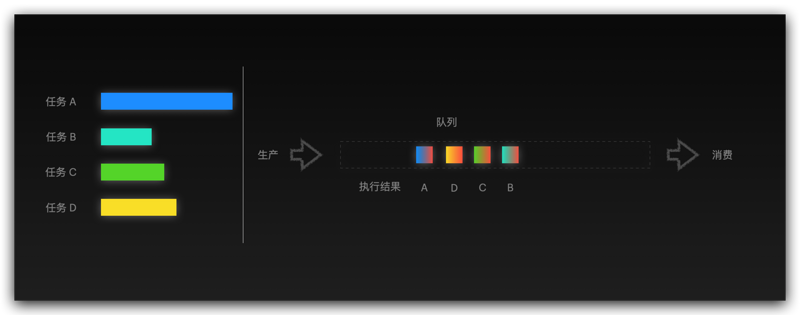
说白了,哪个任务执行的完,就直接将执行结果放到队列中,这样消费者拿到的结果自然就是最早拿到的那个了
从上图中看到,有任务,有结果队列,那 CompletionService 自然也要围绕着几个关键字做文章了
- 既然是异步任务,那自然可能用到 Runnable 或 Callable
- 既然能获取到结果,自然也会用到 Future 了
带着这些线索,我们走进 CompletionService 源码看一看
近看 CompletionService 源码
CompletionService 是一个接口,它简单的只有 5 个方法:
Future<V> submit(Callable<V> task);Future<V> submit(Runnable task, V result);
Future<V> take() throws InterruptedException;
Future<V> poll();
Future<V> poll(long timeout, TimeUnit unit) throws InterruptedException;
关于 2 个 submit 方法, 我在 不会用Java Future,我怀疑你泡茶没我快 文章中做了非常详细的分析以及案例使用说明,这里不再过多赘述

另外 3 个方法都是从阻塞队列中获取并移除阻塞队列第一个元素,只不过他们的功能略有不同
- Take: 如果队列为空,那么调用 take() 方法的线程会被阻塞
- Poll: 如果队列为空,那么调用 poll() 方法的线程会返回 null
- Poll-timeout: 以超时的方式获取并移除阻塞队列中的第一个元素,如果超时时间到,队列还是空,那么该方法会返回 null
所以说,按大类划分上面5个方法,其实就是两个功能
- 提交异步任务 (submit)
- 从队列中拿取并移除第一个元素 (take/poll)
CompletionService 只是接口,ExecutorCompletionService 是该接口的唯一实现类
ExecutorCompletionService 源码分析
先来看一下类结构, 实现类里面并没有多少内容
<fancybox>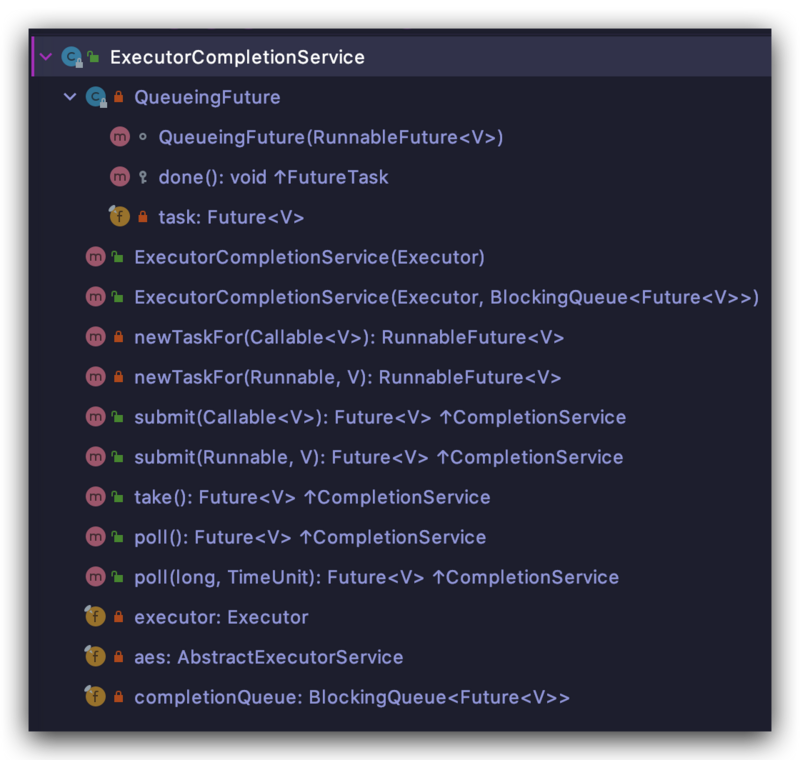 </fancybox>
</fancybox>
ExecutorCompletionService 有两种构造函数:
private final Executor executor;private final AbstractExecutorService aes;
private final BlockingQueue<Future<V>> completionQueue;
public ExecutorCompletionService(Executor executor) {
if (executor == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
this.completionQueue = new LinkedBlockingQueue<Future<V>>();
}
public ExecutorCompletionService(Executor executor,BlockingQueue<Future<V>> completionQueue) {
if (executor == null || completionQueue == null)
throw new NullPointerException();
this.executor = executor;
this.aes = (executor instanceof AbstractExecutorService) ?
(AbstractExecutorService) executor : null;
this.completionQueue = completionQueue;
}
两个构造函数都需要传入一个 Executor 线程池,因为是处理异步任务的,我们是不被允许手动创建线程的,所以这里要使用线程池也就很好理解了
另外一个参数是 BlockingQueue,如果不传该参数,就会默认队列为 LinkedBlockingQueue,任务执行结果就是加入到这个阻塞队列中的
所以要彻底理解 ExecutorCompletionService ,我们只需要知道一个问题的答案就可以了:
想知道这个问题的答案,那只需要看它提交任务之后都做了些什么?
public Future<V> submit(Callable<V> task) {if (task == null) throw new NullPointerException();
RunnableFuture<V> f = newTaskFor(task);
executor.execute(new QueueingFuture(f));
return f;
}
我们前面也分析过,execute 是提交 Runnable 类型的任务,本身得不到返回值,但又可以将执行结果放到阻塞队列里面,所以肯定是在 QueueingFuture 里面做了文章

从上图中看一看出,QueueingFuture 实现的接口非常多,所以说也就具备了相应的接口能力。
重中之重是,它继承了 FutureTask ,FutureTask 重写了 Runnable 的 run() 方法 (方法细节分析可以查看FutureTask源码分析 ) 文中详细说明了,无论是set() 正常结果,还是setException() 结果,都会调用 finishCompletion() 方法:
private void finishCompletion() {// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {
for (;;) {
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
// 重点 重点 重点
done();
callable = null; // to reduce footprint
}
上述方法会执行 done() 方法,而 QueueingFuture 恰巧重写了 FutureTask 的 done() 方法:
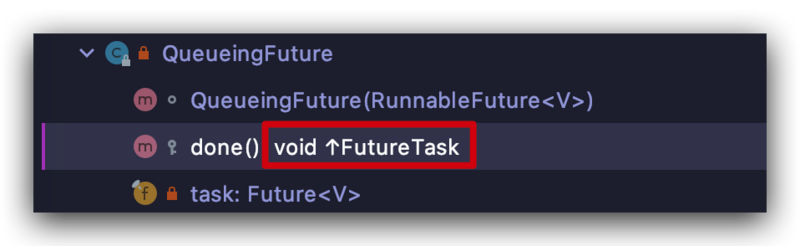
方法实现很简单,就是将 task 放到阻塞队列中
protected void done() {completionQueue.add(task);
}
执行到此的 task 已经是前序步骤 set 过结果的 task,所以就可以通过消费阻塞队列获取相应的结果了
相信到这里,CompletionService 在你面前应该没什么秘密可言了
CompletionService 的主要用途
在 JDK docs 上明确给了两个例子来说明 CompletionService 的用途:
其实就是文中开头的使用方式
void solve(Executor e,Collection<Callable<Result>> solvers)
throws InterruptedException, ExecutionException {
CompletionService<Result> ecs
= new ExecutorCompletionService<Result>(e);
for (Callable<Result> s : solvers)
ecs.submit(s);
int n = solvers.size();
for (int i = 0; i < n; ++i) {
Result r = ecs.take().get();
if (r != null)
use(r);
}
}
void solve(Executor e,Collection<Callable<Result>> solvers)
throws InterruptedException {
CompletionService<Result> ecs
= new ExecutorCompletionService<Result>(e);
int n = solvers.size();
List<Future<Result>> futures
= new ArrayList<Future<Result>>(n);
Result result = null;
try {
for (Callable<Result> s : solvers)
futures.add(ecs.submit(s));
for (int i = 0; i < n; ++i) {
try {
Result r = ecs.take().get();
if (r != null) {
result = r;
break;
}
} catch (ExecutionException ignore) {}
}
}
finally {
for (Future<Result> f : futures)
// 注意这里的参数给的是 true,详解同样在前序 Future 源码分析文章中
f.cancel(true);
}
if (result != null)
use(result);
}
这两种方式都是非常经典的 CompletionService 使用 范式 ,请大家仔细品味每一行代码的用意
范式没有说明 Executor 的使用,使用 ExecutorCompletionService,需要自己创建线程池,看上去虽然有些麻烦,但好处是你可以让多个 ExecutorCompletionService 的线程池隔离,这种隔离性能避免几个特别耗时的任务拖垮整个应用的风险 (这也是我们反复说过多次的,不要所有业务共用一个线程池)
总结
CompletionService 的应用场景还是非常多的,比如
- Dubbo 中的 Forking Cluster
- 多仓库文件/镜像下载(从最近的服务中心下载后终止其他下载过程)
- 多服务调用(天气预报服务,最先获取到的结果)
CompletionService 不但能满足获取最快结果,还能起到一定 "load balancer" 作用,获取可用服务的结果,使用也非常简单, 只需要遵循范式即可
并发系列 讲了这么多,分析源码的过程也碰到各种队列,接下来我们就看看那些让人眼花缭乱的队列
灵魂追问
- 通常处理结果还会用异步方式进行处理,如果采用这种方式,有哪些注意事项?
- 如果是你,你会选择使用无界队列吗?为什么?
日拱一兵 | 原创
以上是 “既生 ExecutorService, 何生 CompletionService?” 的全部内容, 来源链接: utcz.com/a/47605.html