RabbitMQ高级之如何保证消息可靠性?
楔子
本篇是消息队列RabbitMQ的第四弹。
RabbitMQ我已经写了三篇了,基础的收发消息和基础的概念我都已经写了,学任何东西都是这样,先基础的上手能用,然后遇到问题再去解决,无法理解就去深入源码,随着时间的积累对这一门技术的理解也会随之提高。
基础操作已经熟练后,相信大家不可避免的会生出向那更高处攀登的心来,今天我就罗列一些RabbitMQ比较高级的用法,有些用得到有些用不上,但是一定要有所了解,因为大部分情况我们都是面向面试学习~
- 如何保证消息的可靠性?
- 消息队列如何进行限流?
如何设置延时队列进行延时消费?
祝有好收获,先赞后看,快乐无限。
本文代码: 码云地址 GitHub地址
1. 📖如何保证消息的可靠性?

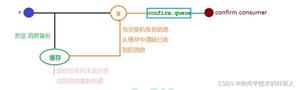
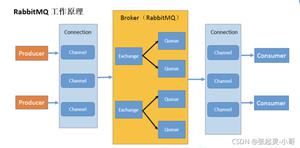
先来看看我们的万年老图,从图上我们大概可以看出来一个消息会经历四个节点,只有保证这四个节点的可靠性才能保证整个系统的可靠性。
- 生产者发出后保证到达了MQ。
- MQ收到消息保证分发到了消息对应的Exchange。
- Exchange分发消息入队之后保证消息的持久性。
- 消费者收到消息之后保证消息的正确消费。
经历了这四个保证,我们才能保证消息的可靠性,从而保证消息不会丢失。
2. 🔍生产者发送消息到MQ失败
我们的生产者发送消息之后可能由于网络闪断等各种原因导致我们的消息并没有发送到MQ之中,但是这个时候我们生产端又不知道我们的消息没有发出去,这就会造成消息的丢失。
为了解决这个问题,RabbitMQ引入了事务机制和发送方确认机制(publisher confirm),由于事务机制过于耗费性能所以一般不用,这里我着重讲述发送方确认机制。
这个机制很好理解,就是消息发送到MQ那端之后,MQ会回一个确认收到的消息给我们。
打开此功能需要配置,接下来我来演示一下配置:
spring:rabbitmq:
addresses: 127.0.0.1
host: 5672
username: guest
password: guest
virtual-host: /
# 打开消息确认机制
publisher-confirm-type: correlated
我们只需要在配置里面打开消息确认即可(true是返回客户端,false是自动删除)。
生产者:
public void sendAndConfirm() {User user = new User();
log.info("Message content : " + user);
CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString());
rabbitTemplate.convertAndSend(Producer.QUEUE_NAME,user,correlationData);
log.info("消息发送完毕。");
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback(){
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
log.info("CorrelationData content : " + correlationData);
log.info("Ack status : " + ack);
log.info("Cause content : " + cause);
if(ack){
log.info("消息成功发送,订单入库,更改订单状态");
}else{
log.info("消息发送失败:"+correlationData+", 出现异常:"+cause);
}
}
});
}
生产者代码里我们看到又多了一个参数:CorrelationData,这个参数是用来做消息的唯一标识,同时我们打开消息确认之后需要对rabbitTemplate多设置一个setConfirmCallback,参数是一个匿名类,我们消息确认成功or失败之后的处理就是写在这个匿名类里面。
比如一条订单消息,当消息确认到达MQ确认之后再行入库或者修改订单的节点状态,如果消息没有成功到达MQ可以进行一次记录或者将订单状态修改。
Tip:消息确认失败不只有消息没发过去会触发,消息发过去但是找不到对应的Exchange,也会触发。
3. 📔MQ接收失败或者路由失败
生产者的发送消息处理好了之后,我们就可以来看看MQ端的处理,MQ可能出现两个问题:
- 消息找不到对应的Exchange。
- 找到了Exchange但是找不到对应的Queue。
这两种情况都可以用RabbitMQ提供的mandatory参数来解决,它会设置消息投递失败的策略,有两种策略:自动删除或返回到客户端。
我们既然要做可靠性,当然是设置为返回到客户端。
配置:
spring:rabbitmq:
addresses: 127.0.0.1
host: 5672
username: guest
password: guest
virtual-host: /
# 打开消息确认机制
publisher-confirm-type: correlated
# 打开消息返回
publisher-returns: true
template:
mandatory: true
我们只需要在配置里面打开消息返回即可,template.mandatory: true这一步不要少~
生产者:
public void sendAndReturn() {User user = new User();
log.info("Message content : " + user);
rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey) -> {
log.info("被退回的消息为:{}", message);
log.info("replyCode:{}", replyCode);
log.info("replyText:{}", replyText);
log.info("exchange:{}", exchange);
log.info("routingKey:{}", routingKey);
});
rabbitTemplate.convertAndSend("fail",user);
log.info("消息发送完毕。");
}
这里我们可以拿到被退回消息的所有信息,然后再进行处理,比如放到一个新的队列单独处理,路由失败一般都是配置问题了。
4. 📑消息入队之后MQ宕机
到这一步基本都是一些很小概率的问题了,比如MQ突然宕机了或者被关闭了,这种问题就必须要对消息做持久化,以便MQ重新启动之后消息还能重新恢复过来。
消息的持久化要做,但是不能只做消息的持久化,还要做队列的持久化和Exchange的持久化。
@Beanpublic DirectExchange directExchange() {
// 三个构造参数:name durable autoDelete
return new DirectExchange("directExchange", false, false);
}
@Bean
public Queue erduo() {
// 其三个参数:durable exclusive autoDelete
// 一般只设置一下持久化即可
return new Queue("erduo",true);
}
创建Exchange和队列时只要设置好持久化,发送的消息默认就是持久化消息。
设置持久化时一定要将Exchange和队列都设置上持久化:
单单只设置Exchange持久化,重启之后队列会丢失。单单只设置队列的持久化,重启之后Exchange会消失,既而消息也丢失,所以如果不两个一块设置持久化将毫无意义。
Tip: 这些都是MQ宕机引起的问题,如果出现服务器宕机或者磁盘损坏则上面的手段统统无效,必须引入镜像队列,做异地多活来抵御这种不可抗因素。
5. 📌消费者无法正常消费
最后一步会出问题的地方就在消费者端了,不过这个解决问题的方法我们之前的文章已经说过了,就是消费者的消息确认。
spring:rabbitmq:
addresses: 127.0.0.1
host: 5672
username: guest
password: guest
virtual-host: /
# 手动确认消息
listener:
simple:
acknowledge-mode: manual
打开手动消息确认之后,只要我们这条消息没有成功消费,无论中间是出现消费者宕机还是代码异常,只要连接断开之后这条信息还没有被消费那么这条消息就会被重新放入队列再次被消费。
当然这也可能会出现重复消费的情况,不过在分布式系统中幂等性是一定要做的,所以一般重复消费都会被接口的幂等给拦掉。
所谓幂等性就是:一个操作多次执行产生的结果与一次执行产生的结果一致。
幂等性相关内容不在本章讨论范围~所以我就不多做阐述了。
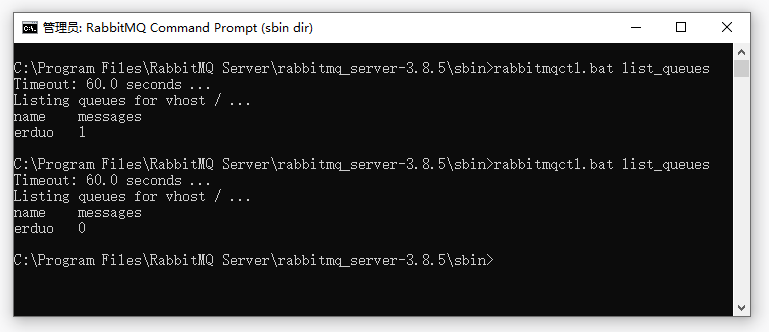
6. 💡消息可靠性案例

这个图是我很早之前画的,是为了记录当时使用RabbitMQ做消息可靠性的具体做法,这里我正好拿出来做个例子给大家看一看。
这个例子中的消息是先入库的,然后生产者从DB里面拿到数据包装成消息发给MQ,经过消费者消费之后对DB数据的状态进行更改,然后重新入库。
这中间有任何步骤失败,数据的状态都是没有更新的,这时通过一个定时任务不停的去刷库,找到有问题的数据将它重新扔到生产者那里进行重新投递。
这个方案其实和网上的很多方案大同小异,基础的可靠性保证之后,定时任务做一个兜底进行不断的扫描,力图100%可靠性。
后记
越写越长,因为篇幅缘故限流和延时队列放到下一篇了,我会尽快发出来供大家阅读,讲真,我真的不是故意多水一篇的!!!
最后再给优狐打个广告,最近掘金在GitHub上面建立了一个开源计划 - open-source,旨在收录各种好玩的好用的开源库,如果大家有想要自荐或者分享的开源库都可以参与进去,为这个开源计划做一份贡献,同时这个开源库的Start也在稳步增长中,参与进去也可以增加自己项目的曝光度,一举两得。
同时这个开源库还有一个兄弟项目 - open-source-translation,旨在招募技术文章翻译志愿者进行技术文章的翻译工作,
争做最棒开源翻译,翻译业界高质量文稿,为技术人的成长献一份力。
最近这段时间事情挺多,优狐令我八月底之前升级到三级,所以各位读者的赞对我很重要,希望大家能够高抬贵手,帮我一哈~
好了,以上就是本期的全部内容,感谢你能看到这里,欢迎对本文点赞收藏与评论,👍你们的每个点赞都是我创作的最大动力。
我是耳朵,一个一直想做知识输出的伪文艺程序员,我们下期见。
本文代码:码云地址 GitHub地址
以上是 RabbitMQ高级之如何保证消息可靠性? 的全部内容, 来源链接: utcz.com/a/47071.html